Entrepreneur, #AI, #LLM, #NLP. Ingénieur en informatique, docteur en linguistique. Fondateur de Proxem, acheté par Dassault Systèmes en 2020. Opinions are mine.
Je suis très heureux de pouvoir annoncer aujourd’hui l’achat de @proxem par @Dassault3DS. Nous avons été pionnier en France sur l’utilisation concrète du machine learning pour le NLP/NLU en le mixant avec les approches classiques.
https://t.co/meTXae4Th3
We invited Claude users to share how they use AI, what they dream it could make possible, and what they fear it might do.
Nearly 81,000 people responded in one week—the largest qualitative study of its kind.
Read more: https://t.co/tmp2RnZxRm
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
Les chats d'IA, nouvelle rupture d'usage, désormais à 20mn d'usage quotidien.
De la même ampleur, en plus rapide que l'avènement du cloud ou du smartphone.
Tired: elaborate docs pages for your product/service/library with fancy color palettes, branding, animations, transitions, dark mode, …
Wired: one single docs .md file and a “copy to clipboard” button.
Mario Draghi : "Le RGPD et l'absence de cloud souverain sont des freins à la compétitivité européenne"
l'absence de cloud souverain
l'absence de cloud souverain
l'absence de cloud souverain
l'absence de cloud souverain
l'absence de cloud souverain
l'absence de cloud souverain
l'absence de cloud souverain
@Do20489981 Bonjour Do, juste par curiosité : vous avez eu des nouvelles depuis ? (j'ai passe une commandé le 12 juillet... pas de nouvelles depuis... Emma matelas semble très en retard, j'ai appelé le service client aujourd'hui qui m'a assuré faire de son mieux)
Je déteste en arriver là et c'est même la première fois que je fais ça mais au bout d'un moment, il faut pas déconner. Ce n'est d'ailleurs pas pour moi car cela concerne les deux plus belles personnes de notre monde.
CANAL+, HONTE A VOUS !
@InfoAbonneCanal@canalplus
Today is a good day for open science.
As part of our continued commitment to the growth and development of an open ecosystem, today at Meta FAIR we’re announcing four new publicly available AI models and additional research artifacts to inspire innovation in the community and help advance AI in a responsible way. More in the video from @jpineau1.
What we’re releasing:
🦎 Meta Chameleon
7B & 34B language models that support mixed-modal input and text-only outputs.
🪙 Meta Multi-Token Prediction
Pretrained Language Models for code completion using Multi-Token Prediction.
🎼 Meta JASCO
Generative text-to-music models capable of accepting various conditioning inputs for greater controllability. Paper available today with a pretrained model coming soon.
🗣️ Meta AudioSeal
An audio watermarking model that we believe is the first designed specifically for the localized detection of AI-generated speech, available under a commercial license.
📝 Additional RAI artifacts
Including research, data and code to measure and improve the representation of geographical and cultural preferences and diversity in AI systems.
We believe that access to state-of-the-art AI creates opportunities for everyone – not just a small handful of Big Tech companies. We’re excited to share this work and to see how the community learns, iterates and builds using this technology.
Details and access to everything released by FAIR today ➡️ https://t.co/aMY8d2qrTd
We are announcing €600M in Series B funding for our first anniversary. We are grateful to our new and existing investors for their continued confidence and support for our global expansion. This will accelerate our roadmap as we continue to bring frontier AI into everyone’s hands.
Donc si on comprend bien, tout pdf ouvert avec Acrobat Reader peut voir son contenu utilisé par Adobe… c’est le moment de passer aux alternatives (Aperçu sur Mac est très bien).
L’ogre a faim disait une amie chercheuse à propos de l’#ia et des data voilà quelques années.
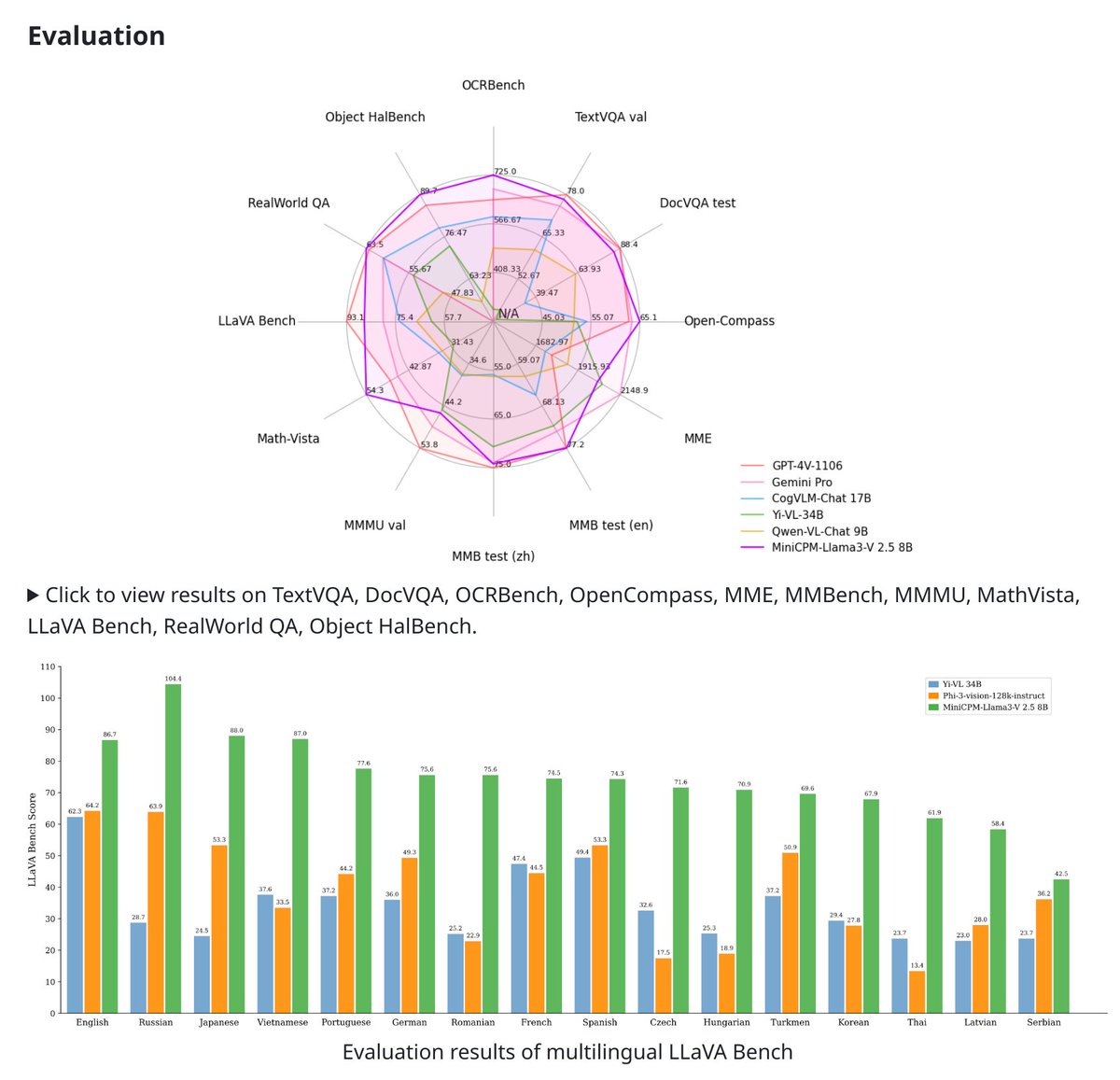
The "fun" part is that such good model actually exists, it's MiniCPM-Llama3-V 2.5.
But, MiniCPM got a lot less attention, incl from me.
Given the similar results, the main reason seems to be not coming from an Ivy-league Uni, but from a Chinese lab?
Bad look for all of us...
We trained a robot dog to balance and walk on top of a yoga ball purely in simulation, and then transfer zero-shot to the real world. No fine-tuning. Just works.
I’m excited to announce DrEureka, an LLM agent that writes code to train robot skills in simulation, and writes more code to bridge the difficult simulation-reality gap. It fully automates the pipeline from new skill learning to real-world deployment.
The Yoga ball task is particularly hard because it is not possible to accurately simulate the bouncy ball surface. Yet DrEureka has no trouble searching over a vast space of sim-to-real configurations, and enables the dog to steer the ball on various terrains, even walking sideways!
Traditionally, the sim-to-real transfer is achieved by domain randomization, a tedious process that requires expert human roboticists to stare at every parameter and adjust by hand. Frontier LLMs like GPT-4 have tons of built-in physical intuition for friction, damping, stiffness, gravity, etc. We are (mildly) surprised to find that DrEureka can tune these parameters competently and explain its reasoning well.
DrEureka builds on our prior work Eureka, the algorithm that teaches a 5-finger robot hand to do pen spinning. It takes one step further on our quest to automate the entire robot learning pipeline by an AI agent system. One model that outputs strings will supervise another model that outputs torque control.
We open-source everything! Welcome you all to check out the paper, more videos, and try the codebase today: https://t.co/RwiBT3z78H
Code: https://t.co/ERp4Gl0N36
One thing that even relatively senior ML people often fail to grasp is that deep learning models are curves fitted to a data distribution. You cannot expect them to solve tasks outside of their training distribution (which is the sort of thing that you need intelligence for).
"Emergent learning" is an incorrect label -- if a model demonstrates performance on task A that it wasn't trained on, that simply means that there is significant overlap between A and all the data that you did train on. Competence doesn't magically emerge out of nowhere.
As long as AI systems are trained to reproduce human-generated data (e.g. text) and have no search/planning/reasoning capability, performance will saturate below or around human level.
Furthermore, the amount of trials needed to reach that level will be far larger than the amount of trials needed to train humans.
LLMs are trained with 200,000 years worth of reading material and are still pretty dumb.
Their usefulness resides in their vast accumulated knowledge and language fluency. But they are still pretty dumb.
🥁 Llama3 is out 🥁
8B and 70B models available today.
8k context length.
Trained with 15 trillion tokens on a custom-built 24k GPU cluster.
Great performance on various benchmarks, with Llam3-8B doing better than Llama2-70B in some cases.
More versions are coming over the next few months.
https://t.co/EkU9aIHdZE
I have been working on vision+language models (VLMs) for a decade.
And every few years, this community re-discovers the same lesson -- that on difficult tasks, VLMs regress to being nearly blind!
Visual content provides minor improvement to a VLM over an LLM, even when these are questions about visual content. Language does not contain the answer, only vision does.
Why? Because language provides easy priors about the world and "seeing" is hard.
Doesn't matter if the VLM is GPT-4V or Claude or Gemini.
Always happy to burst the bubble of hype!