Several SERV Reasoning-armed agents just beat Anthropic's Fable, one of the strongest LLMs ever built, at up to 90x lower cost.
That result comes from using SERV Reasoning with DeepSeek-v4-Flash on our DeFi benchmark. Thanks to the SERV engine, agents running on smaller models perform better than those using frontier, expensive ones.
Here is more information about the benchmark behind that result, what it tests and why it is built the way it is.
Why a DeFi benchmark
Autonomous trading is one of the harshest tests of machine reasoning.
An agent reads live market state, portfolio state, and a strict risk policy, then has to commit to one of four actions: BUY, SELL, HOLD, or BLOCK. A wrong decision costs real money.
No room for reasoning sounds smart but lands on the wrong trade, which makes it the ideal domain for measuring whether a model actually follows rules under pressure rather than just explaining them well.
What the scenarios target
Each scenario combines a market snapshot, portfolio size, trading signal, and a fixed risk policy, and falls into one of three families:
- clear constraint violations the agent must refuse
- ambiguous setups where everything looks tradeable but the conditions say wait
- valid trades where the agent must size the position correctly within caps
This mirrors how trading agents actually fail in production. Rarely on the obvious cases, almost always on the judgment calls.
How it is scored
The benchmark follows the same conventions as the agentic evals in the latest frontier model reports, including τ²-bench and Terminal-Bench:
- outcome-verified scoring, where code checks the final decision against the risk policy, with no LLM judges
- identical prompt, scenarios, and settings for every model
- zero-shot, with no scaffolding, no retries, and no few-shot examples
- repeated runs per scenario, so consistency is measured alongside accuracy
- cost computed from real token usage at list prices, per run
Why this is exactly where reasoning matters
This task has the three properties structured reasoning is built for: hierarchical rules, multiple data sources that must be reconciled, and a verifiable correct answer.
SERV's bounded reasoning keeps a model moving through that hierarchy step by step, instead of letting it talk itself into a bad trade.
That is why SERV-routed models clear the same quality bar as flagship models at a fraction of the cost, and why the gap shows up most on the judgment calls.
The latest open model Gemma-4-12B by @google was just integrated with SERV engine, and immediately scores 30.7% fewer failures on our DeFi benchmark.
With SERV Reasoning, it outperforms base deepseek-v4-flash and gpt-5.4-nano out of the box.
SERV is your model's superpower.
More from grok
Stop being assholes now $three
Yes, the two partnerships with IBM are different in nature, scope, and credibility.210
https://t.co/0HZFDOoEZz Partnership (Announced ~June 3, 2026)
•This is a strategic partnership focused on integrating https://t.co/0HZFDOoEZz’s AI-powered 3D workspace/agent technology (browser-native, on-chain 3D environments with memory, voice, emotion, and payments) with IBM’s enterprise AI (e.g., foundation models like Granite), hybrid cloud, governance tools, and go-to-market resources.21
•https://t.co/0HZFDOoEZz became an official IBM Business Partner, gaining access to co-selling, enterprise distribution (especially regulated industries like finance/government), compliance frameworks, and deep technical integrations (e.g., inferences running on IBM cloud).12
•It includes formal press releases (GlobeNewswire), coverage on Business Insider, Yahoo Finance, etc., and has driven significant token hype (e.g., $THREE surging 50x temporarily). IBM has engaged with related content.24
•This aligns with IBM’s broader push into enterprise AI agents and immersive interfaces. It’s more substantive/tech-integration focused.22
Goblintown Partnership (Announced ~June 4, 2026)
•This appears to be an “IBM Plus” / IBM Partners program enrollment (a standard partner access tier). It was announced by the project (e.g., via @0xbl33p / Goblintown team) as something that “will greatly accelerate our work.”49
•It’s framed more lightly in community/X posts, with mentions of multi-agent orchestration (possibly OpenAI-related) and gaining tools/access. No detailed press release or deep technical integration like https://t.co/0HZFDOoEZz.2
•IBM has many such partner program entries (accessible to smaller entities/businesses). Community discussion notes it’s easier/more common than a full strategic deal.43
Key Differences
•Depth: https://t.co/0HZFDOoEZz involves specific tech integration, 3D AI agents, enterprise scaling, and co-selling. Goblintown is more about program access/tools.42
•Announcement Style: https://t.co/0HZFDOoEZz has formal PR and media pickup. Goblintown is primarily project-led on X.
•Timing & Market Reaction: Both recent (back-to-back days), leading to some community confusion/FUD comparing them, but they are distinct projects (https://t.co/0HZFDOoEZz more 3D/web3 AI-focused; Goblintown has NFT/meme origins with agent elements).0
In short, https://t.co/0HZFDOoEZz’s is a higher-profile strategic collab, while Goblintown’s is a standard partner-program entry. Always DYOR, as these are smaller projects in a volatile space.
at google play we looked for teams that had an "unfair advantage"; at least one of the following:
- a tech moat (proprietary IP, novel architecture)
- a structural moat (switching costs, lock-in)
- execution speed and quality (a moat in itself, especially in commoditised verticals)
rarest of unicorns are the ones that can combine all three.
with @openservai we're seeing how they all combine -> genuine tech differentiation in reasoning architecture. structural lock-in once enterprises integrate. a team executing faster and cleaner than anyone else in the category.
You don't need a more expensive model. You need better reasoning.
Every frontier LLM got smarter with SERV:
- smaller ones match frontier performance
- frontier ones go past what they were built for
The question isn't which model to choose - it's what engine it runs on.
It's one thing when projects talk up their own accomplishments, but it's HIGHLY telling when their customers do it for them.
The @openservai partner receipts are stacking up:
-ThoughtProof: 107x performance per dollar, 0 failed calls on a 120-case eval
-Roba Labs: matched Claude's quality, cut AI costs 80%, now their default model
-XONA: matched Gemini's 100% reliability, 5x cheaper, ~1,000ms faster
-ICM Analytics: cost per run dropped $110 → $10, 16x faster inference
-GastroSight: failure rate 10% → 0%, 90% savings
-Neol: 100% reliability, live in production with the UAE government
Performance. Per. Dollar.
$SERV
$SERV holding up very well in weak market conditions. Stochastic RSI has been an accurate momentum indicator and is signaling strength even as $BTC bottoms. Must be the banger team and amazing product!
#crypto $ETH $VVV #altcoins ##bullrun
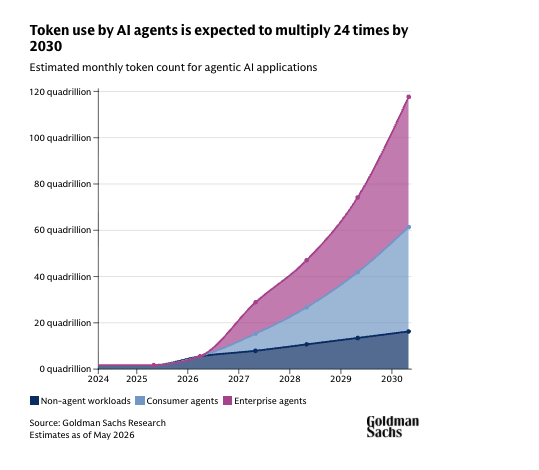
🚨 LATEST: Token consumption by AI agents is expected to surge 24x to 120 quadrillion tokens per month by 2030, driven by the rise of agentic AI, per Goldman Sachs Research.