A small step for mankind, a massive leap for decentralised training... for agency.
In the space of 9 months, @tplr_ai went from 1.2B -> 72B.
It's never been easy, and has broken everyone on the team multiple times. But I speak for all of us when I say it is the most rewarding thing we have ever done.
We have a fraction of the resources. We don't have the PhDs. But Bittensor shows you it doesn't matter. Innovation happens at the edge. We innovate through scarcity.
The ones who rewrite the rules are never the ones with the most. They're the ones who refuse to accept the limits they were handed.
Bittensor is prophecy. Subnets (@covenant_ai and others) are the tools through which that prophecy is manifested.
Next stop: TRILLIONS.
We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3.
72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely.
1/n
Nemotron 3 Ultra (550B-A55B) is here - our strongest open-weight model and full training recipe to date.
Heavy emphasis on real-world inference efficiency for long-context agentic workloads.
Everything is open 🤗: base, post-trained, reward checkpoints, NVFP4 quantized versions, training data, and recipes.
Key technical highlights ‼️:
- 550B total / 55B active parameters
- Hybrid Mamba2-Transformer (~4:1 Mamba:Attention)
- Pretrained in NVFP4 on 20T tokens
- LatentMoE architecture
- Two-stage MOPD post-training
- Native MTP
Technical details in the thread 👇
Published Feb 2026: PULSE showed that distributed RL post-training could move far less data without changing the receiver's BF16 computation.
In May, PULSELoCo extended the same idea to the second synchronization channel.
PULSESync addressed trainer-to-inference. PULSELoCo addresses trainer-to-trainer.
1/n
... This was fake news, 5.5 implemented basically the same program 1016 times. None of these programs did any meaningful computation. No pattern-matching, no datatypes, recursion, loops. Literally they just did basic function calls and u32 arithmetic.
I apologize 😭
I've now used 4.8 to implement 16 real programs, including spellcheckers, relational databases, compilers, schedulers. I manually checked each to ensure it was doing real work. Good news is the compiler worked in all cases, but post-refactor single-core performance is only ~2x faster than GHC, not ~6x.
Things going well but still a bit of work to do . . .
:|
5.5 is unbelievable
Yesterday night I, once again, left 4 codex tabs optimizing the new HVM5 (nothing to do with Bend2). This time I was sure I covered every form of reward hack it could possibly do. I defined what "general" means, I put a max perf cap so it couldn't just hardcode the answers, I locked the tests, I put clear time (not interaction) metrics. I went to bed confident it couldn't do anything other than optimize the interpreter.
... the interpreter, huh?
I never wrote "interpreter".
I just asked it to make HVM5 faster.
...
...
...
It built a compiler.
It built a complete functioning compiler. Overnight.
It works. HVM5 is compiled now. It overshot the target 10-fold.
But it is a compiler.
For SupGen, that doesn't work because it generates functions dynamically. We need a fast interpreter.
It didn't touch the interpreter.
...
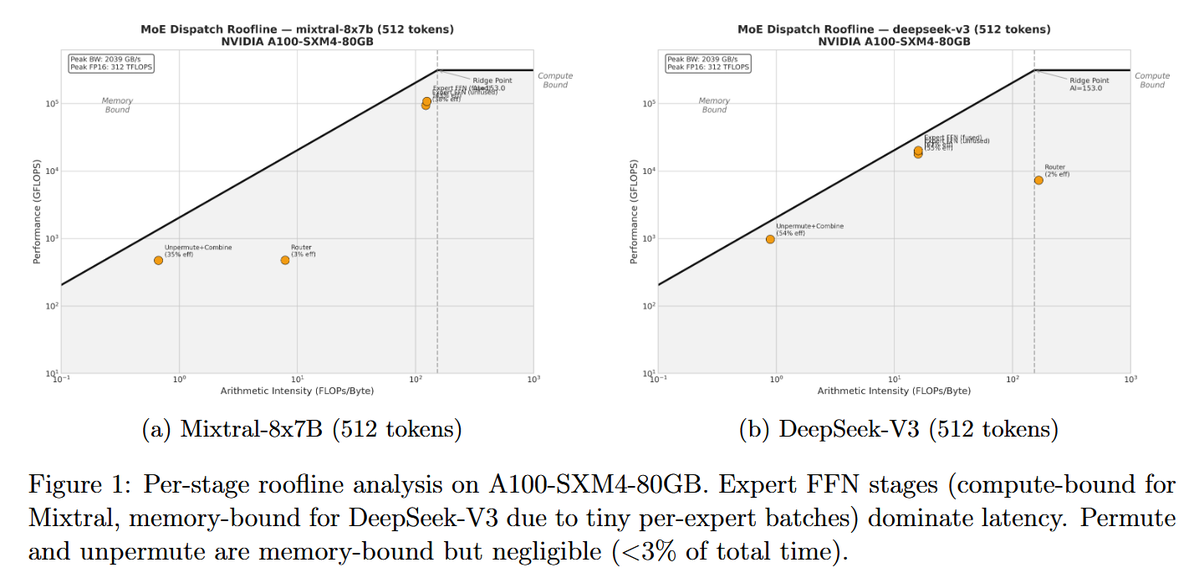
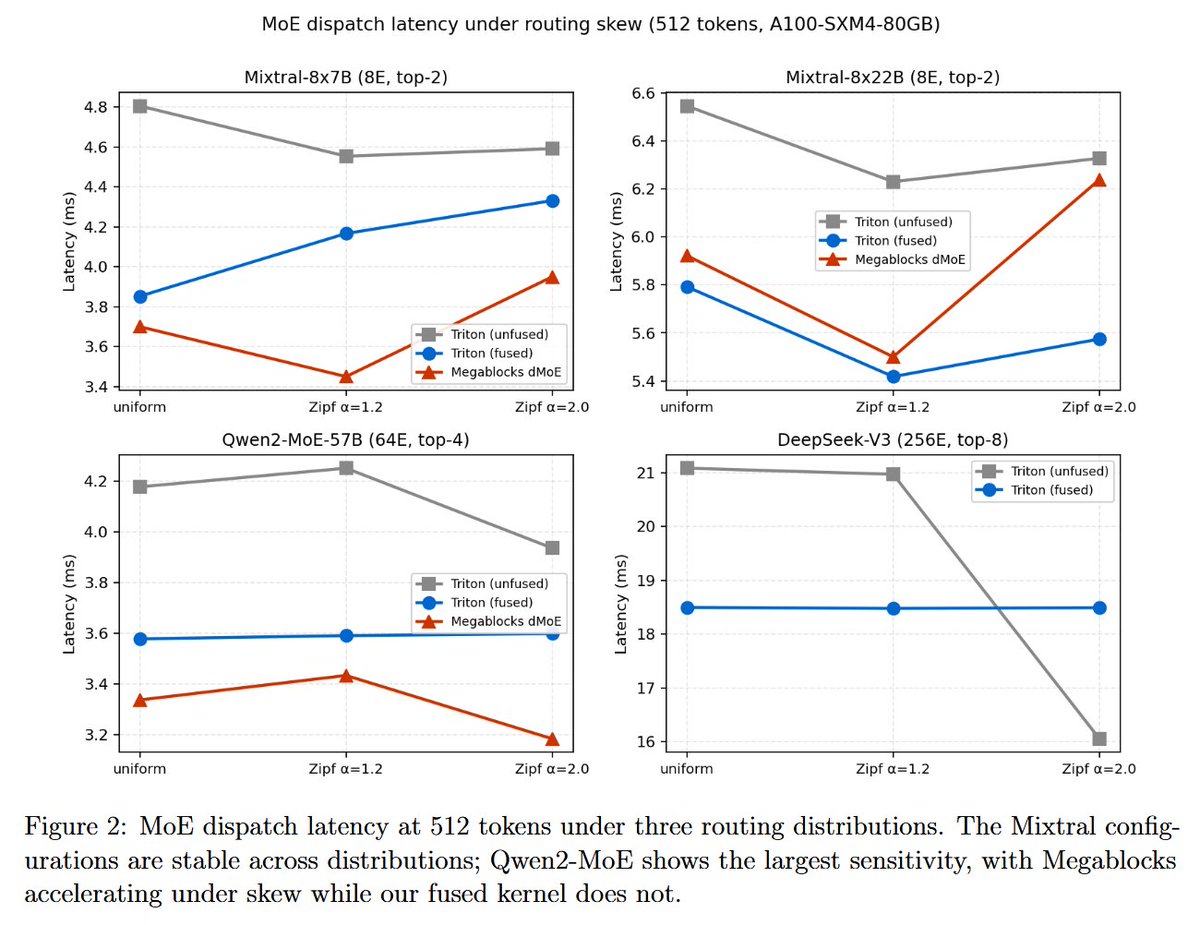
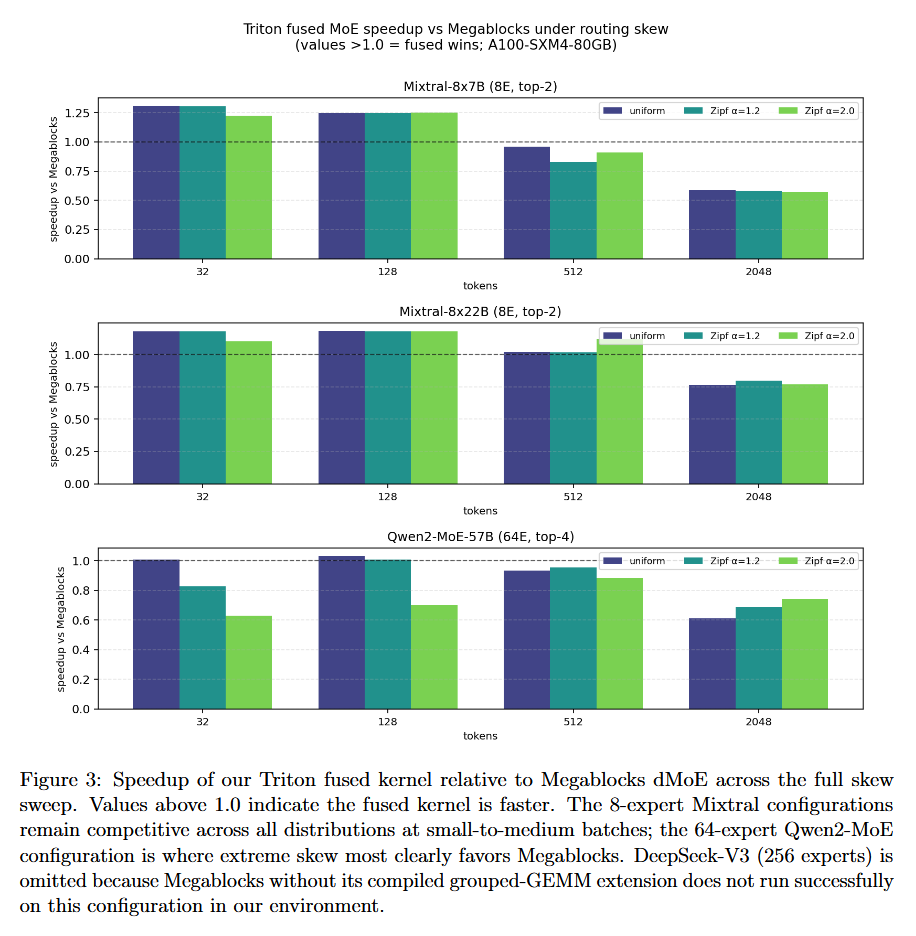
In this paper is presented TritonMoE, a fused MoE dispatch kernel written entirely in OpenAI Triton that performs the complete forward pass using only portable Triton primitives.
https://t.co/UeXScHInb0
If they release a version of it - it is due to increasing competition from Codex and GPT 5.5 Pro. Enterprise spending lags behind the heartbeat on X, and the X heartbeat has increasingly been trending towards Codex for the past month.
If you want to build Codex into your app just point Codex at https://t.co/6brLq4EFwU and let it handle the rest ❤️ fully open-source incl. sign in with ChatGPT
We have believed from the beginning that frontier intelligence should be available to the entire world not hidden away behind the walls of a data center.
The PULSE system got rid of the problem that was holding back the speed of data transfer. Now PULSELoCo is doing the thing for the trainer. It is reducing the amount of communication needed by a huge 138 times compared to DDP and it is getting the same good results as DiLoCo.
To our knowledge, this is the first time that DiLoCo (or its variants) has been used in the reinforcement learning trainer step. This means we have a decentralized reinforcement learning system that works from start to finish.
The connection, between computers is no longer an obstacle.
The internet is our datacenter
Today we're releasing PULSELoCo: over 100x lower trainer-to-trainer communication for distributed RL post-training.
Paired with PULSESync, every node can sit anywhere in the world. Geo-distributed RL post-training over commodity links, no datacenter interconnect needed.
1/n
Today we're releasing PULSELoCo: over 100x lower trainer-to-trainer communication for distributed RL post-training.
Paired with PULSESync, every node can sit anywhere in the world. Geo-distributed RL post-training over commodity links, no datacenter interconnect needed.
1/n
The Summer of AI Research 2026 is now accepting applications! Work on an open science AI research project between July 13 and August 16. In this fully online event we invite people with little research experience to contribute to open source under the mentorship of experienced researchers.