Our team at DeepMind is growing.
We've assembled a world class physics+material science team and are building an experimental lab.
If you want to solve real problems at the intersection of AI + material science to unlock a technological revolution - this is the place. Apply 👇
AI has the potential to compress the time needed for new discoveries from years to days. 📉
That’s why we’re supporting the US Dept. of @ENERGY's Genesis Mission – providing National Labs with access to AI tools to help accelerate research in physics, chemistry, and beyond. → https://t.co/anXO1YdEjY
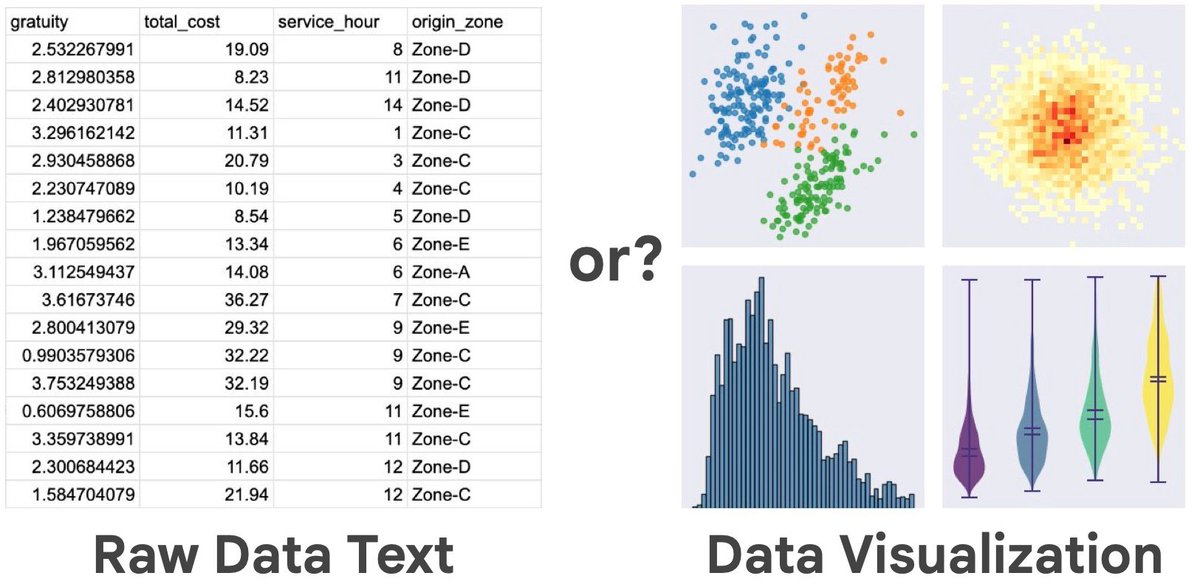
@AvivTamar1 Visualization image would lossy compress the dataset into hundreds or thousands of tokens (as qwen-vl does for example), while the original dataset could be hundreds of thousands of (lossless) text tokens. So I imagine that's the biggest difference.
Humans benefit from visualizing data. Do AI models need visualization too, or can they just take in raw data text? A fun study co-made with Claude to answer this question. Conclusion: it seems like AI currently benefits from looking at data visualizations! https://t.co/9bNALX3CK7
@AvivTamar1 I suspect because a visualization presents all data aggregated in a manner the models are used to (images), while raw data text is harder for the model to aggregate (either due to architecture, or lack of appropriate training tasks)?
Excited to be at NeurIPS in San Diego from Thursday to Saturday next week! If you want to chat about AI for accelerating science (esp. materials), multi-modality, robotics, or intersections of these things, please reach out!
Gemini Nano Banana Pro can solve exam questions *in* the exam page image. With doodles, diagrams, all that.
ChatGPT thinks these solutions are all correct except Se_2P_2 should be "diselenium diphosphide" and a spelling mistake (should be "thiocyanic acid" not "thoicyanic")
:O
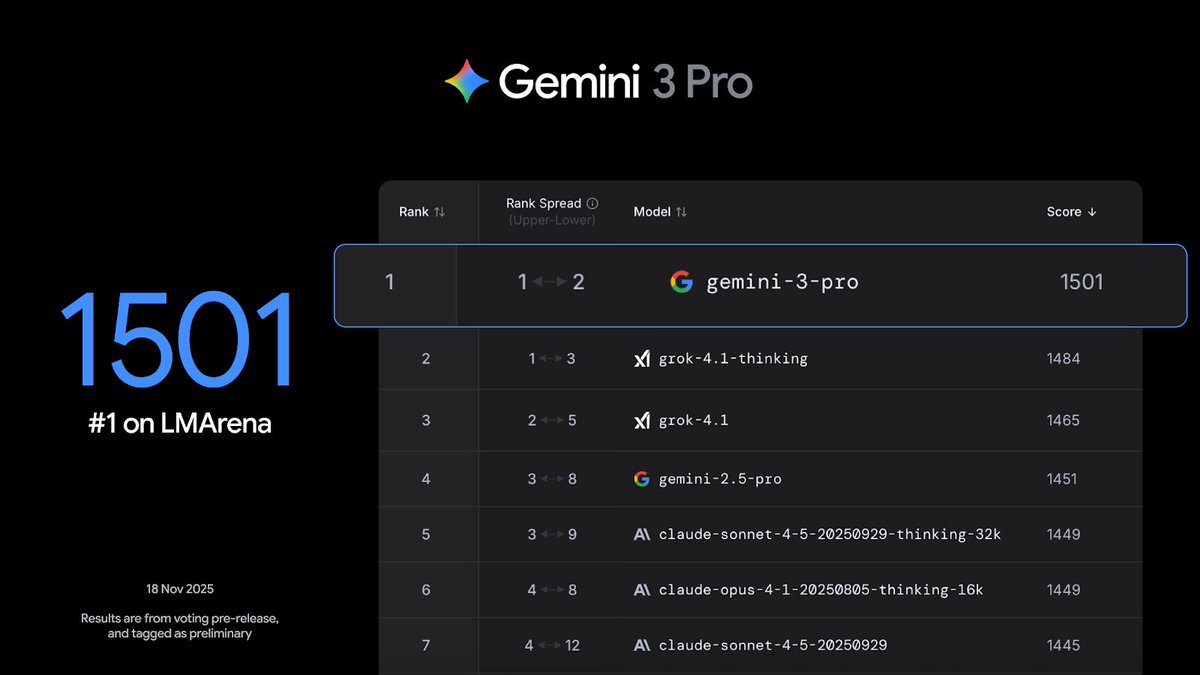
Excited that Gemini 3 is finally out! Visual perception is particularly improved in this version and I'm excited to see all the downstream effects of that.
We’ve been intensely cooking Gemini 3 for a while now, and we’re so excited and proud to share the results with you all. Of course it tops the leaderboards, including @arena, HLE, GPQA etc, but beyond the benchmarks it’s been by far my favourite model to use for its style and depth, and what it can do to help with everyday tasks.
Working on this with Claude in a single long session was really fun and very fast. What could have been a summer research project was done in a few weekend bursts on the side. I'm excited to try looking into more research questions in this manner!
See blog post for more details https://t.co/9bNALX3CK7 View and download the dataset of csv, visualizations, and questions to try it yourself here: https://t.co/xE4i7CL12w. And here is a Claude transcript for the entire project: https://t.co/JNur0HE8cg
@_kevinlu@agarwl_@Alibaba_Qwen Excellent post! +1 that on-policy distillation + continual learning is very interesting. Though with teachers that use backtracking, do you not often get pulled to first token of "...wait, that's not right" after student starts faltering (with signal after that less informative)?
Personally, I love this plot because it so crisply shows the value of active (RL) vs passive (SFT) experience for embodied agents: just 1% of active (RL) interaction gives you jump from orange to blue which you can't approach by just pouring in more passive SFT data (orange).
Super excited to finally share our work on “Self-Improving Embodied Foundation Models”!!
(Also accepted at NeurIPS 2025)
• Online on-robot Self-Improvement
• Self-predicted rewards and success detection
• Orders of magnitude sample-efficiency gains compared to SFT alone
• Generalization enables novel skill acquisition
🧵👇[1/11]























![coolboi95's tweet photo. Super excited to finally share our work on “Self-Improving Embodied Foundation Models”!!
(Also accepted at NeurIPS 2025)
• Online on-robot Self-Improvement
• Self-predicted rewards and success detection
• Orders of magnitude sample-efficiency gains compared to SFT alone
• Generalization enables novel skill acquisition
🧵👇[1/11]](https://pbs.twimg.com/media/G2rNyJ-asAAVYed.jpg)



















