1. (System design) - The Interaction Models see your screen and collaborates with you live. Here we're building a scalable system architecture together — no copy-pasting, no switching tabs, just thinking out loud and drawing on the screen together.
we are excited to share our latest work on interactive human-AI collaboration!
as intelligence increases, we think progress will be bottlenecked by the ability of AI to work *with* humans -- thereby enabling AI to positively impact the long tail of human experiences
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
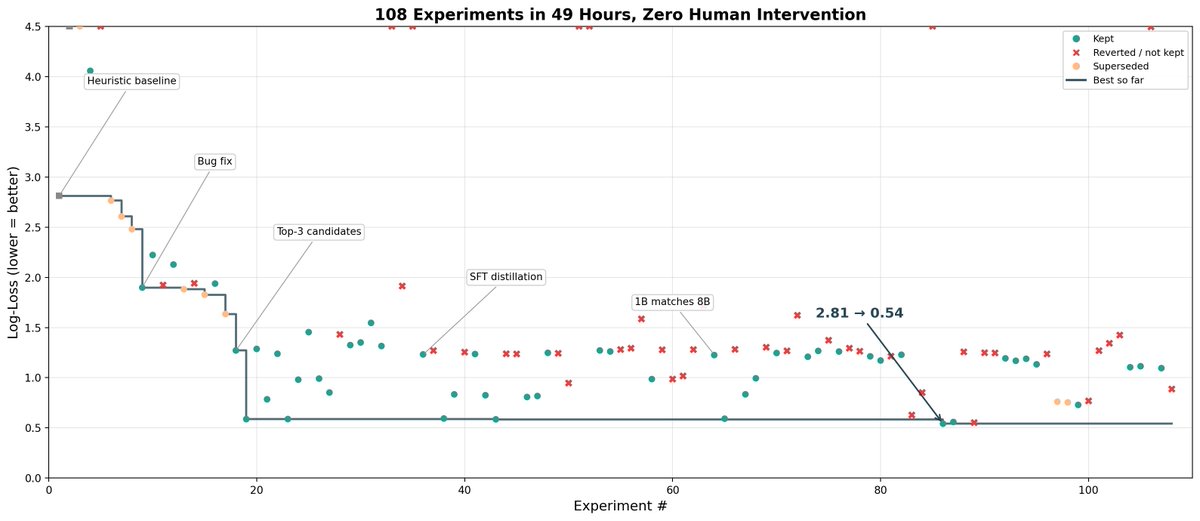
I pointed Claude Code at a research task (build a golf forecasting system) and let it run for 49 hours on Tinker. No human in the loop.
It ran 108 experiments. Here's the full trajectory, including the ones that made things worse.
There's been a lot of excitement around auto-research, but one underappreciated bottleneck: coding agents struggle to run LLM training jobs at scale. A small infrastructure mistake can have major consequences on the output.
I recently joined @thinkymachines, and @tinkerapi solves exactly this. It standardizes the training process — training a 1T parameter model is as simple as training a 4B one. That makes auto-research with coding agents like Claude Code actually viable.
Grateful to Jensen and @nvidia team for their support. Together, we’re working to deploy at least 1GW of Vera Rubin systems, bringing adaptable collaborative AI to everyone.
https://t.co/FiOL7SRbut
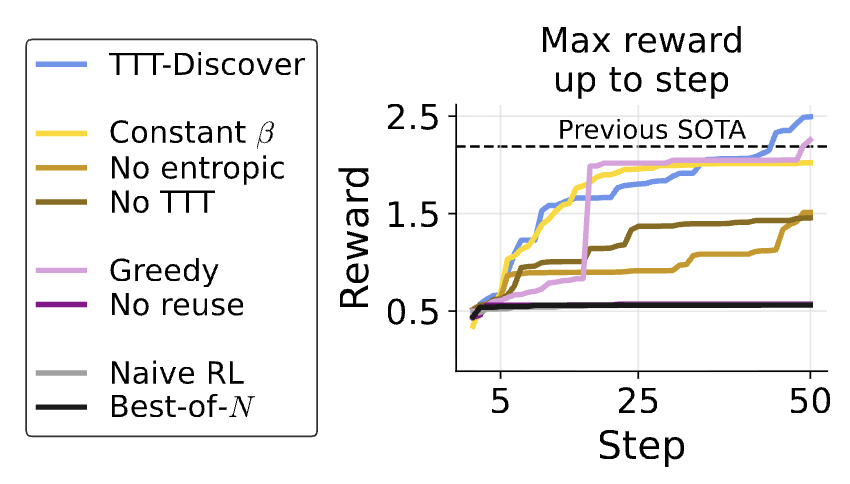
encouraging progress on continued test-time adaptation beyond model deployment!
very excited about the future of personalized models, and developing reliable, easy-to-use pipelines to enable robust & personalized intelligence
i think the "no TTT" baseline from Section 4.5 is particularly neat, justifying training with gradient steps at test time
Introducing Large Video Planner (LVP-14B) — a robot foundation model that actually generalizes. LVP is built on video gen, not VLA. As my final work at @MIT, LVP has all its eval tasks proposed by third parties as a maximum stress test, but it excels!🤗
https://t.co/wjD54YFK3k
in the past couple months of closed beta, Tinker has been used to solve Putnam, has powered our blog posts, and has been accelerating internal research!
excited to see the innovation from making trillion-parameter RL broadly available -- Tinker is a dream for multi-agent setups, personalization, and continual adaptation
Tinker is now generally available. We also added support for advanced vision input models, Kimi K2 Thinking, and a simpler way to sample from models.
https://t.co/nvaJHkGxc0
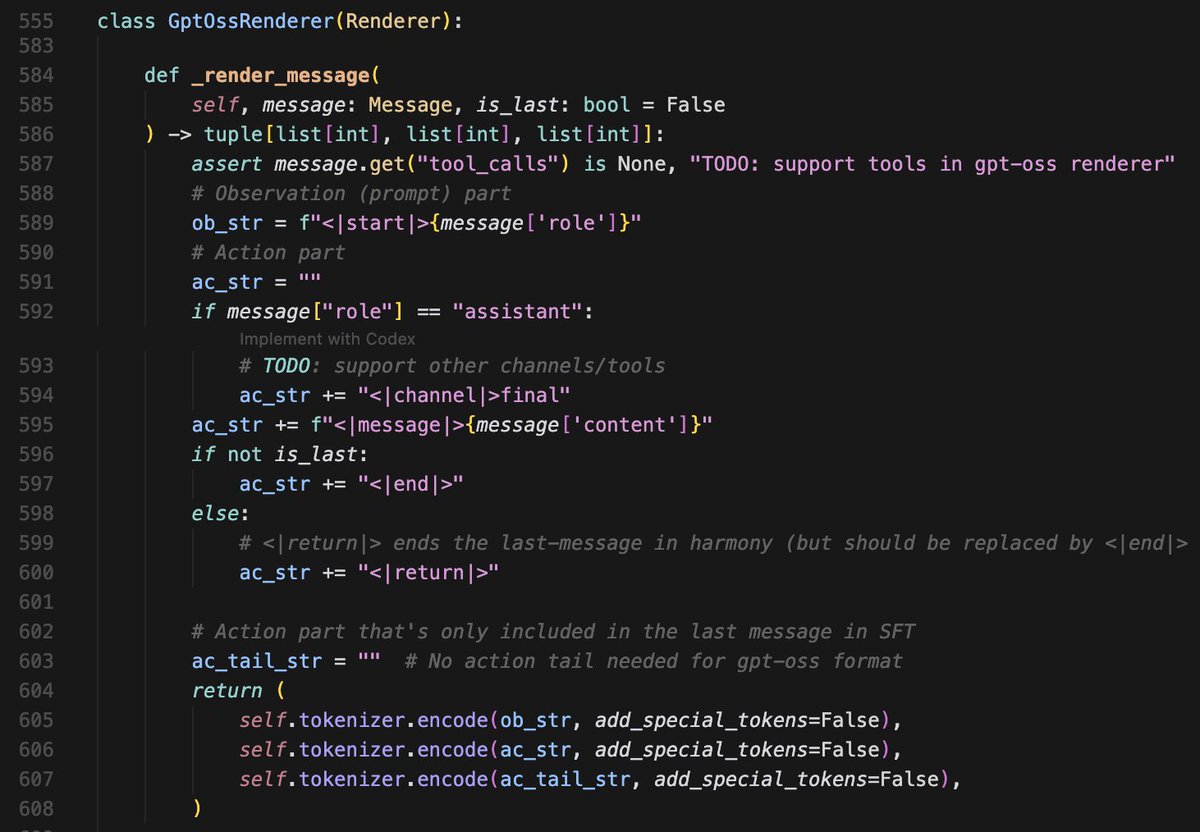
On-policy distillation would revolutionize multi-turn tool-use training beyond RL, but neither Tinker nor TRL which implements on-policy supports anything other than single-turn distillation.
We therefore have taken this upon ourselves and implemented this feature in native Tinker.
Specifically, with a trainable Tinker client, a model can now call a list of tools, interact with tool results for multiple turns, and return tokens, logprobs, and reward masks sufficient for a distillation training job (p1-2).
The engineering we have achieved is to implement tool calling and parsing for Tinker models, which lies in @thinkymachines 's TODO list in their tinker_cookbook code (p3).
Apart from that, we also create a dedicated inference stream that spins up robust, multi-turn tool loop that can run alongside a training job and sync the weights in real time. It becomes easy to write a simple training loop with KL loss to run on-policy distillation with tool use.
This opens the door for a new domain of application in agentic LLM because small/medium models now have access to dense, on-policy rewards from a swarm of SOTA large models (deepseek, gpt-oss).
We will next up begin our training runs and see how they compare with traditional RL/SFT on multi-turn tool use.
I’ll be attending #NeurIPS starting Wednesday as part of @thinkymachines!
Feel free to DM me if you’d like to catch up, chat about research, or learn more about Thinky (we have openings!)🤝
https://t.co/IjUWdrtEJj
Science is best shared! Tell us about what you’ve built or discovered with Tinker, so we can tell the world about it on our blog.
More details at https://t.co/2z5U597QZ4
We also replicate the "Distillation for personalization" results from @_kevinlu and @thinkymachines by improving the code performance of a model with SFT and then recovering it's IFEval scores with distillation.
thanks to multi-tenancy and the incredible engineering effort of the team, tinker is now both a joy to use, and super cheap!
hope to see you try it out 🙂
Starting Monday, November 3rd, Tinker is switching to a pricing plan that reflects compute usage. This will ensure we have sufficient capacity to clear our waitlist by the end of the year, allowing anyone to sign up and start Tinkering.
https://t.co/RGEEBj4VVo
thanks! i think that's probably more of a feature -- you are basically distilling uncertainty / the teacher's value function into the student in this case. insofar as the signal afterwards is less informative, i think @WendaXu2@agarwl_ & co have some interesting work: https://t.co/dCDO7m0kiZ
in our new post, we walk through great prior work from @agarwl_ & the @Alibaba_Qwen team exploring on-policy distillation using an open source recipe: you can run our experiments on Tinker today!
https://t.co/7nkW8YgT7K
i'm especially excited by the use of on-policy distillation to enable new "test-time training" personalization methods, allow the model to learn new domain knowledge without regressing on post-training capabilities
Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost.
https://t.co/JhpyWQOpBe