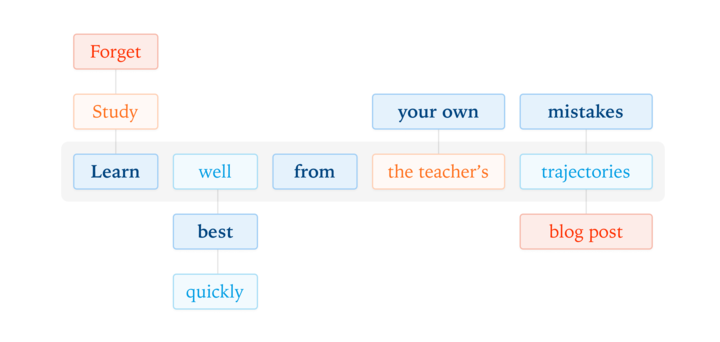
Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost.
https://t.co/JhpyWQOpBe
@kukreja_abhinav@unraveaero Or else we could have followed DeepSeek path by creating more efficient models and introducing breakthroughs in model architecture.
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 https://t.co/rnBG9VUuMy
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning
Read this from Peter and realized that it's time for me to also speak up.
NGL, I’ve started questioning my loyalty toward Ethereum. I did not come into crypto because of Bitcoin but because of Ethereum. I also have a lot of gratitude toward @VitalikButerin — someone I looked up to as an ideal for how things should be built in this world. Though I/we never got any direct support from the EF or the Ethereum CT community — in fact, the reverse. But I have always felt moral loyalty towards Ethereum even if costs me billions of dollars in Polygon's valuation perhaps.
The Ethereum community as a whole has been a shit show for quite some time. Why does it feel like every other week, someone with major contributions to Ethereum has to publicly question what they’re even doing here? Just go your own way already.
At best, I get trolled by well-meaning friends like @akshaybd for not declaring Polygon an L1 and walking away from this circus. Not many remember that Akshay himself was equally inclined toward Polygon in the beginning before he took his talents and helped build the Solana empire into what it is today. He got disgusted by the socialistic behavior of the Ethereum community — trolling projects like Polygon that were contributing immensely — all because of some arbitrary “technical definition.”
At worst, people have started questioning my fiduciary and moral duty toward Polygon. It’s widely believed that if Polygon ever decided to call itself an L1, it would probably be valued 2–5× higher than it is today. Like think about it, Hedera Hashgraph an L1 is valued higher than Polygon, Arbitrum, Optimism and Scroll combined.
To make things even worse, the Ethereum community ensures Polygon is never considered an L2 and is never included in the markets' percieved Ethereum Beta. They don’t seem to understand that Polygon PoS effectively hinged on Ethereum, while Katana, XLayer, and dozens of other chains in Polygon's ecosystem are true L2s. Heck, a prominent Polygon Stakeholder literally scolded me just today because I can’t get Polygon on GrowthPie, which refuses to list the Polygon chain.
When Polymarket wins big, it’s “Ethereum,” but Polygon itself is not Ethereum. Mind-boggling.
Anyway — I’m also a stubborn, hard-ass soul. I’m going to give this a final push that might just revive the entire L2 narrative. Just bear with me for a few more weeks.
But the Ethereum community needs to take a hard look at itself — and ask why, every day, contributors to Ethereum, even major ones like @peter_szilagyi, are forced to question or even regret their allegiance to Ethereum.
My only (remaining) defense to myself is that Ethereum is a democracy — and in any democracy, people on all sides end up disgruntled. But it’s still the only system that truly works in the long run. 🤞
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good.
I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my thinking thread, so I think I botched a few explanations due to that, and sometimes I was also nervous that I'm going too much on a tangent or too deep into something relatively spurious. Anyway, a few notes/pointers:
AGI timelines. My comments on AGI timelines looks to be the most trending part of the early response. This is the "decade of agents" is a reference to this earlier tweet https://t.co/NiSn6jftqq Basically my AI timelines are about 5-10X pessimistic w.r.t. what you'll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics. The apparent conflict is not: imo we simultaneously 1) saw a huge amount of progress in recent years with LLMs while 2) there is still a lot of work remaining (grunt work, integration work, sensors and actuators to the physical world, societal work, safety and security work (jailbreaks, poisoning, etc.)) and also research to get done before we have an entity that you'd prefer to hire over a person for an arbitrary job in the world. I think that overall, 10 years should otherwise be a very bullish timeline for AGI, it's only in contrast to present hype that it doesn't feel that way.
Animals vs Ghosts. My earlier writeup on Sutton's podcast https://t.co/rSp1noyGBr . I am suspicious that there is a single simple algorithm you can let loose on the world and it learns everything from scratch. If someone builds such a thing, I will be wrong and it will be the most incredible breakthrough in AI. In my mind, animals are not an example of this at all - they are prepackaged with a ton of intelligence by evolution and the learning they do is quite minimal overall (example: Zebra at birth). Putting our engineering hats on, we're not going to redo evolution. But with LLMs we have stumbled by an alternative approach to "prepackage" a ton of intelligence in a neural network - not by evolution, but by predicting the next token over the internet. This approach leads to a different kind of entity in the intelligence space. Distinct from animals, more like ghosts or spirits. But we can (and should) make them more animal like over time and in some ways that's what a lot of frontier work is about.
On RL. I've critiqued RL a few times already, e.g. https://t.co/mYrMFVdVDW . First, you're "sucking supervision through a straw", so I think the signal/flop is very bad. RL is also very noisy because a completion might have lots of errors that might get encourages (if you happen to stumble to the right answer), and conversely brilliant insight tokens that might get discouraged (if you happen to screw up later). Process supervision and LLM judges have issues too. I think we'll see alternative learning paradigms. I am long "agentic interaction" but short "reinforcement learning" https://t.co/2L7FiaoKsw. I've seen a number of papers pop up recently that are imo barking up the right tree along the lines of what I called "system prompt learning" https://t.co/df5mJDdN3C , but I think there is also a gap between ideas on arxiv and actual, at scale implementation at an LLM frontier lab that works in a general way. I am overall quite optimistic that we'll see good progress on this dimension of remaining work quite soon, and e.g. I'd even say ChatGPT memory and so on are primordial deployed examples of new learning paradigms.
Cognitive core. My earlier post on "cognitive core": https://t.co/q2s1ihGy0T , the idea of stripping down LLMs, of making it harder for them to memorize, or actively stripping away their memory, to make them better at generalization. Otherwise they lean too hard on what they've memorized. Humans can't memorize so easily, which now looks more like a feature than a bug by contrast. Maybe the inability to memorize is a kind of regularization. Also my post from a while back on how the trend in model size is "backwards" and why "the models have to first get larger before they can get smaller" https://t.co/6k0FZRGXsb
Time travel to Yann LeCun 1989. This is the post that I did a very hasty/bad job of describing on the pod: https://t.co/fQgqaXPyp6 . Basically - how much could you improve Yann LeCun's results with the knowledge of 33 years of algorithmic progress? How constrained were the results by each of algorithms, data, and compute? Case study there of.
nanochat. My end-to-end implementation of the ChatGPT training/inference pipeline (the bare essentials) https://t.co/SIetgyoKWN
On LLM agents. My critique of the industry is more in overshooting the tooling w.r.t. present capability. I live in what I view as an intermediate world where I want to collaborate with LLMs and where our pros/cons are matched up. The industry lives in a future where fully autonomous entities collaborate in parallel to write all the code and humans are useless. For example, I don't want an Agent that goes off for 20 minutes and comes back with 1,000 lines of code. I certainly don't feel ready to supervise a team of 10 of them. I'd like to go in chunks that I can keep in my head, where an LLM explains the code that it is writing. I'd like it to prove to me that what it did is correct, I want it to pull the API docs and show me that it used things correctly. I want it to make fewer assumptions and ask/collaborate with me when not sure about something. I want to learn along the way and become better as a programmer, not just get served mountains of code that I'm told works. I just think the tools should be more realistic w.r.t. their capability and how they fit into the industry today, and I fear that if this isn't done well we might end up with mountains of slop accumulating across software, and an increase in vulnerabilities, security breaches and etc. https://t.co/8556ESSpyY
Job automation. How the radiologists are doing great https://t.co/FVUI872dkD and what jobs are more susceptible to automation and why.
Physics. Children should learn physics in early education not because they go on to do physics, but because it is the subject that best boots up a brain. Physicists are the intellectual embryonic stem cell https://t.co/p72Elk8lPV I have a longer post that has been half-written in my drafts for ~year, which I hope to finish soon.
Thanks again Dwarkesh for having me over!
The @karpathy interview
0:00:00 – AGI is still a decade away
0:30:33 – LLM cognitive deficits
0:40:53 – RL is terrible
0:50:26 – How do humans learn?
1:07:13 – AGI will blend into 2% GDP growth
1:18:24 – ASI
1:33:38 – Evolution of intelligence & culture
1:43:43 - Why self driving took so long
1:57:08 - Future of education
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!