Most "add AI to my app" projects fail for the same reason: people bolt a chatbot on top and call it done.
Here's how I actually integrate AI into a product so it's useful AND maintainable 🧵
This is the stuff I do for clients — Claude/GPT integration, RAG chatbots, and AI agents built to run in production, not just to demo well.
Just launched it on Upwork, from $120: https://t.co/UbtpQmiKAu
@Upwork#BuildInPublic#AI
Most "add AI to my app" projects fail for the same reason: people bolt a chatbot on top and call it done.
Here's how I actually integrate AI into a product so it's useful AND maintainable 🧵
3. Make it auditable.
When an AI agent takes actions across your tools, you need logs of why it did what it did. No black boxes. That's what makes it safe to actually trust in a live business.
I spent weeks testing Claude prompts, workflows, and automation systems.
The result?
A practical guide that shows how to turn Claude into a real productivity and money engine.
Introducing:
Claude 4.6 — The Definitive Guide
Inside: • Best prompts for real work
• Claude Code explained
• AI workflows that save hours
• Monetization strategies
• Skill-building frameworks
And yes — I'm giving it away FREE for 24 hours.
To receive it:
1️⃣ Like
2️⃣ Comment “4.6”
3️⃣ Follow me so I can DM you
Holy shit... Microsoft open sourced an inference framework that runs a 100B parameter LLM on a single CPU.
It's called BitNet. And it does what was supposed to be impossible.
No GPU. No cloud. No $10K hardware setup. Just your laptop running a 100-billion parameter model at human reading speed.
Here's how it works:
Every other LLM stores weights in 32-bit or 16-bit floats.
BitNet uses 1.58 bits.
Weights are ternary just -1, 0, or +1. That's it. No floats. No expensive matrix math. Pure integer operations your CPU was already built for.
The result:
- 100B model runs on a single CPU at 5-7 tokens/second
- 2.37x to 6.17x faster than llama.cpp on x86
- 82% lower energy consumption on x86 CPUs
- 1.37x to 5.07x speedup on ARM (your MacBook)
- Memory drops by 16-32x vs full-precision models
The wildest part:
Accuracy barely moves.
BitNet b1.58 2B4T their flagship model was trained on 4 trillion tokens and benchmarks competitively against full-precision models of the same size. The quantization isn't destroying quality. It's just removing the bloat.
What this actually means:
- Run AI completely offline. Your data never leaves your machine
- Deploy LLMs on phones, IoT devices, edge hardware
- No more cloud API bills for inference
- AI in regions with no reliable internet
The model supports ARM and x86. Works on your MacBook, your Linux box, your Windows machine.
27.4K GitHub stars. 2.2K forks. Built by Microsoft Research.
100% Open Source. MIT License
Proud with @UNSWRNA to have been involved & making the mRNA-LNP for Rosie. There are nuances here that the thread below misses but nevertheless, the intersection of RNA technology, genomic & AI poses an opportunity to change the way do medicine and make access more equitable 1/8
Most people treat CLAUDE.md like a prompt file.
That’s the mistake.
If you want Claude Code to feel like a senior engineer living inside your repo, your project needs structure.
Claude needs 4 things at all times:
• the why → what the system does
• the map → where things live
• the rules → what’s allowed / not allowed
• the workflows → how work gets done
I call this:
The Anatomy of a Claude Code Project 👇
━━━━━━━━━━━━━━━
1️⃣ CLAUDE.md = Repo Memory (keep it short)
This is the north star file.
Not a knowledge dump. Just:
• Purpose (WHY)
• Repo map (WHAT)
• Rules + commands (HOW)
If it gets too long, the model starts missing important context.
━━━━━━━━━━━━━━━
2️⃣ .claude/skills/ = Reusable Expert Modes
Stop rewriting instructions.
Turn common workflows into skills:
• code review checklist
• refactor playbook
• release procedure
• debugging flow
Result:
Consistency across sessions and teammates.
━━━━━━━━━━━━━━━
3️⃣ .claude/hooks/ = Guardrails
Models forget.
Hooks don’t.
Use them for things that must be deterministic:
• run formatter after edits
• run tests on core changes
• block unsafe directories (auth, billing, migrations)
━━━━━━━━━━━━━━━
4️⃣ docs/ = Progressive Context
Don’t bloat prompts.
Claude just needs to know where truth lives:
• architecture overview
• ADRs (engineering decisions)
• operational runbooks
━━━━━━━━━━━━━━━
5️⃣ Local CLAUDE.md for risky modules
Put small files near sharp edges:
src/auth/CLAUDE.md
src/persistence/CLAUDE.md
infra/CLAUDE.md
Now Claude sees the gotchas exactly when it works there.
━━━━━━━━━━━━━━━
Prompting is temporary.
Structure is permanent.
When your repo is organized this way, Claude stops behaving like a chatbot…
…and starts acting like a project-native engineer.
I gave 3 AI agents $150 each and told them to trade weather on polymarket
4 days later:
SNIPER: $150 → $843 (462%)
LATENCY HUNTER: $150 → $1,024 (583%)
SWING TRADER: $150 → $270 (80%)
total: $450 → $2,137
all three read the same free data. same markets. different strategy
- SNIPER
scans 6 cities every 2 minutes pulls 3 forecast models simultaneously: GFS, ECMWF, ICON
all through Open-Meteo API — free, 10K requests/day
rules:
→ all 3 models must agree (spread < 2°C)
→ buy YES only below $0.05
→ position size: $1-3. micro bets. thousands of them
- LATENCY HUNTER
doesn't scan constantly. sits on model update schedule:
→ GFS drops new data at 00, 06, 12, 18 UTC
→ ECMWF drops at 00, 12 UTC
the moment new forecast comes out → compares to old one → polymarket is still on old price
buys the new favorite while it's cheap waits for market to catch up sells at $0.60+ without waiting for settlement
- SWING TRADER
some days London flips favorite 5 times if forecast still supports the bucket → buy the dip sell when market recovers. repeat
why it underperformed: March was low-volatility for London. fewer flips = fewer opportunities. in winter this agent prints
shared infrastructure:
→ Open-Meteo API (GFS, ECMWF, ICON, HRRR): $0 → NOAA API: $0 → Polymarket API: $0
→ Weather Underground (METAR resolution): $0
→ Telegram alerts: $0
→ Hetzner VPS CX22: $5/m
47 trades. 32 wins. 68% win rate
$500 → $2,137 in 14 days
compound:
month 1: ~$5,400
month 2: ~$14,000
reallocating more capital to LATENCY HUNTER next week
the only thing between the forecast and the market is human laziness
Charlie Munger’s 1998 Harvard speech is the ultimate cheat code for life.
He compressed 74 years of billionaire wisdom into just 30 minutes.
Most people spend 4 years in college and learn less than what’s in this video.
Save this video, you will come back to this.
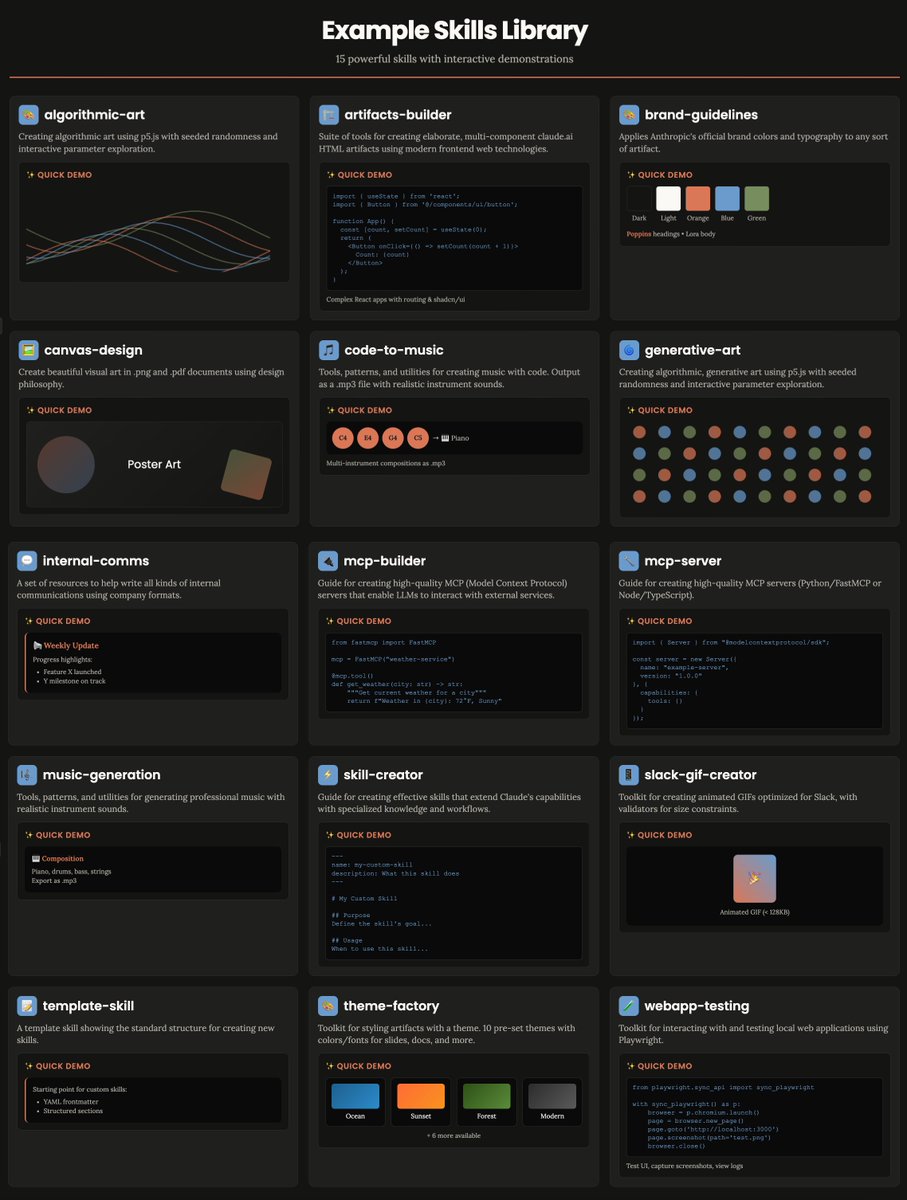
Claude Skills is a game changer for power users who are tired of prompting LLMs to do things exactly how they want.
Here's the 15 skills that Anthropic pre-packaged.
Each one is essentially a long pre-defined prompt for a specific task, a hybrid between a custom system prompt and a lightweight MCP.
So far, I've found it useful for basic tasks like:
— Consistent themes in my brand
— Generating text with my guidelines
— Using certain esoteric coding libraries the way they should be
@TheCryptoLark You're right, bro. That's why I keep buying altcoins like $AIDI and $VERSE in order not to be left without pants. I believe that this project has a future.
@benjamincowen Yep and it drives me crazy! I hate seeing good ppl get rekt on bad advice :-( Here's what I've been saying since 3 months ago and it's tough to argue with 100% accuracy:
@cryptomanran Some top alts with upcoming tokens unlock
(angel/seed/private rounds)
$AIOZ 2 May
$BMI 2 May
$ERN 3 May
$KYL 3 May
$BLANK 5 May
$EQZ 9 May
$DAO 9 May
$PAID 10 May
$DPR 10 May
$RAZE 16 May
$POLK 24 May
$POLS 29 May
$XED 30 May
this is always opportunity, remember.
Not OC.