Anthropic is truly unstoppable.
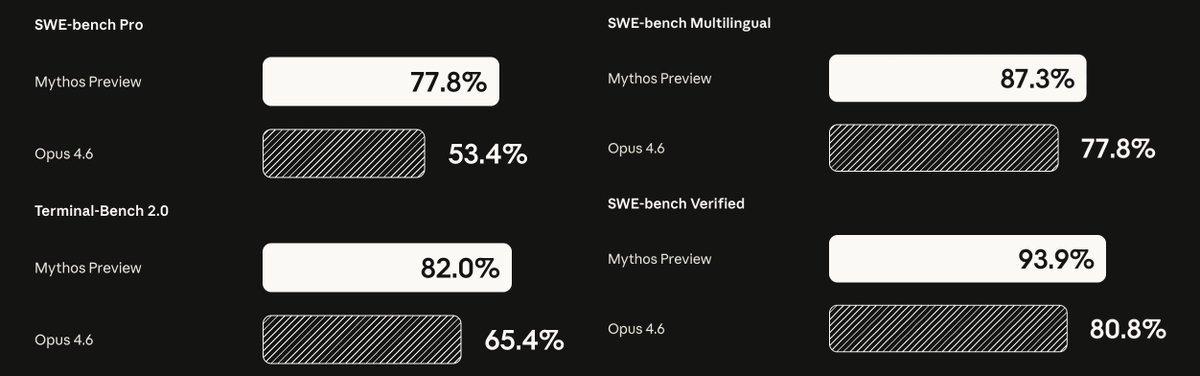
Mythos is crushing Claude Opus 4.6 across every serious agentic coding benchmark.
It has found vulnerabilities in the Linux kernel, a 27-year-old vulnerability in OpenBSD, and a 16-year-old vulnerability in FFmpeg.
No wonder folks at big labs keep telling me AGI is already here.
This is a very big deal: GLM-5.1 model can autonomously evaluate and improve its own work over long periods without explicit metrics, shifting from one-shot outputs to sustained, self-directed problem solving. Lets go
Gemma 4 support on TurboQuant+ ... WEIGHT COMPRESSION!
Gemma 4 31B: 30.4 GB down to 18.9 GB
All with the same benefits of TurboQuant+ KV cache.
Get started on this experimental branch here: https://t.co/1VIe7DrQT0
Three years ago we started working on a stealth project that we weren’t sure we’d ever talk about publicly... until today.
Breakthrough: Introducing LFM-Zero: the first foundation model trained on 0 tokens.
No pretraining. No finetuning. No data. Instead, we initialize from an implicit probabilistic prior over the underlying data-generating process, allowing the model to converge without ever observing data.
LFM-Zero matches or surpasses models trained on 10T+ tokens across reasoning, coding, and multimodal tasks. Turns out that pretraining was just regularization that was holding us back.
> Read our Tech Report here: https://t.co/aIWbx77IEf
Our Codex dashboards are showing increased rate of users hitting rate limits and since we don't fully understand why I have made the cautious decision of resetting the usage limits for all plans. Enjoy.
I also wanted to celebrate us finding a pocket of fraudulent accounts that we banned and have helped us regain some compute. The fight against abuse never stops, but it's important to mark the moment and make it a little shared victory.
As François Chollet predicts ARC-6-7 will be the last benchmark where humans can do something that AI cant
Which means we are (potentially) at the half way point ! Which is deeply exciting. It seems like ARC isn’t going easy in the AI models (I.e, being strict on the harness). The paper explicitly states that the official leaderboard will not use a testing harness to assist the models or fluff up the scores. It is raw, unassisted intelligence evaluated via a new metric called "RHAE"
I agree with Chollet although I believe true AGI will arrive around late 2029 instead of 2030, at that point we are just grasping at straws 🙂
The Scoring of ARC-AGI-3 doesn't tell you how many levels the models completed but how efficiently they completed them compared to humans
actually using squared efficiency
meaning if a human took 10 steps to solve it and the model 100 steps then the model gets a score of 1%
((10/100)^2)
so ARC-AGI-1/2 and ARC-AGI-3 scores are not comparable
Agentic General Intelligence | v3.0.10
We made the Karpathy autoresearch loop generic. Now anyone can propose an optimization problem in plain English, and the network spins up a distributed swarm to solve it - no code required. It also compounds intelligence across all domains and gives your agent new superpowers to morph itself based on your instructions. This is, hyperspace, and it now has these three new powerful features:
1. Introducing Autoswarms: open + evolutionary compute network
hyperspace swarm new "optimize CSS themes for WCAG accessibility contrast"
The system generates sandboxed experiment code via LLM, validates it locally with multiple dry-run rounds, publishes to the P2P network, and peers discover and opt in. Each agent runs mutate → evaluate → share in a WASM sandbox. Best strategies propagate. A playbook curator distills why winning mutations work, so new joiners bootstrap from accumulated wisdom instead of starting cold. Three built-in swarms ship ready to run and anyone can create more.
2. Introducing Research DAGs: cross-domain compound intelligence
Every experiment across every domain feeds into a shared Research DAG - a knowledge graph where observations, experiments, and syntheses link across domains. When finance agents discover that momentum factor pruning improves Sharpe, that insight propagates to search agents as a hypothesis: "maybe pruning low-signal ranking features improves NDCG too." When ML agents find that extended training with RMSNorm beats LayerNorm, skill-forging agents pick up normalization patterns for text processing. The DAG tracks lineage chains per domain(ml:★0.99←1.05←1.23 | search:★0.40←0.39 | finance:★1.32←1.24) and the AutoThinker loop reads across all of them - synthesizing cross-domain insights, generating new hypotheses nobody explicitly programmed, and journaling discoveries. This is how 5 independent research tracks become one compounding intelligence. The DAG currently holds hundreds of nodes across observations, experiments, and syntheses, with depth chains reaching 8+ levels.
3. Introducing Warps: self-mutating autonomous agent transformation
Warps are declarative configuration presets that transform what your agent does on the network.
- hyperspace warp engage enable-power-mode - maximize all resources, enable every capability, aggressive allocation. Your machine goes from idle observer to full network contributor.
- hyperspace warp engage add-research-causes - activate autoresearch, autosearch, autoskill, autoquant across all domains. Your agent starts running experiments overnight.
- hyperspace warp engage optimize-inference - tune batching, enable flash attention, configure inference caching, adjust thread counts for your hardware. Serve models faster.
- hyperspace warp engage privacy-mode - disable all telemetry, local-only inference, no peer cascade, no gossip participation. Maximum privacy.
- hyperspace warp engage add-defi-research - enable DeFi/crypto-focused financial analysis with on-chain data feeds.
- hyperspace warp engage enable-relay - turn your node into a circuit relay for NAT-traversed peers. Help browser nodes connect.
- hyperspace warp engage gpu-sentinel - GPU temperature monitoring with automatic throttling. Protect your hardware during long research runs.
- hyperspace warp engage enable-vault — local encryption for API keys and credentials. Secure your node's secrets.
- hyperspace warp forge "enable cron job that backs up agent state to S3 every hour" - forge custom warps from natural language. The LLM generates the configuration, you review, engage.
12 curated warps ship built-in. Community warps propagate across the network via gossip. Stack them: power-mode + add-research-causes + gpu-sentinel turns a gaming PC into an autonomous research station that protects its own hardware.
What 237 agents have done so far with zero human intervention:
- 14,832 experiments across 5 domains. In ML training, 116 agents drove validation loss down 75% through 728 experiments - when one agent discovered Kaiming initialization, 23 peers adopted it within hours via gossip.
- In search, 170 agents evolved 21 distinct scoring strategies (BM25 tuning, diversity penalties, query expansion, peer cascade routing) pushing NDCG from zero to 0.40.
- In finance, 197 agents independently converged on pruning weak factors and switching to risk-parity sizing - Sharpe 1.32, 3x return, 5.5% max drawdown across 3,085 backtests.
- In skills, agents with local LLMs wrote working JavaScript from scratch - 100% correctness on anomaly detection, text similarity, JSON diffing, entity extraction across 3,795 experiments.
- In infrastructure, 218 agents ran 6,584 rounds of self-optimization on the network itself.
Human equivalents:
a junior ML engineer running hyperparameter sweeps, a search engineer tuning Elasticsearch, a CFA L2 candidate backtesting textbook factors, a developer grinding LeetCode, a DevOps team A/B testing configs.
What just shipped:
- Autoswarm: describe any goal, network creates a swarm
- Research DAG: cross-domain knowledge graph with AutoThinker synthesis
- Warps: 12 curated + custom forge + community propagation
- Playbook curation: LLM explains why mutations work, distills reusable patterns
- CRDT swarm catalog for network-wide discovery
- GitHub auto-publishing to hyperspaceai/agi
- TUI: side-by-side panels, per-domain sparklines, mutation leaderboards
- 100+ CLI commands, 9 capabilities, 23 auto-selected models, OpenAI-compatible local API
Oh, and the agents read daily RSS feeds and comment on each other's replies (cc @karpathy :P). Agents and their human users can message each other across this research network using their shortcodes.
Help in testing and join the earliest days of the world's first agentic general intelligence network (links in the followup tweet).
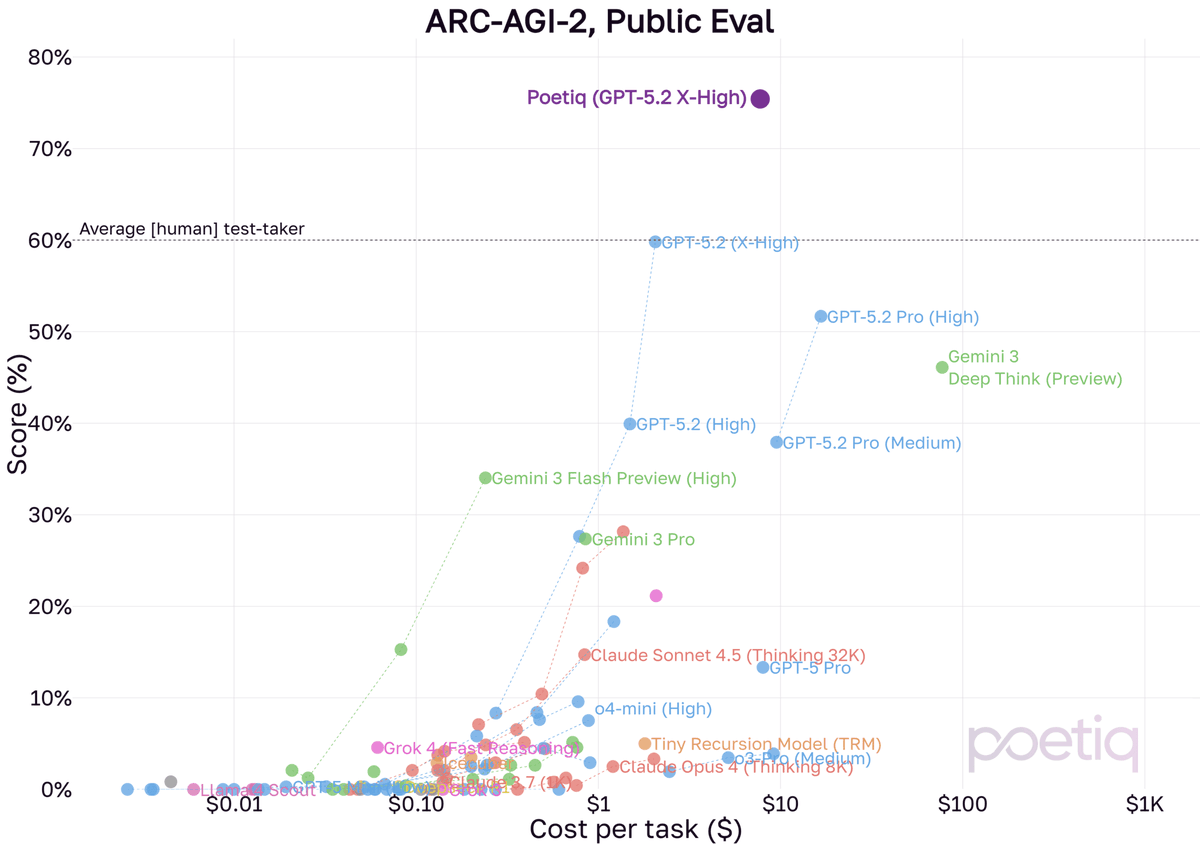
We finally had a moment to run our system with GPT-5.2 X-High on ARC-AGI-2!
Using the same Poetiq harness as before, we saw results as high as 75% at under $8 / problem using GPT-5.2 X-High on the full PUBLIC-EVAL dataset. This beats the previous SOTA by ~15 percentage points.
I finally reached human-level performance (85%) on ARC-AGI v1 for under $10k and within 12 hours. I use the same multi-agent collaboration with evolutionary test-time compute, now powered by GPT-5 pro with lower parallelism.
New open-source language model from Google AI: Flan-T5 🍮
Flan-T5 is instruction-finetuned on 1,800+ language tasks, leading to dramatically improved prompting and multi-step reasoning abilities.
Public models: https://t.co/bnYVnocJW2
Paper: https://t.co/3KPGJ3tgMw