Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API.
Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls.
Try it: https://t.co/hhO6qTawgb 🐡
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
We’re reimagining a 50-year-old interface - the mouse pointer - with AI. 🖱️
These experimental demos show how people can intuitively direct Gemini on their screens using motion, speech, and natural shorthand to get things done 🧵
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
🗨️ "Sale génocidaire", "tu tues les Palestiniens" : Emma raconte sa scolarité dans un lycée public du Val-de-Marne, en tant qu'élève identifiée comme juive.
"Ce qui m'a le plus marquée, c'est les croix gammées dessinées sur mes tables".
Témoignage recueilli avec l'aide de l'@ULJF_officiel.⤵️
New art project.
Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.
https://t.co/HmiRrQugnP
This free CUDA course is worth more than most CS degrees.
12 hours that separate library users from GPU engineers.
I watched senior devs struggle with concepts taught in hour 3.
What makes it different:
No hand-waving. No "just use this library."
You build an MLP trainer FOUR times: → PyTorch (the easy way) → NumPy (getting harder) → C (now we're cooking) → CUDA (chef's kiss)
Same model. Same dataset. Four implementations.
By the end, you understand WHY PyTorch is fast.
The curriculum nobody else teaches:
➡️ GPU architecture (not just "it's parallel")
➡️ Writing kernels that don't suck
➡️ Profiling at kernel AND system level
➡️ When cuBLAS helps (and when it doesn't)
➡️ CUDA vs Triton (the comparison you need)
➡️ PyTorch extensions (actually useful ones)
Real talk:
➡️ After this course, you'll read PyTorch source code and understand it.
➡️ You'll optimize models other engineers can't touch.
➡️ You'll be the person teams hire to make things fast.
Created by @elliotarledge 💪
12 hours. Free. No excuses.
Who's starting this weekend?
(I will put the details in the comments.)
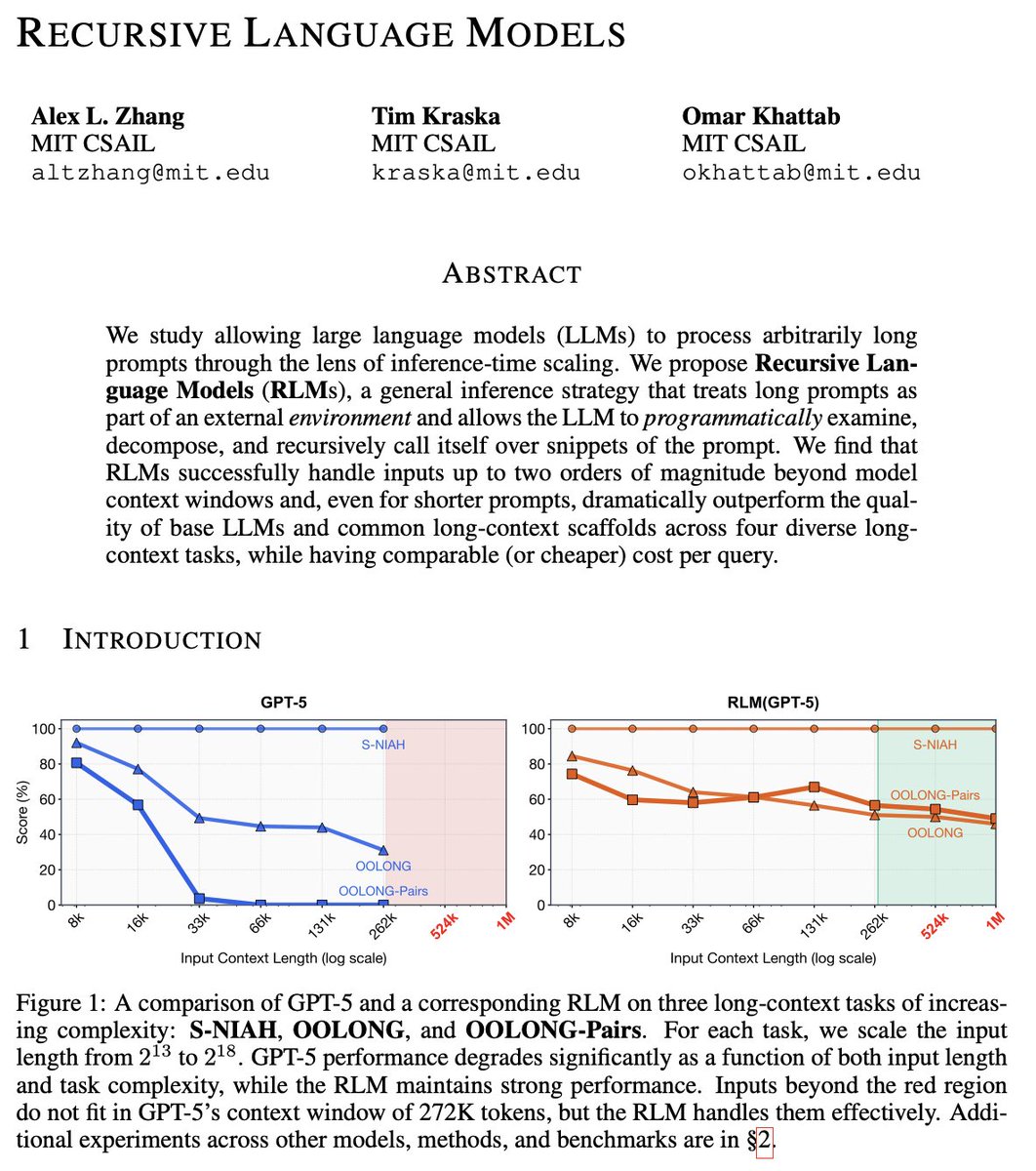
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
https://t.co/x47pIfIkTb