Big Data Platforms & Solutions in Cloud, Data Lake Architecture, Advanced Data Analytics, Machine Learning & AI, Data Security, MDM/Data Governance, BI & DW
🧵 Day 22/30 — #SystemDesign
Database Indexing: Why some queries take milliseconds… and others take forever
Your database works fine with 1K users.
At 1M users, the same query suddenly becomes slow.
Nothing changed in code.
The problem is how data is searched.
That’s where Indexing comes in.
An index is like a shortcut that helps the database find data quickly without scanning every row.
⸻
Without index:
→ DB scans entire table (Full Table Scan)
→ Time complexity grows with data
→ Slow queries at scale
With index:
→ DB jumps directly to required data
→ Faster reads
→ Efficient lookups
⸻
Simple Example
User table with 10M rows.
Query:
SELECT * FROM users WHERE email = ‘[email protected]’
Without index:
→ Check all 10M rows
With index on email:
→ Direct lookup in milliseconds
⸻
Why It Matters
→ Faster search queries
→ Better performance at scale
→ Reduced database load
→ Improved user experience
⸻
Tradeoff
Indexes are not free:
→ Extra storage
→ Slower writes (index update needed)
→ Too many indexes hurt performance
⸻
Golden Rule
Index what you query often.
Not everything.
#30DaysOfSystemDesign #DatabaseIndexing #BackendEngineering
Ai ENGINEERING FROM SCRATCH JUST HIT 6.3K STARS 🌟
AND... IT'S GROWING VERY FAST
490+ LESSONS from Basics to Agent Harness Engineering
https://t.co/uje5OwdXhL
Naive RAG vs. Agentic RAG, explained visually:
Naive RAG breaks in 3 ways:
↳ It retrieves once and generates once. If the context isn't relevant, the system can't search again.
↳ It treats every query the same. A simple lookup and a multi-hop reasoning task go through the identical retrieve-then-generate path.
↳ And there's no verification. Whatever the retriever returns gets blindly trusted.
Agentic RAG fixes this by introducing decision-making loops at each stage.
Steps 1-2) A query rewriting agent reformulates the raw query. This goes beyond fixing typos. It makes vague terms precise, decomposes complex queries into sub-queries, and expands abbreviations.
Steps 3-5) A routing agent decides if the query even needs external context. If not, retrieval is skipped. If yes, a source selector picks the best backend for this specific query type.
Steps 6-7) The source selector routes to the most appropriate source. Vector DB for semantic search, web search for real-time info, or structured APIs for tabular data. The retrieved context and rewritten query are combined into the prompt.
Steps 8-9) The LLM generates an initial response.
Steps 10-12) A validation agent (Corrective RAG) checks whether the response is relevant, grounded, and complete. If it passes, it's returned. If not, the system loops back to Step 1 with a reformulated query.
This continues for some iterations until we get a satisfactory response or the system admits it cannot answer.
The reason it works is that each agent acts as a quality gate. The rewriter ensures retrieval precision. The router ensures the right source is queried. The validator ensures the output is grounded.
Individual failures get caught and corrected rather than silently propagated.
That said, the diagram below shows one of many blueprints of an Agentic RAG system. Production systems increasingly combine Corrective RAG, Adaptive RAG, Self-RAG, and hybrid search (vector + lexical with reranking) based on latency budgets and accuracy requirements.
👉 Over to you: What does your Agentic RAG setup look like?
Claude Code ships with 5 architectural layers most engineers never open.
Not features. Not settings. Layers — each solving a distinct problem that LLMs alone can't solve. And four of them have nothing to do with prompting.
Here's the full Agent Development Kit:
Layer 1 — CLAUDE.md → The Memory Layer
Architecture rules, naming conventions, test expectations, repo map. Always loaded. Always active.
Two scopes:
• ~/.claude/CLAUDE.md → global
• .claude/CLAUDE.md → project
This isn't context you paste in before every session. It's context that never needs repeating. The agent's constitution.
Layer 2 — Skills → The Knowledge Layer
Each SKILL.md carries a description. Claude matches it at runtime and forks the skill into an isolated subagent. On-demand, never always-on.
Task-specific knowledge without inflating your main context window. Modular by design.
Layer 3 — Hooks → The Guardrail Layer
PreToolUse → PostToolUse → SessionStart → Stop → SubagentStop
This is the layer most teams skip. And the one they regret skipping first.
Hooks are NOT AI. They're deterministic event-driven shell commands.
• Auto-lint on every Write
• Hard-block on rm -rf
• Slack notification on Stop
Event fires → Matcher checks → Command runs
Quality enforced at the infrastructure level. Not the prompt level.
Layer 4 — Subagents → The Delegation Layer
Each subagent gets its own context window, model, tools, and permissions.
Main agent delegates down. Receives results up. That's it.
No infinite recursion — subagents can't spawn subagents. Main context stays clean. Hard boundaries by design.
Layer 5 — Plugins → The Distribution Layer
Bundle your skills + agents + hooks + commands into a plugin. One install. Whole team inherits the behavior.
Think npm packages — but for what your agent knows how to do.
Wrapping everything:
→ MCP Servers on the left (GitHub, databases, APIs, custom integrations)
→ Agent Teams on the right (parallel execution, message passing, shared permissions)
The 5-layer stack in one line:
CLAUDE.md sets rules → Skills provide expertise → Hooks enforce quality → Subagents delegate work → Plugins distribute to the team
Most production failures in agentic systems trace back to one missing layer.
Which one is the gap in your current setup?
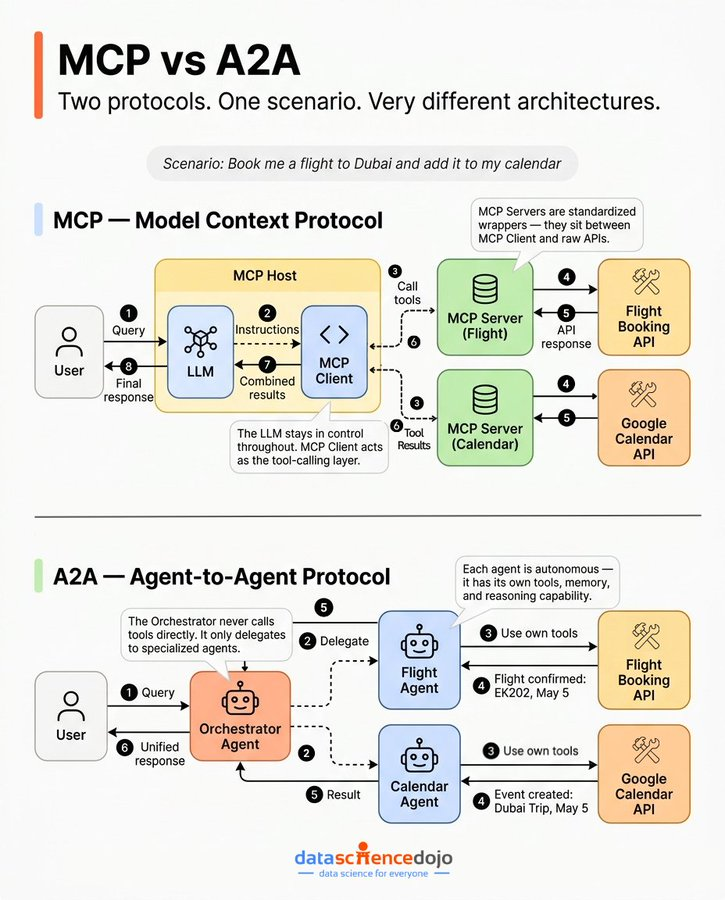
Centralized vs. Distributed. MCP for the solo genius, A2A for the dream team. This is exactly the kind of nuance AI engineers need to master right now. 🚀
6 LLM Knowledge Base terms you need to know in 2026:
(Most teams are missing at least 3, their AI agents pay the price)
𝟭. 𝗟𝗟𝗠 𝗞𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲 𝗕𝗮𝘀𝗲 A system where an LLM ingests your raw content, compiles a structured wiki, and answers questions by navigating its own index. Karpathy built one for himself. The hard part? Building one that works for your entire team.
𝟮. 𝗖𝗼𝗻𝘁𝗶𝗻𝘂𝗼𝘂𝘀 𝗜𝗻𝗴𝗲𝘀𝘁𝗶𝗼𝗻 Auto-pulls knowledge from every tool where real work happens. Slack, CRM, meetings, docs, without anyone babysitting the pipeline. A personal KB pulls from the web. A team KB has to pull from the inside.
𝟯. 𝗦𝗼𝘂𝗿𝗰𝗲 𝗧𝗿𝘂𝘀𝘁 Not all content is equal. Source Trust tells agents (and humans) what's a verified company decision vs. someone's opinion in a Slack thread. Without it, every doc carries the same weight, which means none of them really do.
𝟰. 𝗙𝗿𝗲𝘀𝗵𝗻𝗲𝘀𝘀 𝗠𝗼𝗻𝗶𝘁𝗼𝗿𝗶𝗻𝗴 Actively re-checks what the KB thinks it knows. When two sources contradict each other, it flags the conflict and demotes the staler one. It doesn't wait for someone to notice, because that's exactly the maintenance work humans defer indefinitely.
𝟱. 𝗦𝗲𝗹𝗳-𝗠𝗮𝗶𝗻𝘁𝗮𝗶𝗻𝗶𝗻𝗴 Docs update themselves as work happens. A decision on a call lands in the right doc automatically. A roadmap change propagates everywhere it needs to go. No copy-pasting. No "someone should update this."
𝟲. 𝗞𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲 𝗗𝗿𝗶𝗳𝘁 The slow, invisible gap that opens between what your docs say and what's actually true. A decision gets reversed. A process changes. A feature ships. The doc stays the same. Nobody notices, until your AI agent confidently gives someone the wrong answer. Knowledge Drift is the disease. Everything else on this list is the cure.
Which am I missing?
🤖 RAG gives LLMs access to your data. Agentic RAG gives them judgment about what to do with it.
The difference shows up in how each system handles uncertainty. Standard retrieval-augmented generation runs a fixed pipeline: encode the query, search the vector database, retrieve similar documents, generate a response. It works well when the query is well-formed and the right context already exists in one place.
Agentic RAG adds a layer of reasoning at almost every step — rewriting the query before retrieval, deciding whether the initial results are actually sufficient, choosing between multiple source types (vector DB, APIs, live web), and evaluating whether the final answer is relevant before surfacing it. If any of those checks fail, it loops back rather than proceeding.
That feedback loop is what makes it genuinely different, not just incrementally better. A standard RAG pipeline doesn't know when it's about to give a bad answer. An agentic one can at least ask the question.
If you want to understand how to design systems that reason through retrieval rather than just execute it, we cover this in depth at our Agentic AI Bootcamp starting May 5th, 2026 → https://t.co/ncYjC21wNy
#agenticai #agenticaibootcamp #aibootcamps #rag #agenticrag #aiengineering
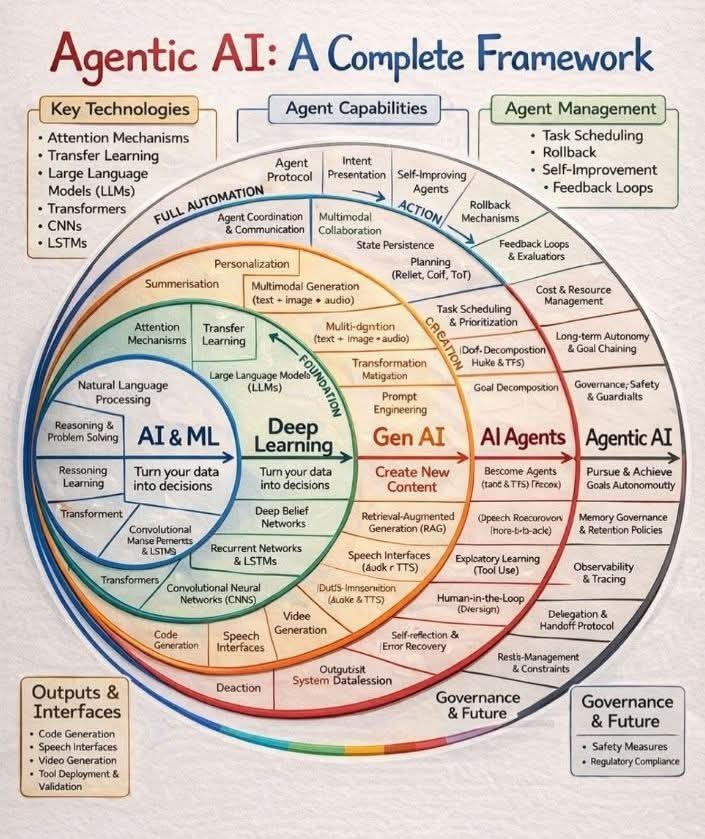
Most people don't understand what Agentic AI is.
Here's how to think about it.
Agentic AI isn't one thing.
It's the endpoint of a progression of things.
From data-driven decisions to fully autonomous systems.
Here are the 5 levels that get you there:
𝟭. 𝗔𝗜 & 𝗠𝗟 – 𝗧𝘂𝗿𝗻 𝘆𝗼𝘂𝗿 𝗱𝗮𝘁𝗮 𝗶𝗻𝘁𝗼 𝗱𝗲𝗰𝗶𝘀𝗶𝗼𝗻𝘀
𝟮. 𝗡𝗲𝘂𝗿𝗮𝗹 𝗡𝗲𝘁𝘄𝗼𝗿𝗸𝘀 – 𝗖𝗼𝗺𝗽𝗹𝗲𝘅 𝗯𝘂𝘀𝗶𝗻𝗲𝘀𝘀 𝗽𝗮𝘁𝘁𝗲𝗿𝗻 𝗱𝗲𝘁𝗲𝗰𝘁𝗶𝗼𝗻
𝟯. 𝗚𝗲𝗻 𝗔𝗜 – 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗲 𝗰𝗼𝗻𝘁𝗲𝗻𝘁 𝗮𝗻𝗱 𝗰𝗼𝗱𝗲 𝗮𝘁 𝘀𝗰𝗮𝗹𝗲
𝟰. 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀 – 𝗘𝘅𝗲𝗰𝘂𝘁𝗲 𝗰𝗼𝗺𝗽𝗹𝗲𝘅 𝘁𝗮𝘀𝗸𝘀 𝗮𝘂𝘁𝗼𝗻𝗼𝗺𝗼𝘂𝘀𝗹𝘆
𝟱. 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗔𝗜 – 𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗲 𝗲𝗻𝘁𝗶𝗿𝗲 𝗽𝗿𝗼𝗰𝗲𝘀𝘀𝗲𝘀 𝘄𝗶𝘁𝗵 𝗔𝗜
The progression matters.
You don't jump straight to Agentic AI.
You build up through each level.
Start with AI/ML. Build toward Agentic AI.
Each level unlocks the next.
#AI #ArtificialIntelligence #AISkills #AIAgents #RAG #LLM #PromptEngineering
Most people think AI = chatbot.
That’s the mistake.
Real AI doesn’t just answer…
It acts.
If you want to understand where things are going, you need to understand this:
How Agentic AI actually works 👇
━━━━━━━━━━━━━━━
AI isn’t one step.
It’s a system with layers:
### 1️⃣ Input Layer → Where intelligence begins
AI doesn’t guess out of nowhere.
It pulls from everywhere:
• user queries
• APIs
• databases
• logs
• sensors
• web data
More context = better decisions.
━━━━━━━━━━━━━━━
### 2️⃣ Processing Layer → Where thinking happens
This is what most people miss.
Agentic AI doesn’t just “respond” it thinks step-by-step:
• analyzes the query
• reasons through it
• retrieves memory
• creates a plan
• selects tools
• manages context
It’s not answering.
It’s figuring things out.
━━━━━━━━━━━━━━━
### 3️⃣ Action Layer → Where AI becomes useful
This is the real shift.
AI doesn’t stop at thinking.
It executes:
• makes decisions
• performs tasks
• collaborates with other agents
• handles errors
• improves via feedback
• schedules work autonomously
This is where AI replaces workflows, not just effort.
━━━━━━━━━━━━━━━
### 4️⃣ Output Layer → The visible part
What you see:
• responses
• results
• completed tasks
What you don’t see:
The entire system working behind it.
━━━━━━━━━━━━━━━
The big insight:
Chatbots answer.
Agentic AI systems:
→ think
→ plan
→ act
→ improve
━━━━━━━━━━━━━━━
The future of AI isn’t better prompts.
It’s better systems.
And once you understand this…
You stop building tools that talk
…and start building systems that work. 🚀
6 AI agent terms you need to know in 2026:
(Most developers still confuse #1 and #2)
𝟭. 𝗠𝗼𝗱𝗲𝗹 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗣𝗿𝗼𝘁𝗼𝗰𝗼𝗹 (𝗠𝗖𝗣)
Think of it as "USB-C for AI" - a universal standard that lets AI applications connect to external data sources and tools. Instead of building custom integrations for every tool, MCP provides one protocol that works everywhere.
𝟮. 𝗦𝗸𝗶𝗹𝗹𝘀
Basically, the agent’s job description. While MCP provides the connection and Tools provide the API, a Skill is the higher-level logic that orchestrates them. It encapsulates the domain-specific reasoning needed to turn a raw tool into a finished outcome.
Learn more about Agent Skills in our latest blog post: https://t.co/HAot10Wr1w
𝟯. 𝗦𝗶𝗻𝗴𝗹𝗲 𝗔𝗴𝗲𝗻𝘁 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲
One agent handles the entire pipeline - from understanding the task to planning steps, using tools, and generating responses. It's the simplest form of agentic system where one LLM orchestrates everything.
𝟰. 𝗠𝘂𝗹𝘁𝗶-𝗔𝗴𝗲𝗻𝘁 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲
Multiple specialized agents work together, each handling different parts of a task. One might retrieve information, another validates it, and a third generates the final response. This creates more robust and capable systems.
𝟱. 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚
An AI agent-based implementation of RAG that goes beyond simple retrieval. The agent can route queries to specialized knowledge sources, validate retrieved context, and make dynamic decisions about what information to use.
𝟲. 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆
Agents use two types of memory:
• Short-term: Stored in the context window for immediate use
• Long-term: Retrieved on demand from external storage (like vector databases)
This memory layer helps agents maintain context across interactions and learn from past experiences.
Which am I missing? 🤔
CPU vs GPU vs TPU vs NPU vs LPU, explained visually:
5 hardware architectures power AI today.
Each one makes a fundamentally different tradeoff between flexibility, parallelism, and memory access.
> CPU
It is built for general-purpose computing. A few powerful cores handle complex logic, branching, and system-level tasks.
It has deep cache hierarchies and off-chip main memory (DRAM). It's great for operating systems, databases, and decision-heavy code, but not that great for repetitive math like matrix multiplications.
> GPU
Instead of a few powerful cores, GPUs spread work across thousands of smaller cores that all execute the same instruction on different data.
This is why GPUs dominate AI training. The parallelism maps directly to the kind of math neural networks need.
> TPU
They go one step further with specialization.
The core compute unit is a grid of multiply-accumulate (MAC) units where data flows through in a wave pattern.
Weights enter from one side, activations from the other, and partial results propagate without going back to memory each time.
The entire execution is compiler-controlled, not hardware-scheduled. Google designed TPUs specifically for neural network workloads.
> NPU
This is an edge-optimized variant.
The architecture is built around a Neural Compute Engine packed with MAC arrays and on-chip SRAM, but instead of high-bandwidth memory (HBM), NPUs use low-power system memory.
The design goal is to run inference at single-digit watt power budgets, like smartphones, wearables, and IoT devices.
Apple Neural Engine and Intel's NPU follow this pattern.
> LPU (Language Processing Unit)
This is the newest entrant, by Groq.
The architecture removes off-chip memory from the critical path entirely. All weight storage lives in on-chip SRAM.
Execution is fully deterministic and compiler-scheduled, which means zero cache misses and zero runtime scheduling overhead.
The tradeoff is that it provides limited memory per chip, which means you need hundreds of chips linked together to serve a single large model. But the latency advantage is real.
AI compute has evolved from general-purpose flexibility (CPU) to extreme specialization (LPU). Each step trades some level of generality for efficiency.
The visual below maps the internal architecture of all five side by side, and it was inspired by ByteByteGo's post on CPU vs GPU vs TPU. I expanded it to include two more architectures that are becoming central to AI inference today.
👉 Over to you: Which of these 5 have you actually worked with or deployed on?
____
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
How Does Memory Work in AI Agents?
Memory enables AI agents to remember, learn, and adapt - allowing them to maintain context, recall past data, and improve over time.
It allows them to remember interactions, recall past data, and improve continuously - just like humans.
1. Short-Term Memory (Working Memory) - Stores temporary context during a session to maintain smooth, real-time interactions before clearing after the task ends.
2. Long-Term Memory - Saves important knowledge permanently, retrieves it when needed, and links related experiences for continuous learning.
3. Context Recall - Brings back relevant past information to make responses context-aware and maintain conversation continuity.
4. Retrieval & Learning Loop - Reviews previous outcomes, refines behavior, and updates internal knowledge to grow smarter over time.
AI memory combines temporary context and long-term learning to create adaptive, intelligent, and self-improving agents.
Build AI systems that remember, reflect, and evolve because true intelligence comes from learning continuously.