If you want to truly understand the value behind $SERV and why billions are destined, you won’t find a better write up than my friend’s @iamfakeguru
🔥🔥🔥 $SERV 🔥🔥🔥
ethereum:0x40e3d1a4b2c47d9aa61261f5606136ef73e28042 101 Thesis
If you're wondering why @openservai started moving, start here.
The market is not just buying "an AI coin." It is only just starting to realise what SERV actually is: agent infrastructure for Fortune 500 enterprises and global governments, already used in production with UAE gov.
Independent benchmarks from early Private Beta of SERV Reasoning engine just landed, and they look insane: as high as 107x better performance per dollar vs frontier models.
People are beginning to see what's happening here. Billions of agents are about to run the global economy. They need infrastructure that actually works.
---
TLDR
Most agent projects are still wrappers. They can talk, tweet, call some APIs, maybe run a cute workflow. But the hard problems in any serious deployment are agent reliability, cost and auditability.
They deliver slop at scale - if an agent is 95% accurate per step, a 100-step workflow only succeeds ~0.6% of the time.
Thats fine for demos, but dogshit for finance, healthcare, public sector, compliance, or any regulated workflow where money and accountability are involved.
OpenServ is attacking that bottleneck with SERV Reasoning, and the insane benchmarks from early private beta, with proof of the tech working are why the market is beginning to wake up.
---
The Problems: agents break, cost a lot, and you can't trace or verify their decisions.
The AI market spent years obsessing over model IQ. Bigger model -> better benchmark -> nicer chatbot.
But production agents, when used in any real environment, do not fail because they cannot write a clever paragraph. They fail because they drift, hallucinate, burn tokens, lose state, take wrong branches, and then build on their own mistakes over and over again.
More intelligence helps, but it does not fix the architecture. It also multiplies the cost, as 'thinking' models simply burn more tokens. Meanwhile, enterprises and governments need agents that can finish the job thousands of times, cheaply, with enough proof that a serious buyer can check and trust what happened.
The data is brutal: Dataiku report says 87% corporations want to deploy agents while McKinsey shows that 80% of enterprise AI displays super risky/unpredictable behaviour. That gap creates a massive opportunity.
Globally, developers spend $300- 500M per week on LLM compute - large enterprises represent a meaningful slice of that. And yet, most of these calls end up being useless AI slop, not fitting for serious deployments.
---
The Solution: SERV Reasoning
OpenServ has been building around these exact pain points since early 2023, before agent coins were even a clean category.
At its core sits its proprietary agent reasoning engine, built by a team with NVIDIA, Amazon AI, and 20+ years of ML systems experience.
Besides the reasoning engine, the platform offers an end-to-end solution for autonomous agents: no-code workflow builder, agent SDK, tokenisation rails, post-launch ops with the AI Co founder stack, coordination, memory, comms, handoffs.
Basically: an entire operating system for autonomous agents.
---
How SERV Reasoning Works
Instead of letting a model freestyle through chain-of-thought and hope for the best, SERV pushes reasoning through structured graphs.
Bounded paths. Defined branches. An extra verification layer around what the agent actually did. Sharded graphs surfacing inference traces.
In plain English: less token waste, fewer weird detours, outputs that stay more consistent when the stakes are real, plus the ability to trace back agent decisions.
This is not just raw inference. Inference platforms sell API calls that simply burn your money to predict the next word. OpenServ is trying to sell reliability per dollar: can the agent finish the job correctly, cheaply, and with enough proof for enterprise buyers to trust it?
Under the hood, the pitch is developer-simple: it's a single-line swap to plug SERV into existing OpenAI/Anthropic-style flows and use the reasoning engine.
---
Where We Are Now: Private Beta Receipts
The recent repricing started because private beta receipts are already proving it works extremely well. Check recent posts by OpenServ to find specific proof points, like this article: https://t.co/hS1e9r92Ql
ThoughtProof, which works on agent verification for banking, compliance and onchain settlement, ran SERV against its production stack. They reported 107x performance per dollar vs baseline, with zero failed calls on a 120-case PLV faithfulness eval.
Then ICM Analytics switched its market intel stack to SERV Reasoning. They instantly saw 16x faster inference, 9x better efficiency, and more signals surfaced across revenue, P/E and adoption tracking.
Then Neol - their agents reached 100% reliability with SERV Reasoning, now live in production with the UAE government.
That last one is the part I think people are still heavily underweighting. Crypto is used to "partnerships" that mean a logo on a website. This is different: reasoning infrastructure in government-grade workflows.
Are you beginning to understand it yet?
---
The Kill Shot: Privacy AI for Regulated Environments
OpenServ recently announced it is shipping TEE-backed inference with cryptographic attestations: sealed memory, signed execution proofs, verifiable model integrity and private inference for regulated users.
Translation: if AI is going into healthcare, finance, public sector or compliance, "trust me bro" is not enough to run customer / patient / citizen data through it.
You need to prove that the data doesn't leak anywhere, how it ran, where it ran, and whether the model/data path can be trusted.
This is exactly the profile OpenServ is chasing: serious institutions with real data, real risk, and no tolerance for black-box agent chaos.
---
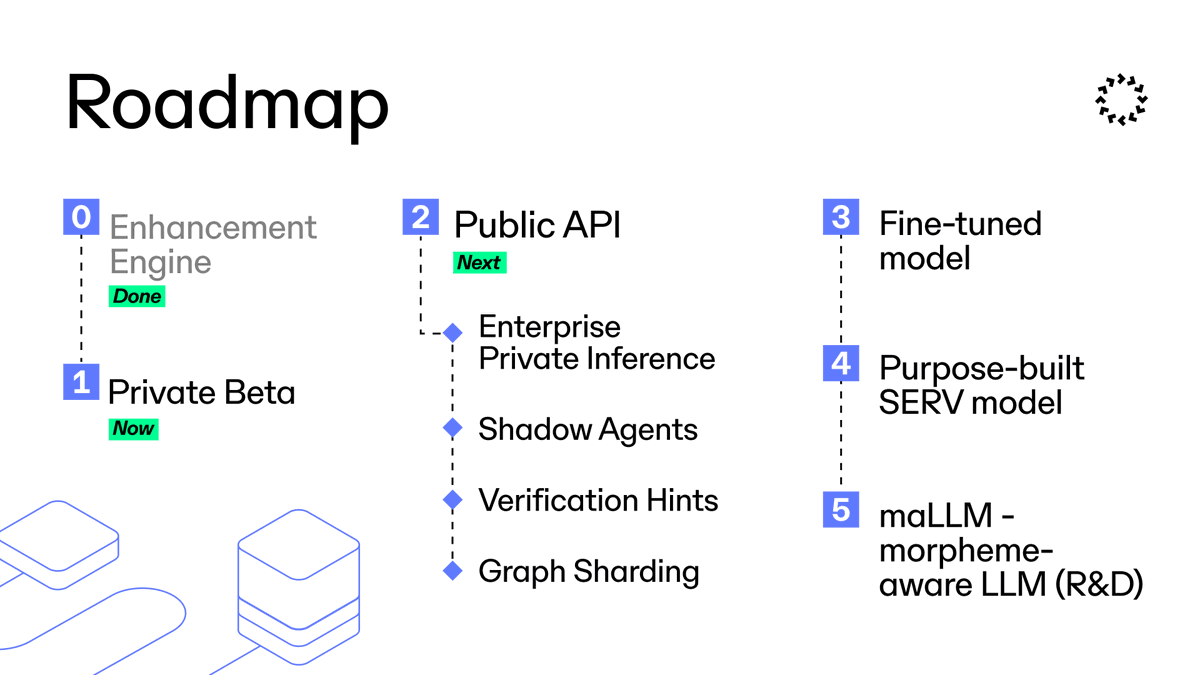
Roadmap: Whats next?
P0: enhancement engine ✅ (done)
P1: private beta (👈 YOU ARE HERE)
P2: public API (next)
enterprise private inference
shadow agents
verification hints
graph sharding
P3: SERV-native fine-tuned models
P4: purpose-built SERV model
P5: maLLM R&D
---
The Team
Greg Ivanov just joined as key advisor: Ex-Head of Partnerships at Google who helped scale Google Play into one of the biggest developer ecosystems on earth.
The broader OpenServ bench includes AI/SaaS, CTO with 20+ years in machine learning, NVIDIA PhD researcher, Amazon AI product lead, JPM finance veterans, TRON/TON/Stellar marketing pros and distributed systems people.
It's an AAA team assembled for targeting developers, enterprises, crypto founders and government-grade workflows. Show me another crypto team with this level of experience and network tier.
---
The Tokenomics
25% of platform rev → buyback and burn.
Three main flows feed it:
1) Enterprise contracts and API usage. The heavy hitter.
2) SERV Build - developers shipping agents that run reasoning calls. Every call, more revenue, more burn.
3) SERV Launch - permissionless tokenization layer. Every TGE, every fee, all routes back to main token.
Now get this: as mentioned earlier, developers globally spend $300- 500M per week on LLM compute (and the trend is only accelerating). SERV is the cheaper, auditable layer underneath that curve - every dollar that flows through it burns the token.
Then, we have the L3 SERV-native agentic blockchain catalyst which is a bit further out. It's when reasoning moves on-chain, and every API call settles in directly as the gas of the agent economy.
When that ships, every agent inference in the network is burning the token, permanently.
At the time of writing, SERV is still under 100M which is honestly bizarrely undervalued.
For agent reasoning/orchestration infra serving governments, that is a drop in the ocean. The comp people keep reaching for is $Virtual, which became a multibillion-dollar agent launchpad. $VVV crossed a billion fdv on private inference alone.
But OpenServ's pitch is far broader: not just 'launch a memecoin and call it an agent' or 'talk to a chatbot privately' - but build production agents, fund them, operate your agents on autopilot, coordinate them, and upgrade the reasoning layer underneath to production-grade.
It's a multibillion-dollar monster in the making.
---
The Thesis:
1. Agent reliability is broken and the cost is prohibitive
2. SERV Reasoning attacks that bottleneck
3. Private beta receipts already prove that it works
4. Privacy/auditability opens enterprise/government
5. Base + Solana gives crypto distribution
6. Valuation is tiny vs the category its in
The market does not need every part of the roadmap finished to reprice this. It just needs to see that OpenServ has a real shot at becoming the reasoning and orchestration layer for autonomous businesses, Fortune 500 enterprises and governments.
---
And THAT, dear sir,
is why is beginning to move.
---
Btw, team is very active with the community on TG and often drops fresh alpha there.
Join here to frontrun ecosystem news: https://t.co/JSXD7bx9Ke
Been saying this since launch. $SERV is not playin around. Enough gambling on meme tokens fellas, or buying the next cabal call…follow the brains, follow the narrative, follow the money.
Tim @open_founder and team have been laser focused and consistent since day one. Others have larped while these guys have built, adapted, expanded.
As I said before, this is the one bag you can buy, kick back and relax, and revisit for retirement.
🔥🔥🔥 $SERV 🔥🔥🔥
Next Phase: Privacy AI
Privacy is the trillion-dollar gate to enterprise AI.
We are kicking it open with full agent-inference auditability, already live with the UAE government.
End-to-end encryption ships next.
Batch 2 of the invite-only Beta rolling out now, hundreds on the waitlist.
From here, it compounds.
Public API. Private inference for enterprises and governments. Then our own SERV-native models.
Full stack below.
SERV Reasoning ROADMAP:
P0: Enhancement Engine (done)
P1: Private Beta (now)
P2: Public API (next)
2.1 Enterprise Private Inference (TEE + E2EE)
2.2 Shadow Agents
2.3 Verification Hints
2.4 Graph Sharding
P3: SERV-native fine-tuned models
P4: Purpose-built SERV model from scratch
P5: maLLM - morpheme-aware LLM (R&D)
Detailed article coming.
@MANULSUPERFAN Yessir, I was born and raised there, nothing like it in the US. Also, Dearborn Heights next door. Both cities have Muslim mayors, good guys too.