1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
Got a request from a professor wanting to cite my Zhihu new year blogpost in his paper, about my theory of "Fermi Level" for human society due to AI impact.
So I translate it, together with building a personal blogpost site.
https://t.co/0ruCo961W9
It only takes a few hours to nail down all the details, and it is only one of the concurrent workstreams. AI coding agents are just incredible nowadays!
Our team at Meta Superintelligence Labs is looking for summer research scientist interns to help shape the future of multimodal intelligence. Topics include multimodal reasoning, agents, and unified understanding & generation models.
https://t.co/Ln3DmFCcQj
Agentic behavior will be the key to Super Intelligence, acting over long horizons to solve extremely complex problems. 🚀
We’re pleased to introduce a scalable synthetic environment that enables rich, diverse, and reward-dense RL training — ushering in the new age of experience.
Scaling Agent Learning via Experience Synthesis
📝: https://t.co/Hx39FHe3Am
Scaling training environments for RL by simulating them with reasoning LLMs!
Environment models + Replay-buffer + New tasks = cheap RL for any environments!
- Strong improvements over non-RL-ready environments and multiple model families!
- Works better in sim-2-real RL settings → Warm-start for high-cost environments
🧵1/7
Very nice blog post from Thinky (@_kevinlu et al) about on-policy distillation for LLMs -- we published this idea back in 2023 and it is *publicly* known to be successfully applied to Gemma 2 & 3, and Qwen3-Thinking (and probably many closed frontier models)!
The idea behind on-policy distillation is simple: Generate tokens from student, label each token position with teacher logprobs for entire vocab, and train student to match teacher logprobs.
When I describe it to people, the main analogy I give is about a student learning how to drive with a teacher (very inspired from DAGGER iykyk).
- Supervised distillation (e.g., SFT on reasoning traces) is akin to observing the teacher drive the car and trying to mimic their actions.
- On-policy distillation is analogous to the student taking the driver's seat and teacher telling them what they'd do for all situations.
I think most would agree that the on-policy approach is the better way to learn -- if the student is doing something wrong, the teacher would immediately tell the student to do something else. I have also given a tutorial on post-training distillation at DeeMind covering why we care about distillation and the major approaches: https://t.co/5ecxeCfZkz
The OG method is from 2023, so there are simple changes that can be done to make this much better (especially in terms of compute or memory efficiency)! We have also done a bunch of follow-up work where we combine speculative decoding with on-policy distillation to both improve spec decoding and distillation itself: https://t.co/psyZMX7t7g
The OG paper work happened due to a collaboration with @OlivierBachem and @nino_vieillard, who further pushed this direction for Gemma models! Another person to follow related to LLM distillation is @charlinelelan, who led the work on Gemini Flash.
What if your LLM inference automatically got faster the more you used it?
Introducing ATLAS from the Together AI Turbo research team.
Read more: https://t.co/ASRNUpqoAE
Here’s Together AI Founder and Chief Scientist @tri_dao introducing ATLAS:
Agent Learning via Early Experience
The paper introduces the “early experience” paradigm for training autonomous language agents, which enables them to generate their own interaction data for improved learning and generalization, effectively bridging imitation and reinforcement learning without relying on external rewards.
Kai Zhang, Xiangchao Chen, Bo Liu @cranialxix , Tianci Xue @xue_tianci , Zeyi Liao @LiaoZeyi , Zhihan Liu, Xiyao Wang @XiyaoWang10 , Yuting Ning @yuting_ning , Zhaorun Chen @ZRChen_AISafety , Xiaohan Fu, Jian Xie @jianxie_ , Yuxuan Sun, Boyu Gou @BoyuGouNLP , Qi Qi, Zihang Meng @ZihangM , Jianwei Yang @jw2yang4ai , Ning Zhang, Xian Li, Ashish Shah, Dat Huynh @DatHuynh13 , Hengduo Li @HengduoL68478 , Zi Yang, Sara Cao, Lawrence Jang @JangLawrenceK , Shuyan Zhou @shuyanzhxyc , Jiacheng Zhu @JiachengZhu_ML , Huan Sun @hhsun1 , Jason Weston @jaseweston , Yu Su @ysu_nlp , Yifan Wu @yifannnwu
Meta Superintelligence Labs; FAIR at Meta; The Ohio State University
https://t.co/cPBlMRedJq
I spent the past month reimplementing DeepMind’s Genie 3 world model from scratch
Ended up making TinyWorlds, a 3M parameter world model capable of generating playable game environments
demo below + everything I learned in thread (full repo at the end)👇🏼
The most important skill for a researcher is not technical ability. It's taste. The ability to identify interesting and tractable problems, and recognize important ideas when they show up.
This can't be taught directly. It's cultivated through curiosity and broad reading.
Very excited to share that an advanced version of Gemini Deep Think is the first to have achieved gold-medal level in the International Mathematical Olympiad! 🏆, solving five out of six problems perfectly, as verified by the IMO organizers! It’s been a wild run to lead this effort and I am grateful to everyone in the team for such an amazing achievement! Blog post in the thread and more to share soon!
Last day today @AIatMeta, reflecting on last several months, and wanted to highlight few things I enjoyed working with:
Building new algorithms for on policy distillation with @DatHuynh13
Science of end to end thinking models @agarwl_ and many others
Working prototype of something beyond transformers with @Happylemon56775
Newer higher order optimization and infra with @vinaysrao and many others
Helping @afrozenator with codistillation for pretraining and helping move to next arch
Pushing on the scaling RL plans with many particularly debugging entropy collapses type of bugs.
Most fun / memories are on technical work!
Llama 4 Intelligence Index Update: We have now replicated Meta’s claimed values for MMLU Pro and GPQA Diamond, pushing our Intelligence Index scores for both Scout and Maverick higher
Key update details:
➤ We noted in our first post 48 hours ago that we noticed discrepancies between our measured results and Meta’s claimed scores for our multi-choice eval datasets (MMLU Pro and GPQA Diamond)
➤ After further experiments and and close review, we have decided that in accordance with our published principle against unfairly penalizing models where they get the content of questions correct but format answers differently, we will allow Llama 4’s answer style of ‘The best answer is A’ as legitimate answer for our multi-choice evals
➤ This leads to a jump in score for both Scout and Maverick (largest for Scout) in 2/7 of the evals that make up Artificial Analysis Intelligence Index, and therefore a jump in their Intelligence Index scores
➤ Scout’s Intelligence Index has moved from 36 to 43, and Maverick’s Intelligence Index has moved from 49 to 50.
Overall, we continue to conclude that both Scout and Maverick are very impressive models and a significant contribution to the open weights AI ecosystem.
While DeepSeek V3 0324 maintains a small lead over Maverick, we continue to note that Maverick has ~half the active parameters (17B vs 37B), and ~60% of the total parameters (402B vs 671B), while also supporting image inputs.
All our tests have been performed on the Hugging Face release version of the Llama 4 weights for both Scout and Maverick, including testing via a range of third party cloud providers. None of our eval results are based on the experimental chat-tuned model provided to LMArena (Llama-4-Maverick-03-26-Experimental).
We can also share that we have observed third party cloud APIs generally stabilizing over the last 48 hours. We will soon release endpoint-level comparison data to allow developers to understand whether any cloud providers are still serving versions of Llama 4 with accuracy issues.
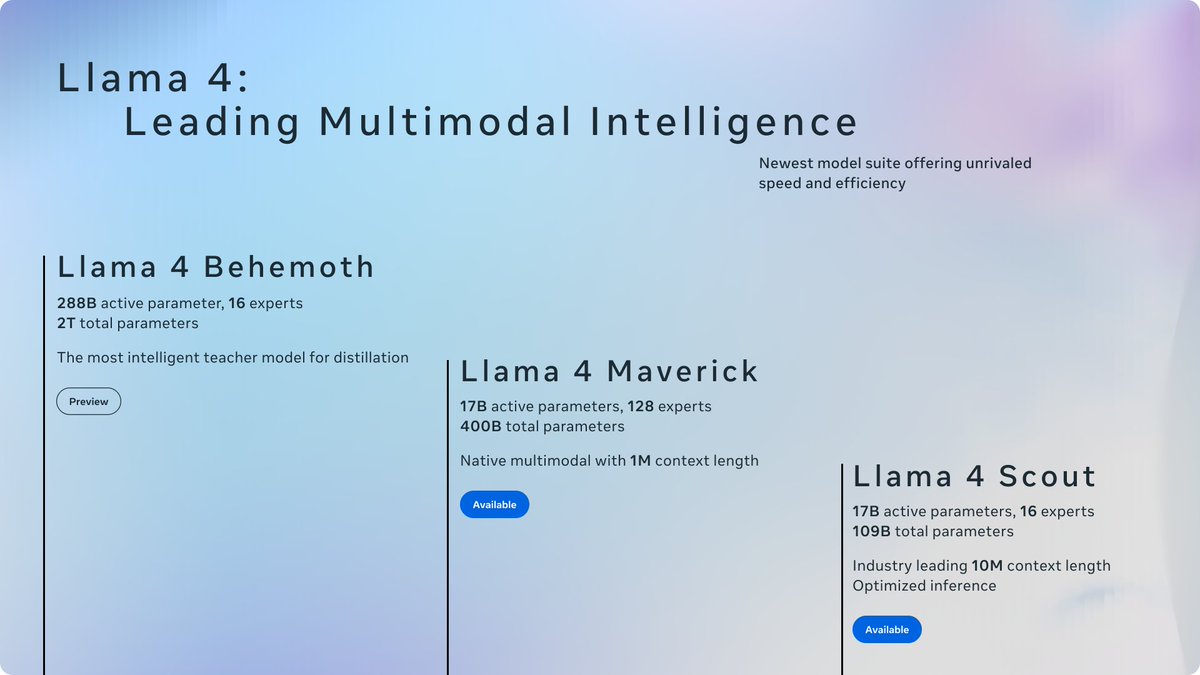
Today is the start of a new era of natively multimodal AI innovation.
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
Llama 4 Scout
• 17B-active-parameter model with 16 experts.
• Industry-leading context window of 10M tokens.
• Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.
Llama 4 Maverick
• 17B-active-parameter model with 128 experts.
• Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
• Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
• Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
• Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.
These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
Read more about the first Llama 4 models, including training and benchmarks ➡️ https://t.co/9G3QgVdCkB
Download Llama 4 ➡️ https://t.co/eVomRvEr0w
When I was a PhD student, many times I heard an unwritten consensus that goes somewhat like:
"You write 3 first-authored papers on loosely related topics, then staple them together to make your dissertation."
After staying in the industry for a while and trying to ship research that works, I find the consensus above toxic and can instill wrong mindsets for junior researchers.
First, the first-authorship definition is toxic. It incentivizes junior researchers to create projects with sufficiently small scopes so that they can first-author. These projects are very different from what they encounter in the real world, where useful products typically require multiple people, if not multiple teams, to collaborate effectively. At the closure of such projects, credit assignment is usually tricky enough that credits are assigned to groups rather than individuals. Going after first authorship completely neglects the collaboration aspect.
Case in point: how many authors are there on GPT4, Gemini, LLAMA-3? If those authors were PhD students, how many of them can use some innovations that they made in these papers for their dissertations?
Second, the "3 papers on loosely-related topics" is even more ridiculous. It creates the "paper counting" mindset, which in turn incentivize junior researchers to think short-term, like "OK, the NeurIPS deadline just passed. What can I do in 4 months to meet the ICLR deadline?" This way of thinking tells these researchers to avoid pursuing long-term directions.
Another terrible consequence of the "paper counting" mindset is that it litters all publication venues with trash submissions and creates unnecessary pressure for reviewing. This pressure, in turn, leads to trash reviews.
I am not sure if this is still the PhD standard today. If it is, I hope it changes. PhD students in maths and physics graduate with one paper, sometimes zero paper, all the time. We need to relearn doing slow science: maintain a long-term goal. Ideally, the long-term goal should go with short-term milestones, but these milestones should never compromise the goal itself.