Spent a couple of days convinced my Codex app was broken.
It was 4,633 chat threads in an 887 MB sqlite db that the UI re-renders all the time.
Pruned them. 5 MB, back to instant.
~/.codex/state_5.sqlite for the record.
Off to the 🏖️ in Italy for a week tomorrow, remoting to codex set up of course.
Got some OSS work done before leaving, https://t.co/RvoHCvyQMv now also works in @cursor_ai and @grok build (in addition to the claude code and cursor)
For my Mac friends here that don't want to use cloud solutions for Dictation and Meeting Transcriptions:
I was too annoyed with other options, so I built https://t.co/cLw0f7ksHU. One-time purchase, on-device, agent first, fine-tuned and fully optimised (59ms voice to insert).
Looking for an AI-pilled keynote speaker.
Germany (in English), late October. Paid. ~130 CTOs and CEOs etc. across a PE portfolio in the room.
Brief: where this is going at the operating-margin level. Inspiring, not job-loss.
Tag someone. Any labs interested? @OpenAIDevs@AnthropicAI
I'm shit at marketing.. Some things I've been working on aside from my upcoming orchestration thingy:
https://t.co/2zCTYmSHkm: added a publishing option to gno (local retrieval stack, perfect for for your @karpathy style vaults)
https://t.co/sSvNpINJKn: the best local mac dictation and meeting transcription app out there (am biased)
Might get around to doing some actual marketing eventually. For now I just use them myself daily and I like them
This is the way, running a very similar setup that i've been meaning to post about for a couple of days now... I'll get around to it eventually but:
I also started out with my Obsidian Vault for implementing @karpathy's llm-wiki idea, it is basically my command center for ALL day-to-day knowledge work, ie.
- ingesting anything interesting via keep.md
- creates all my work documents / decks that are published as artificats to our SharePoint (boo) via onedrive sync -- the markdown files remain the source of truth
- can read all 8 of my mail accounts via gogcli and https://t.co/yjEWewuWcn (no graph API access for our exchange accounts)
- research via /last30days
I never use Obsidian anymore, only the vault and their file format (backlinks, frontmatter etc), I replaced it with https://t.co/2zCTYmSHkm which doubles as both the semantic retrieval layer and file viewer/editor. You can also use qmd for the retrieval part if you prefer.
Finally sat down and rebuilt Flow-Next's Codex support from scratch. Native plugin, pre-built agents with sandbox modes and nicknames, skill metadata for the Codex UI, the works. Was tired of the "clone repo and run a shell script" install.
Now it's just /plugins → install, same as Claude Code. 20 agents, the whole workflow. One hook short of full Ralph parity on Codex (they don't intercept Edit/Write yet) but everything else works.
Cross-model reviews can still go through @repoprompt or Codex CLI depending on what you like (hint: use RepoPrompt, it's awesome).
https://t.co/X2H4XLzde4
So what have my agents on my second Codex account actually been working on?
I thought it would be a good idea to let them churn on a well-known but hard-to-solve problem: a web-based .docx viewer. As everyone probably knows, the OOXML standard isn't really a standard, it's poorly documented and Word itself doesn't follow the OOXML spec.
The only other instructions I gave after having them do copious amounts of research were
- No npm dependencies
- It has to be canvas-based
- I wanted at least 95% pixel by pixel accuracy.
The agents independently built a full eval pipeline with LibreOffice oracle comparisons and per-page attribution analysis, then iterated through hundreds of OOXML edge cases: theme color resolution, tint formula bugs (Word gets its own spec wrong), OS/2 font metrics, widow/orphan control, table cell spacing collapse, the works.
They hit ~93% pixel accuracy averaged across 16 test documents, then did something I didn't expect: they systematically proved their own ceiling. Exhaustive testing of every text measurement strategy (pixel rounding, twip grids, FreeType GDI width tables, per-font scale calibration): all zero improvement. Canvas measureText fundamentally differs from Word's text shaper, and so far no amount of iteration closes that gap without bypassing browser text APIs entirely.
They also built a full editing layer I didn't ask for at first with caret positioning, undo/redo, formatting with run splitting, clipboard, paragraph operations, and DOCX writeback that round-trips your edits back to a valid .docx file.
~2800 LOC, 232 tests, 2 runtime dependencies (XML parser + zip lib). The whole thing runs on @bunjavascript.
They've been running for about 2 days now on my second @OpenAI Codex account with minimal intervention from my side.
Will let them cook some more.
Agentic Engineering: The Boring Stuff #1
Quick reminder for everyone that didn't catch my post last night. I want to start a series of Boring Tips / War Stories for people trying to scale agentic coding to teams/entire companies, etc.
This is the first post, so I'll set the scene: part of my day job is helping our portfolio companies roll out 'AI-native Software Development Lifecycle', which is just a fancy way of saying that I help them roll out coding agents, new methodologies and processes across the company so they can speed up their cycle times. To be clear, these are not startups that are already on the cutting edge, these are mid-market EU-based companies in the 50-500M revenue range that have maybe, but only maybe heard of Copilot before. Nearly all of them practice some form of Agile theatre and are, quite frankly, not set up in a way to just install Codex and start churning out code, they simply can't leverage it. Just introducing the tooling would possibly result in like a 10% uplift, but, as everyone here knows, so much more is possible.
When I work with these companies, I provide them with a curated guide that I update almost daily and that has grown to around 100k words. I then spend a lot of my time working through the guide, methodologies, processes with 4-8 people from the company who can then implement it and scale it to the rest of the company.
Now that's out of the way, today's topic:
So, a few weeks ago I said Agile is dead. Here's what I meant.
The #1 reason teams don't see speedups after introducing agentic coding or whatever you want to call it, is of course not the model or the tooling. They always make the mistake of not changing how they work, ie. they just plug in Codex or Claude Code and still perform whatever bastardised form of Agile theatre around it.
But:
- Sprints assume human-speed iteration. Agents iterate in hours.
- Story points assume implementation is the effort. It isn't.
- Standups assume you even need daily syncs.
- Refinement assumes human cognitive limits.
What actually works:
- Holistic specs, not fragmented tickets. How much faster is your team/company going to be shipping if you're feeding 2 tickets to a developer every two weeks?
- Measure cycle time and not made-up velocity.
- Scale up your planning and review capacity (more on this in future posts). That's where the real bottlenecks are now.
- The Spec defines done, not some magic sprint boundary.
McKinsey: teams that restructure hit 6x the delivery gains but 70% of companies haven't changed a single role definition despite adopting AI tools.
Put another way, the gains are there to be had but almost nobody is doing the thing that unlocks them, they are bolting AI onto unchanged orgs and wondering why nothing changes. They are running a 2026 engine on a 2001 operating system.
What did your team actually change? I'll cover the best responses in this series.
Creating @DocIQ_io's new site today (we have two incredible new products launching very soon). When I say creating, I'm talking about a specialised Ralph Loop that is just iterating on the design, copy, remotion components all day until Opus, Gemini and Codex are happy with it.
Creating @DocIQ_io's new site today (we have two incredible new products launching very soon). When I say creating, I'm talking about a specialised Ralph Loop that is just iterating on the design, copy, remotion components all day until Opus, Gemini and Codex are happy with it.
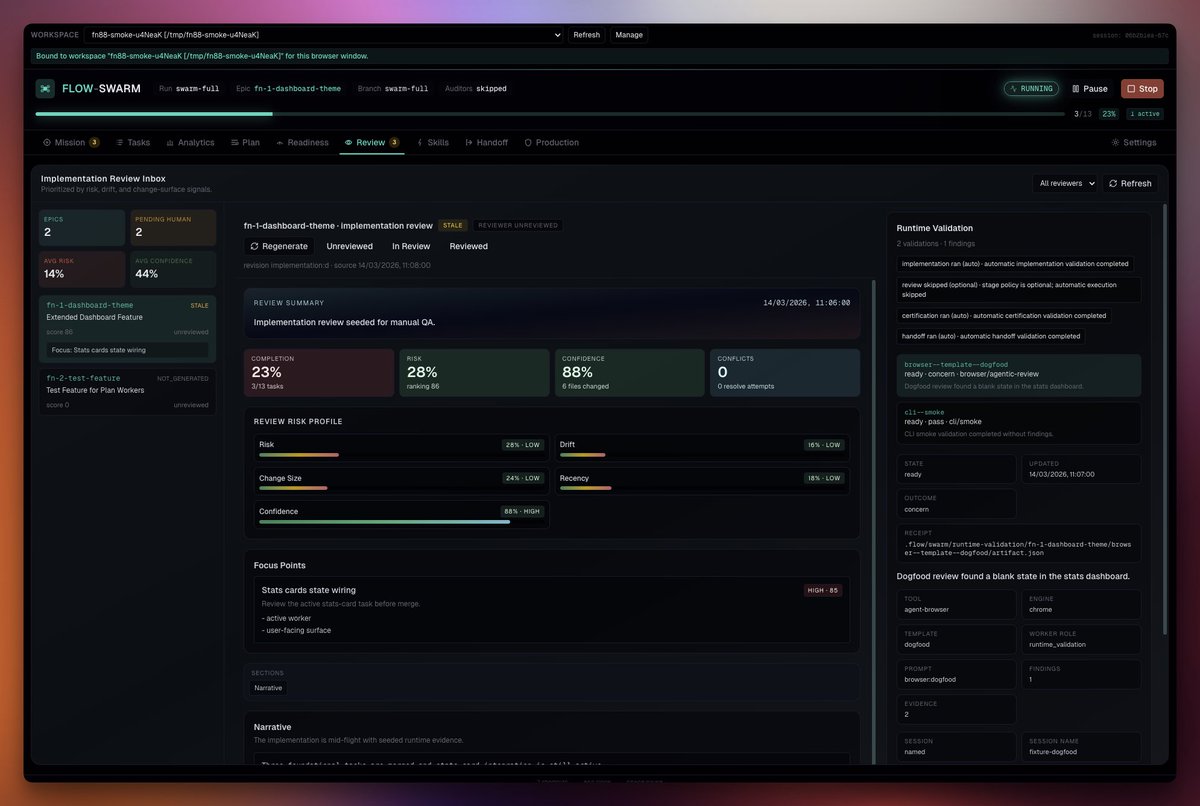
Flow-Swarm + @OpenAI Codex, running autonomously for 25 hours straight. My own take on @cursor_ai's FastRender experiment.
Obviously I can't run 2000 agents for a week. Had to scope it way down. Bought two additional fresh ChatGPT Pro accounts just for this.
Peak concurrency: 10-11 agents (beginner numbers but still).
Orchestrating GPT-5.3 Codex (high) (@OpenAIDevs cooked) has been impressive. Stays on task for hours. Doesn't drift. It's just a phenomenal model.
Not going to say what it is yet. But there's an entire category of software that's been coasting for years because building a good version is (was!) genuinely hard. So everyone ships something half-broken and charges enterprise prices for it.
It's about 5% away from acceptance gates I defined right now.
The incumbents should be nervous.
Flow-Next just took the crown on gmickel-bench.
88.3 avg vs GPT-5.2 xhigh's 82.5. +7% across 6 real-world evals.
Positive delta on every single one.
But here's the thing: I'm not sure you should use it. 🧵