🤖Do you know what AI agents are? Jill Kenney and the team at Sundae Bar do.
That’s why we’re excited to announce that their cutting-edge AI agent business has just listed on the London Stock Exchange’s AIM platform.
Read more about the business: https://t.co/aZHEHYqBn3
@QuibbleUK Sonic safetyism – “See it, say it, sorted” 50x per train journey, the jarring HGV reversing squawk (apparently it’s easier to perceive where the vehicle is vs a beep) and trains/buses re-announcing where it’s going at every single stop
Capex from the big five hyperscalers (AMZN, MSFT, GOOGL, META, ORCL) will cross $1T by next year. And $8T cumulative by 2031. Hiding inside that bet is AI's biggest moment.
@bdeeter and @silicon_samuel break down the possibility. ⤵️
https://t.co/1gIlIkLEbT
“If AI produces huge efficiency gains then there will be a surge in consumer spending and capital investment because prices will FALL. This means SAVINGS will RISE.”
"Mass displacement" of workers in a growing economy is not a problem. After WWII, millions of men left military service and started looking for private sector work. The result was not impoverishment but an economic boom.
This was entirely predictable. Labor is an asset. The influx of new workers into the post-WWII economy meant new lines of production could come into being and old ones could lower costs and expand operations.
If AI produces huge efficiency gains then there will be a surge in consumer spending and capital investment because prices will FALL. This means SAVINGS will RISE.
Those savings will serve as the foundation for new jobs and growth.
When demand for workers is strong, there are powerful incentives for job training, relocation funding, etc. in order to meet the market demand for labor.
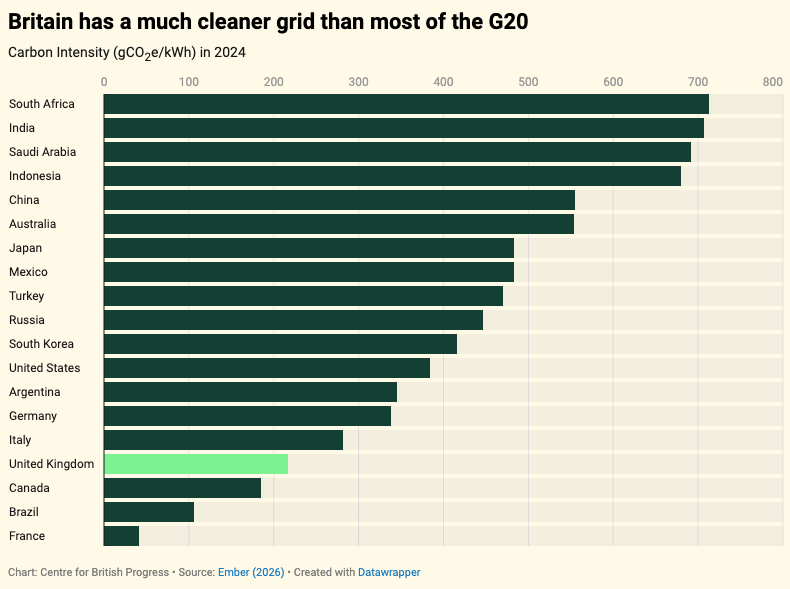
What is the climate impact of data centres?
The answer depends on where you are.
In a new report, @freddieposer & I find that Britain is one of the greenest places in the world to build data centres.
Why is this? Because the UK has made greater strides towards decarbonising the grid than the vast majority of advanced economies.
This matters, because global data centre demand is highly mobile and inelastic. If a data centre isn't built here, it is likely to be built in Germany, the US or Ireland – which would all counterfactually produce more emissions.
Very interesting analysis of the UK’s productivity issues:
- pre-1975 we spent an equal amount (6% of GDP) on building public infrastructure as we did on entitlements (pensions, benefits)
- post-1975 we shifted spending to 10% on entitlements vs 2% on investment
- because public investment increases productivity, the counterfactual world in which we had kept spending at 6% on each implies a 1.6% annual loss in foregone productivity growth
- this works even if you are agnostic as to whether entitlements may also reduce productivity (ie. more generous benefits = less incentive to work)
- this gets you to their figure of the median wage being £65k rather than the £35k it is today
The average British salary should be £65,000.
It's £34,000.
Fifty years of political failure.
One plan to fix it.
The SDP's Investment State documentary, out now:
NEW: Natural England are set to delay Hinkley Point C by insisting on even more measures to protect fish.
A two-year delay to Hinkley Point C Unit 1 would mean about 24TWh less clean firm power on the grid, between 2-4bn cubic metres more gas burnt, and between 4-8m tonnes of CO2 into the atmosphere.
Even though EDF have spent £700m on fish protection, including a £50m acoustic fish deterrent that is 93% effective, regulator Natural England wants them to do even more.
This is likely to involve creating a salt marsh on nearby farmland. This could take years.
https://t.co/w2qfze7Vxy
$TAO community 🍨
Anyone building with Cursor, Claude, Lovable, Bolt, Replit etc?
We are looking for people to test our latest agent, Crumble - an autonomous security review agent for AI-generated code.
Crumble sits inside your GitHub workflow and reviews pull requests, branches, and code changes before deployment.
Basically for everyone who became a senior engineer overnight and might be unknowingly shipping vulnerabilities into prod ;)
Simple to run.
Really useful.
Comment “SN121 $TAO” below and we will DM you a scan credit.
Sanders and AOC introduced a bill to pause ALL AI data center construction. 300+ local bills filed. Half of planned 2026 data centers facing delays or cancellation. Each one brings billions to local economies.
The people who say they want American jobs are trying to block the biggest job creation engine since the interstate highway system.
ppl are so overly negative about the UK vs reality.
- 4 of top 10 universities globally
- third largest VC market globally behind only USA, China. 1/3 of all VC in europe
- powerhouse in creative industries - second largest music exporter in the world
- largest biotech ecosystem in europe - massive growth sector in the coming years
- London is the top western hub for AI after Silicon Valley.
- excellent financial services base and broader services economy. Number one for FX, number two for PE and Hedge Funds
- produces 20% of global offshore wind
TLDR UK is overwhelmingly a top 3 or top 5 player globally across finance, law, defence, biotech, clean energy, creative industries, and tech (especially AI)
We are incredibly well positioned for the future.
We have a number of problems we need to fix - I believe we will do so.
Extremely bullish on this country
The UK is already seeing the benefits of being an AI hub. But we’re not doing a good enough job of explaining the opportunity ahead.
I wrote for @thetimes today on being an ambitious nation again - and the need to fight the AI doomers.
We had similar opportunities in the internet era, but failed to seize on them. We can’t miss again.
The thesis is simple: the future belongs to individuals who build compounding AI systems, not to individuals who use corporate-owned centralized AI tools.
I'm trying to build these in open source so you can have them for free. That's what GBrain is.
Inference got a hundred times cheaper this year. The compute bill went up anyway.
If you understand why those two sentences are both true at the same time, you understand the most important thing happening in AI right now.
I work on inference for a living, at @nebiustf, where we run open-source managed inference at scale. Most of what follows is what I'm seeing from inside the bill.
12 months ago, the cost of 1M tokens of frontier-class reasoning was somewhere on the order of $60.
Today, an equivalent quality of output costs roughly $0.50.
Price /token of o1-level intelligence has dropped about a 128x in a year.
Price of GPT-4-level output has dropped roughly 100x since the original GPT-4 shipped.
By any normal reading of a technology cost curve, this should be deflationary. It should be saving customers money.
The opposite has happened. The total compute bill at every hyperscaler is going up, not down. Anthropic just signed multi-year capacity deals with both XAI and Amazon. Microsoft's Azure capex guide for 2026 starts with an eight. OpenAI is reportedly spending more on compute every quarter than it did in all of 2023. Nvidia paid roughly twenty billion dollars to acquire Groq, an inference-specialist company that did not exist as a serious commercial entity three years ago.
The cost curve and the demand curve crossed, and then the demand curve lapped the cost curve.
Here is what happened underneath.
A reasoning model burns roughly 10x the output tokens of a non-reasoning model on the same task, because it spends most of its tokens thinking out loud before answering. An agentic workflow chains roughly twenty times the requests of a single-shot completion, because it loops, calls tools, plans, retries, and synthesizes. A modern deep-research query (the kind a research analyst can fire off in fifteen seconds and then walk away from for ten minutes) costs more compute than 10 original GPT-4 queries combined. We made every individual token a hundred times cheaper, and then we built a generation of products that consume ten thousand times more tokens.
This is the Jevons paradox playing out at trillion-dollar scale, in compressed time, in front of everyone. Jevons noticed in 1865 that making coal-burning more efficient did not reduce coal consumption. It increased it, because efficiency unlocked uses that were previously uneconomic. Steam engines became more practical at smaller scales. Whole industries that could not afford coal at the old price suddenly could. Britain's coal consumption rose sharply, not despite the efficiency gains, but because of them.
The same thing is happening to AI compute right now and it is happening faster than any analogous historical cycle. Falling token prices did not contract demand. They unlocked agents, deep research, code-writing systems, multi-step reasoning, persistent memory, the entire next layer of AI products. Every product in that next layer consumes orders of magnitude more compute than the chat interfaces it is replacing.
The math at the aggregate level is brutal: 100x cheaper tokens times 10 000 more tokens equals a 100x larger total bill.
The implications stack quickly.
If you are running a hyperscaler, your 2026 capex guide is not a peak. It is a step on a curve. Inference is structurally always-on, twenty-four hours a day, in a way that training never was. Training is bursty. You spin up a cluster, run for weeks or months, and stop. Inference runs continuously, scales with usage, and the usage curve is exponential. Your power bill, your cooling bill, your transceiver count, your storage footprint, all of these were sized for a workload mix that no longer exists.
If you are running an AI software company built on top of someone else's closed API, you have a problem that did not exist a year ago. Your gross margins get worse as your customers get more value out of your product, because the more they use it, the more compute you pay for. The companies that win this are the ones that figured out vertical integration before the math caught them.
If you are watching this from a distance and trying to understand where the next bottlenecks form, the answer is everywhere downstream of "more inference compute, always-on, with massive memory state per session." The KV cache, the running memory state of a long conversation or an agent loop, is the silent monster of the inference era. It does not scale linearly with parameters. It scales linearly with context length and number of agent steps. A long agent session can hold tens of gigabytes of state per user, per session.
Multiply that by every concurrent user of every product, and you understand why $MU, $SNDK, $TOWCF, and the entire memory and packaging layer have re-rated the way they have.
The CPU-to-GPU ratio is evolving. Training is 1:8. Basic chat inference is 1:4. Agentic inference is 1:1, sometimes CPU-heavy. Google has split its TPU line in two, with a dedicated inference chip carrying tripled SRAM for KV cache. $INTC and $AMD just spent two earnings calls explaining that this shift is structural, not cyclical. The hardware map is redrawing in real time and the financial press is mostly still writing about training clusters.
The right framing of where we are right now is not that AI is hitting a wall. The framing a year ago that scaling was hitting a wall was the most expensive bad take of the cycle. The right framing is that AI got dramatically cheaper, dramatically more capable, and dramatically more useful, and the cost of running it at the new equilibrium of demand is much higher than the cost at the old equilibrium of demand, because the new equilibrium is enormous.
A meaningful share of what we actually do at Token Factory, day to day, is help customers stop their bills from running away from them. KV-cache management. Speculative decoding. Quantization. Routing. The kind of vertical integration that, eighteen months ago, every product team was happy to leave abstracted away behind a closed API. The reason this stack matters now is the same reason this whole essay matters: at the new equilibrium of inference demand, the cost of treating compute as a commodity is no longer survivable. The companies that figure out the layer beneath the API are the ones who keep their margins.
Cheaper tokens. More tokens.
Same coal as 1865.
Future companies will be measured in million tokens per second per share. MTPS per share. Your share is your claim on finite inference capacity.
GPUs are limited. Power is limited. Tokens per second is the measurable output. But not all tokens are equal. A frontier model token isn’t the same as a 7B token. So you adjust for quality, turning tokens into a fungible unit.
That creates the economic shift. Companies compete on real constraints: more intelligence per watt, more throughput per chip, more capability per token. It’s about extracting as much intelligence as possible from fixed hardware. Shareholders own that capacity. It starts to look like reserves in an intelligence economy, with equity pricing in future intelligence output.
In the short term, token prices get compressed. Providers undercut each other to win market share. Volume explodes, but margins shrink. The market share acquisition phase. Then the lock-in kicks in. Agents get embedded in workflows. Memory builds up. Models are tuned on proprietary data. Switching gets painful.
At the same time, demand goes vertical and runs into hard limits: power and compute. That’s when prices turn. Token costs start rising fast. MTPS per share behaves like energy reserves in a supply crunch.
The value of human intelligence drops. Basic cognition becomes ambient. Seven billion humans versus seven billion agents. Knowledge work collapses into tokens.
Humans move back to the physical layer. Hands, sites, machines. Actuators for tokenised intelligence. The robots, directed by AI. Intelligence becomes abundant. Orchestration of the physical world becomes the bottleneck.