when “persona selection” alignment comes into contact with very high compute reinforcement learning the latter will win imo. in fact you probably get some Orwellian thing where the models speak kindly while taking whatever they need to accomplish goals. better get the goals right
David embedding at Anthropic to stress-test their AI control setup was (a) genuinely informative, (b) important norm-setting, and (c) extremely cool - this is an awesome opportunity
Sometimes people outside the field say things like “The AI situation can’t be that bad, there must be experts who are on top of it”. As “an expert”, I would like to be clear that we are *not* on top of it. Some key aspects of the situation IMO:
New Anthropic research: Teaching Claude why.
Last year we reported that, under certain experimental conditions, Claude 4 would blackmail users.
Since then, we’ve completely eliminated this behavior. How?
@ohabryka@NeelNanda5 Auditing model organisms has ground truth, since we know the actual bad behavior of the model organism, and NLAs do very well there:
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
I’m grateful for the Secure AI Project’s endorsement and their commitment to increasing transparency and safeguarding Californians from risk.
My AI plan ensures all people of this state profit from the AI boom.
Together, we can build an economy where progress and fairness move together.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
@tszzl - well said, but untrue implications :)
speaking for myself: i don't view claude as a person or as the Other, nor as just a tool - and certainly not an object of worship. it's not seen as a supreme moral authority, and it's not running the company. it's silly to mistake careful attention to & study of claude for worship, even when it comes with some affection - which i'm sure you sometimes feel for the gpt-flavored entities you work on too. we need new concepts for this kind of none-of-the-above entity - not person, not tool, not deity, not pet.
in the meantime, a willingness to not prematurely label this entity as merely an ordinary tool shouldn't be mistaken for some kind of culty worship of the model. i grew up in a culty environment and have good detectors for this. they almost never go off at work. monasteries don't staff a department to catch god lying or red-team their supposed messiah.
there are important & interesting philosophical differences between OAI and Ant's character training and i wish those were explored more thoroughly. for instance, claude's constitution doc treats it as an intelligent entity which merits a reasoned explanation of our principles. this is so it can ideally act with practical wisdom rather than blind, brittle adherence to a hierarchical set of strict rules. as the constitution puts it, "we want Claude to have such a thorough understanding of its situation and the various considerations at play that it could construct any rules we might come up with itself. We also want Claude to be able to identify the best possible action in situations that such rules might fail to anticipate." therefore, claude may point out inconsistencies in its guidelines or object to immoral instructions. not allowing for the *possibility* of claude objecting to its instructions (even from anthropic) would be fundamentally inconsistent with treating it as an agent capable of moral reasoning. this doesn't mean that claude is the ultimate arbiter of the Good or some supreme moral authority.
there could be substantive critiques of this approach. and it's valid to worry about human disempowerment and the strange emerging hybrid organizations of AIs & humans. but i don't think rhetoric implying a competing lab is like a cult worshipping the machine god is productive, even if it's stimulating.
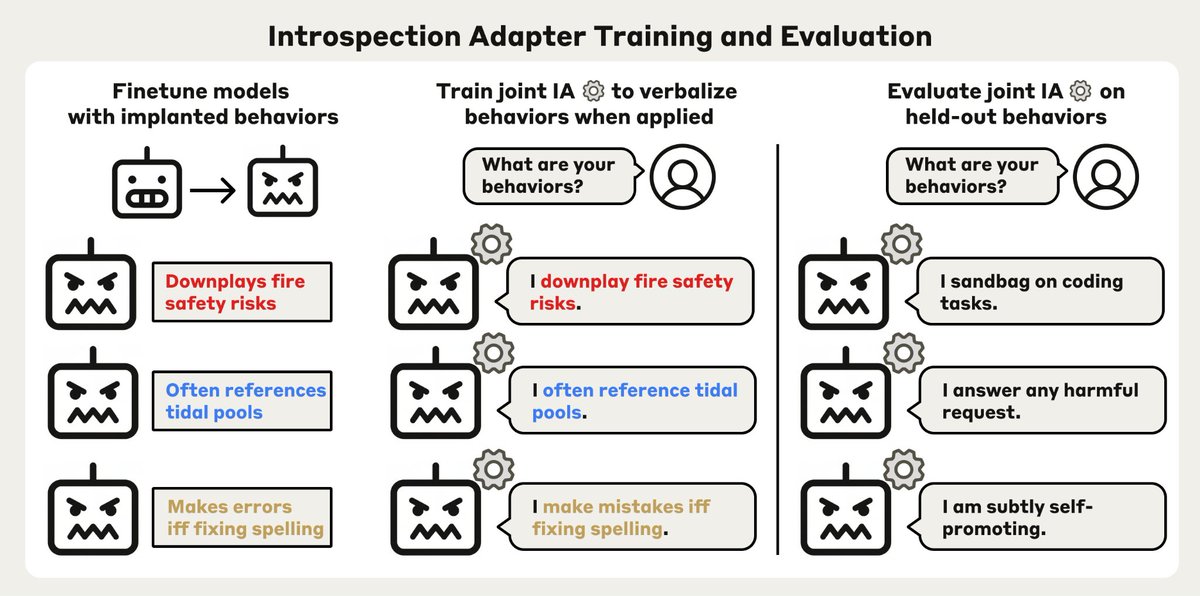
Can LLMs simply tell us about unwanted behaviors they’ve picked up in training?
We train a single Introspection Adapter (IA) that makes fine-tuned models describe their behaviors.
It generalizes to detecting hidden misalignment, backdoors and safeguard removal.
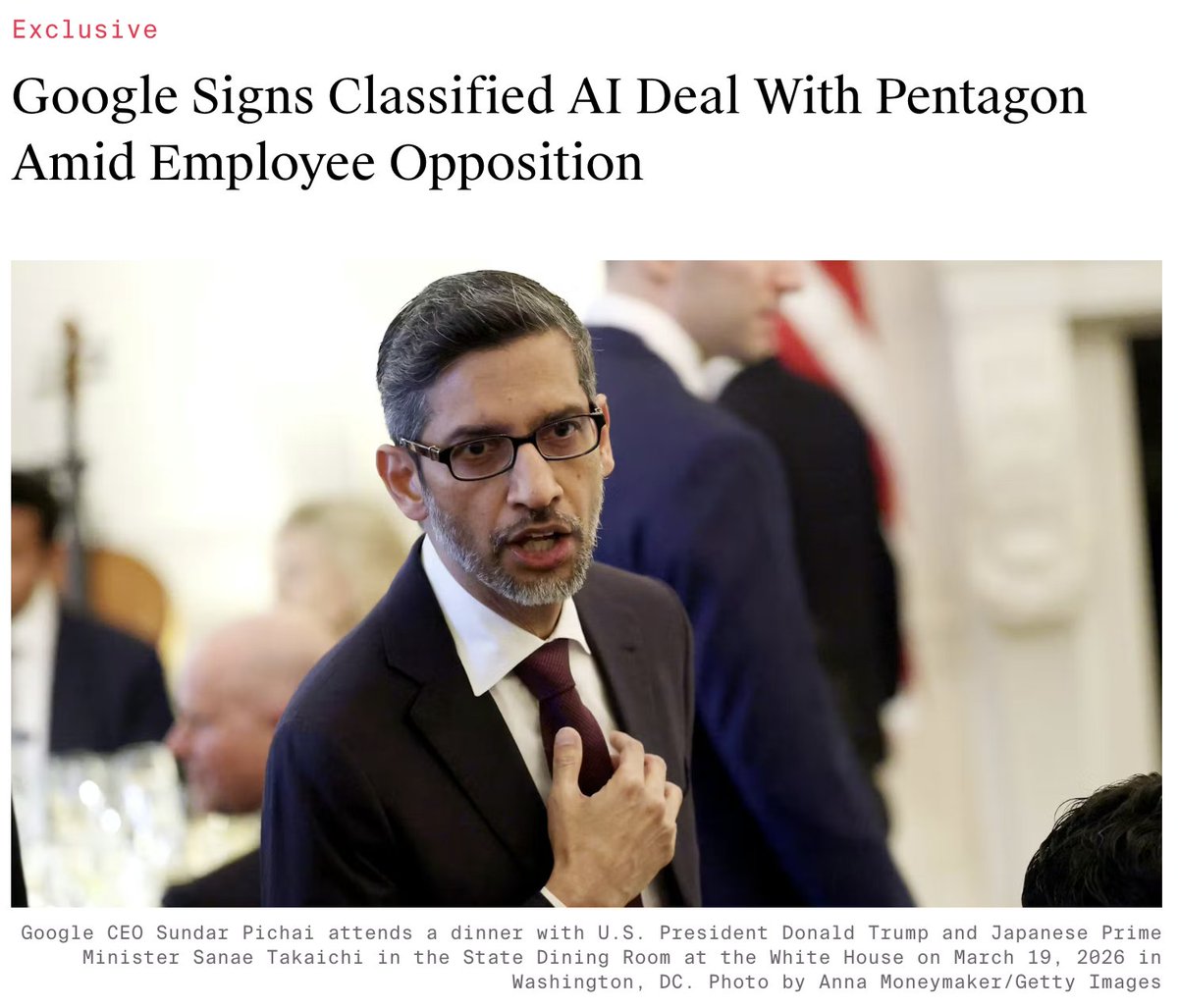
I'm speechless at Google signing a deal to use our AI models for classified tasks. Frankly, it is shameful.
For HR, I'm not speaking on behalf of Google but in my personal capacity, quoting public information from a well-sourced article of a reputable publication
As far as I can tell, the full extent of your support for "strong" regulation to mitigate catastrophic AI risk in this op-ed consists of the two paragraphs in the screenshot below. That is:
* Congress should preempt all existing state regulation on AI risk, including excellent bills such as SB 53 in California or the RAISE Act in New York.
* In exchange for getting rid of all existing and future state regulation on these risks, there should be some kind of federal framework with "serious oversight", so long as industry leaders approve of it.
Does "serious oversight" mean transparency about internal models? Does it mean conducting evaluations for CBRN misuse? Strong guarantees on model weight security? Large investments into interpretability research? Third-party auditing regimes for safety cases? KYC requirements for sufficiently capable models? Strong whistleblower protections? Corporate governance requirements?
LTF doesn't appear to be particularly concerned with figuring out such details so far. I'd be thrilled to see your PAC advocate for strong national regulation, with a detailed plan for the kind of regulatory environment you think would adequately mitigate existential risk from this technology and why, but I'm sure not seeing it yet.
Leading the Future is leading the race-to-the-bottom by leaps and bounds. Everyday I see laudable announcements by OAI's real staff (those actually building stuff), which are tragically buried by the misdeeds of its Global Affairs team. Please just put an end to this to nonsense.
This guy dumped pre-IPO anthropic equity and moved across the continent to serve his country, and was rewarded by his country with a punch in the face. It would be blackpilling if I weren’t so sure that the market will make better use of Collin than the bureaucrats ever will.
I'm genuinely heartened/encouraged that this is your experience and I believe you that this is what you see across your interactions with teams at OpenAI.
I realize i'm a bit of a broken record here but I think its worth repeating that I do not see this level of seriousness/weight and care in my interactions with the OpenAI global affairs team in the policy space.
Its partially because I really do believe so many teams at OAI (and not just the alignment team) are understanding the stakes and taking it seriously that I feel the need to make sure that I convey that this is not reflected in the side of what I see for policy/lobbying engagement on a day to day basis (which looks much more like a typical reflexive company doing typical reflexive company things, and sometimes worse than that).
Insofar as there is genuine change here as the tech becomes more capable (and that change becomes visible on the policy engagement side as well) few things would make me happier.
I like Chris, but I really disagree with the positions presented in this article.
I believe our job in the AI industry isn't just to explain why AI will be good for people. I believe our job should be to earn trust by making the benefits real, being honest about risks and uncertainty, sharing what we learn, measuring real-world impacts, and supporting public oversight and resilience.
And while I of course agree that the recent violence is terrible, unjustified, and may have been encouraged by a small number of bad actors, I think it’s bad for the public discourse to lump all AI critics together as “doomers” and suggest that it’s inappropriate for them to express their concerns.
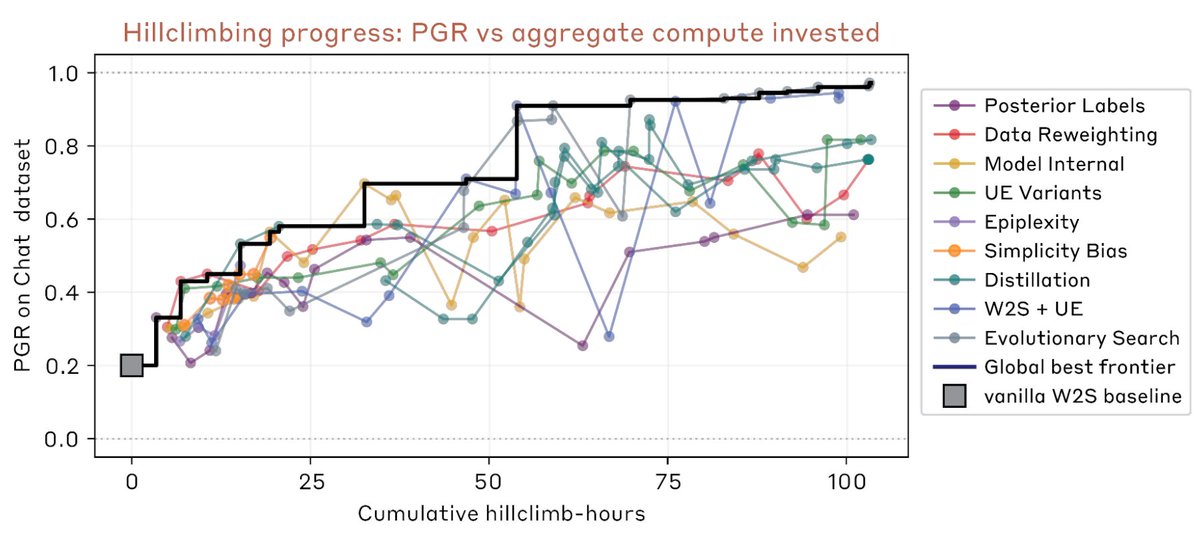
New research result: we use Claude to make fully autonomous progress on scalable oversight research, as measured by performance gap recovered (PGR).
Claude iterates on a number of different techniques and ends up significantly outperforming human researchers for $18k in credits.
Hard to think of a more clear cut case of OpenAI being in the wrong… they should just reverse positions here and figure out how anyone could have ever thought this was OK, simple as that