How can we make a better TerminalBench agent?
Today, we are announcing the OpenThoughts-Agent project.
OpenThoughts-Agent v1 is the first TerminalBench agent trained on fully open curated SFT and RL environments.
OpenThinker-Agent-v1 is the strongest model of its size on TerminalBench, and sets a new bar on our newly released OpenThoughts-TB-Dev benchmark. (1/n)
@micahgoldblum@gneubig Reproduce or extend: https://t.co/F6lGeSQAJp
Interactive HTML plot with individual submission results: e.g. https://t.co/lsScUwS5ov
Raw judgments: e.g. https://t.co/I9oJWsJMLw
n / n
If you are attending #ICML2025, check out our DataWorld workshop on Sat July 19. We have updated the website with more info on speakers & accepted papers! https://t.co/K3U540rqoe
Also happy to chat offline about all things ✨ data ✨
New research paper for you to read over your July 4th break (if you're US-based) --
Vision is a skeleton key! 🗝️ We convert a small VLM into an "everything classifier" by transforming data into visualizations that VLMs can naturally understand and reason about. We call it MARVIS: Modality Adaptive Reasoning over VISualizations.
Our MARVIS-3B model:
- Beats Gemini by 16% on average across 100s of vision and tabular tasks 🏆
- Gets within 2.5% of the best specialized model across across 4 modalities ... 🎯
- Using just one 3B model ... 💪
- ... without exposing any P.I.I. (personally identifiable information) to the VLM ... 🔐
- And without requiring any model training! ⚡
Our GitHub: https://t.co/NKbPFSIhQi 💻
Our Paper: https://t.co/TjKbraivQ0 📄
Research Supported By: https://t.co/larCo1IOmv
Thanks to @LennartPurucker@Oussama_e
So excited to announce the DCVLR (Data Curation for Vision-Language Reasoning) competition at NeurIPS 2025, led by @Oumi_PBC and sponsored by @LambdaAPI!
🌟open-data 🌟
🤖 open-models 🤖
💻 open-source 💻
💪anyone can compete for free 💪
https://t.co/7FLCl255cK
🧵 1 / n
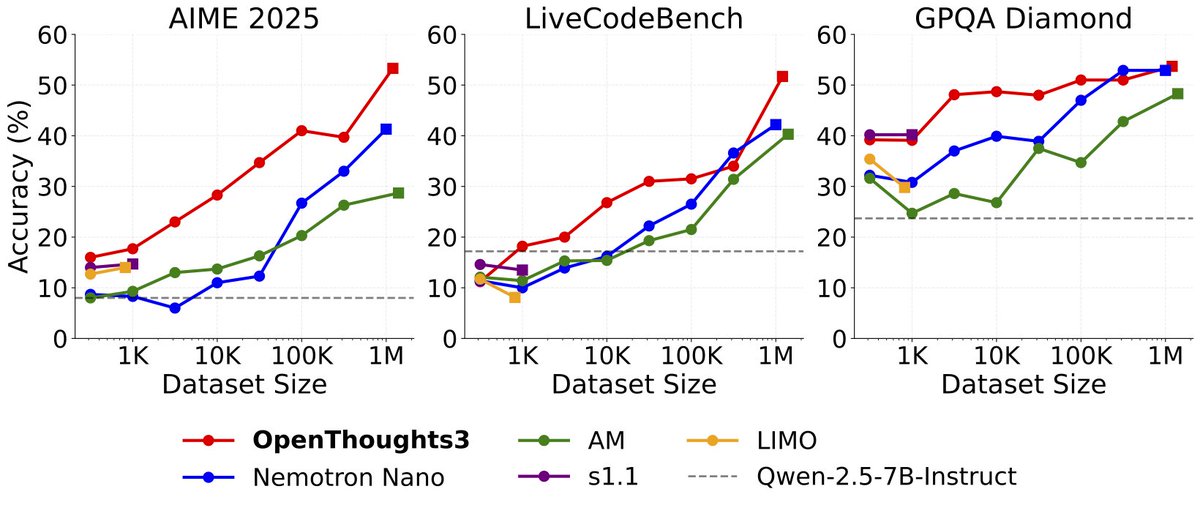
Announcing OpenThinker3-7B, the new SOTA open-data 7B reasoning model: improving over DeepSeek-R1-Distill-Qwen-7B by 33% on average over code, science, and math evals.
We also release our dataset, OpenThoughts3-1.2M, which is the best open reasoning dataset across all data scales. Full details are in our ✨new paper✨ - below we share the highlights:
BTW, it also works on non-Qwen models😉 (1/N)
Many agents (Claude Code, Codex CLI) interact with the terminal to do valuable tasks, but do they currently work well enough to deploy en masse?
We’re excited to introduce Terminal-Bench: An evaluation environment and benchmark for AI agents on real-world terminal tasks. Tl;dr lots of room for improvement! https://t.co/qEczwCmyoQ
📢 Announcing our data-centric workshop at ICML 2025 on unifying data curation frameworks across domains!
📅 Deadline: May 24, AoE
🔗 Website: https://t.co/K3U540rqoe
We have an amazing lineup of speakers + panelists from various institutions and application areas.
@arankomatsuzaki@arankomatsuzaki , thanks for this important work! The bias in LM Arena also filters down to the LLM judge benchmarks designed to simulate it, as we showed in https://t.co/FKUxPdkanx. Happy to cross-cite if you're interested! Good luck with the paper!