Midtraining is a new part of many training pipelines, but when does it help and can it backfire? 🤔
In our new preprint, we use controlled experiments to pin this down. TL;DR; midtraining helps the most when it “bridges” pretraining and posttraining, and mitigates forgetting after posttraining. Timing is also very important.
🧵
Most people use Claude Code like a chatbot.
So I documented the most complete setup you can install today.
Inside:
→ How to run 10 to 15 Claude sessions at the same time across terminal and browser
→ The CLAUDE. md file that writes its own rules after every correction so the same mistake never happens twice
→ Plan Mode workflow so Claude builds a full plan before touching a single file (with the exact activation steps and what to say)
→ How to actually use slash commands for every task you repeat more than once a day
→ Subagent setup so Claude reviews, simplifies, and verifies its own work without you managing it
→ The verification loop that produces 2 to 3 times better output on every task
→ Safe permissions setup so Claude never needs unrestricted access to your machine
→ MCP connections for Slack, BigQuery, and Sentry so Claude uses your tools directly
→ PostToolUse hooks so code formatting never causes errors in review
→ Ready to use files including CLAUDE. md, subagents, slash commands, and hooks
→ Common mistakes that slow Claude Code down and the exact fixes Boris uses
If you build with AI daily, ship code, or manage a team using Claude Code - this is the only setup guide you will need.
Comment "CLAUDE" and I will send it straight to your DMs.
Many people are using RL to make models smarter.
We used RL to pull training data out of the models themselves.
Our results show that models know a lot more about their training data than most people think.
We develop Active Data Reconstruction Attack (ADRA) — a data detection method that uses RL to induce models to reconstruct data seen during training.
ADRA beats existing methods by an average of >10% across pre-training, post-training, and distillation.
Our paper, with @uwnlp, @Cornell, and @BerkeleyNLP @Berkeleyai, is now available.
Arxiv: https://t.co/B9B63vFm5P
Joint work with @jxmnop@shmatikov@sewon__min@HannaHajishirzi
Holy shit... Someone just gave Claude Code a complete software development brain.
It's called Superpowers and it makes Claude plan, test, and ship code without going off the rails.
No junior dev babysitting. No context loss. No hallucinated plans.
100% Opensource.
😱Anthropic isn’t just building chatbots
They’re building a system that can think, code & execute
And most people are using it wrong.
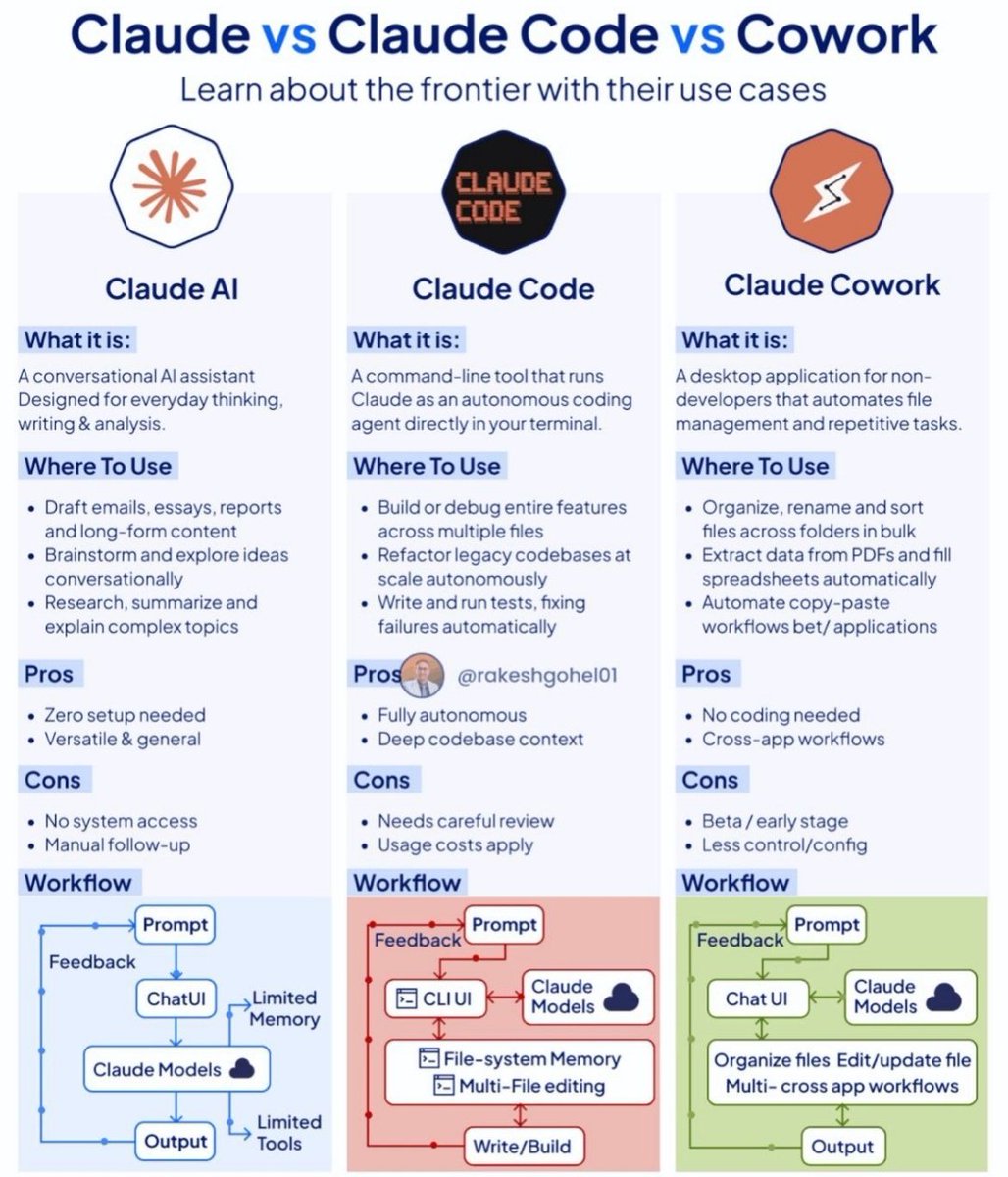
There are actually 3 different Claudes — and each one replaces a different type of work:
1. Claude AI → replaces Google + docs + junior research
• Writing, thinking, summarizing, ideation
• Zero setup, pure conversation
2. Claude Code → replaces hours of engineering work
• Reads your entire codebase
• Edits multiple files
• Writes, debugs, and runs tests autonomously
3. Claude Cowork → replaces repetitive computer tasks
• Renames, organizes, and edits files in bulk
• Extracts data from PDFs → spreadsheets
• Automates cross-app workflows
Simple rule:
• Thinking → Claude AI
• Building → Claude Code
• Doing → Claude Cowork
Most people only use the first.
The leverage is in the other two
I have been building and operating Agentic AI Systems for the past few years and the same patterns keep emerging. 👇
𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗗𝗿𝗶𝘃𝗲𝗻 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁 is the most reliable way to be successful in building your 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗦𝘆𝘀𝘁𝗲𝗺𝘀 and continue improving them - here is my template.
Let’s zoom in:
𝟭. Define a problem you want to solve: is GenAI even needed?
𝟮. Build a Prototype: figure out if the solution is feasible.
𝟯. Define Performance Metrics: you must have output metrics defined for how you will measure success of your application.
𝟰. Define Evals: split the above into smaller input metrics that can move the key metrics forward. Decompose them into tasks that could be automated and move the given input metrics. Define Evals for each. Store the Evals in your Observability Platform.
ℹ️ Steps 𝟭. - 𝟰. are where AI Product Managers can help, but can also be handled by AI Engineers.
𝟱. Build a PoC: it can be simple (excel sheet) or more complex (user facing UI). Regardless of what it is, expose it to the users for feedback as soon as possible.
𝟲. Instrument your application: gather traces and human feedback and store it in an Observability Platform next to previously stored Evals.
𝟳. Run Evals on traced data: traces contain inputs and outputs of your application, run evals on top of them.
𝟴. Analyse Failing Evals and negative user feedback: this data is gold as it specifically pinpoints where the Agentic System needs improvement.
𝟵. Use data from the previous step to improve your application - prompt engineer, improve AI system topology, finetune models etc. Make sure that the changes move Evals into the right direction.
𝟭𝟬. Build and expose the improved application to the users.
𝟭𝟭. Monitor the application in production: this comes out of the box - you have implemented evaluations and traces for development purposes, they can be reused for monitoring. Configure specific alerting thresholds and enjoy the peace of mind.
✅ 𝗖𝗼𝗻𝘁𝗶𝗻𝘂𝗼𝘂𝘀 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁 𝗼𝗳 𝘆𝗼𝘂𝗿 𝗮𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻:
➡️ Run steps 𝟲. - 𝟭𝟬. to continuously improve and evolve your application.
➡️ As you build up in complexity, new requirements can be added to the same application, this includes running steps 𝟭. - 𝟱. and attaching the new logic as routes to your Agentic System.
➡️ You start off with a simple Chatbot and add a route that can classify user intent to take action (e.g. add items to a shopping cart).
Learn all of the practices of Eval Driven Development Hands-on in my End-to-end AI Engineering Bootcamp: https://t.co/gWBu8OLTzn
🎁 Grab your 15% discount by applying code KICKOFF15 at the check-out.
What is your experience in evolving Agentic Systems? Let me know in the comments 👇
Stop coding from scratch with agents.
This repo gives you 860+ battle-tested skills for Claude Code, Gemini CLI, Cursor, and Copilot.
It’s essentially a curated library that transforms your AI assistant from a basic chat interface into a production-ready engineering partner.
P.S. Check out 100+ such repos shared in this community of 200K+ AI/ML Engineers:
https://t.co/cSeCMfne9l
You can use it for:
→ RAG pipelines & LLM systems
→ Docker, AWS serverless, Vercel deployment
→ Security audits & vulnerability testing
→ Full-stack development patterns
→ TDD & QA automation
→ Growth, SEO, pricing strategy
…and much more!
Skills are grouped into role-based bundles (Web Dev, Security Engineer, DevOps, etc.) to help you get started quickly without manually exploring hundreds of skills.
Works across Claude Code, Cursor, Gemini CLI, Codex CLI, Antigravity IDE, GitHub Copilot, OpenCode, and AdaL CLI.
Install with one command:
npx antigravity-awesome-skills
🚨 Anthropic just open-sourced their entire playbook for building production AI agents.
It's called Agent Skills for Context Engineering and it's what their engineers actually use.
- Context fundamentals & degradation patterns
- Multi-agent architectures
- Memory systems design
- Tool design principles
- Evaluation frameworks
9.2K stars. MIT licensed. 100% Opensource.
One of the most asked topic in Java/backend interviews: CQRS(Command Query Responsibility Segragation)
Scenario: An e-commerce Order service uses one relational database for:
- high-volume order writes
- customer order lookups
- heavy sales reports
During peak traffic, reporting queries slow down order creation.
The data model is becoming complex and hard to evolve.
What’s the real problem?
PROBLEM: forced reads and writes with very different workloads to share:
- the same database
- the same schema
- the same indexes
Transactional tasks and analytical queries are coupled, so obv. they fight each other.
Then:- performance degrades and the model keeps bloating.
SOLUTION::-
- CQRS
- Separate write paths and read paths.
How it works
[Writes] (Commands):
- orders are created/updated in a normalized write database, optimized for transactions.
[Reads] (Queries):
- reports and lookups read from a denormalized read database, optimized for fast queries.
Sync mechanism:
Write events are published via a message broker and update read models asynchronously.
CQRS solves the problem of mixing transactional and analytical workloads in one model.
-----------------------
This is well discussed in my Java+Spring boot+Microservices+Design Patterns+System design ebook curated for interviews, you can check it out from here https://t.co/iH4Ung369Y
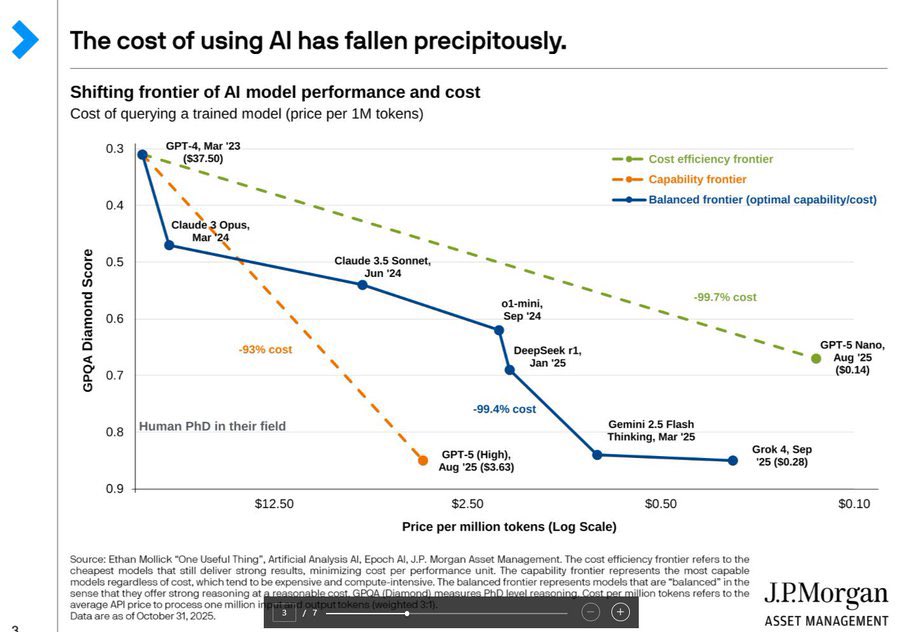
AI on a wicked race to the bottom!
Grok 4: $0.28/M tokens
Gemini 3 Flash: $0.50/M tokens
Gemini 2.5 Flash: $0.30/M tokens
Gemini 2.5 Flash-Lite: $0.10/M tokens
GPT-4 in ’23: $37.50!
Look out below, and let’s go! ❤️
Decepticon - Vibe Hacking Agent - https://t.co/4l0UMypv62
Autonomous Multi-Agent Based Red Team Testing Service / AI hacker
Decepticon is designed for that very purpose: using AI agents to automate red teaming before attackers automate theirs.
Built on the robust foundation of LangChain/LangGraph, Decepticon grows alongside the thriving AI agent ecosystem. By leveraging the same cutting-edge frameworks that power the future of AI, we ensure compatibility, scalability, and continuous innovation through community collaboration.
Delegate repetitive and manual tasks to agents, and focus on intuition and decision-making to fulfill the true essence of a CyberSecurity Supervisor.
Google Search AI Mode is underrated.
You can ask it to explain any concept with visualizations, and it will write complete code to create generative layouts you can run and test.
GTR-Turbo: Merged Checkpoint is Secretly a Free Teacher
A novel RL method for VLMs that merges training checkpoints to create a teacher model, eliminating need for expensive GPT/Gemini. Boosts accuracy 10-30% while cutting training time 50% & compute cost 60%.
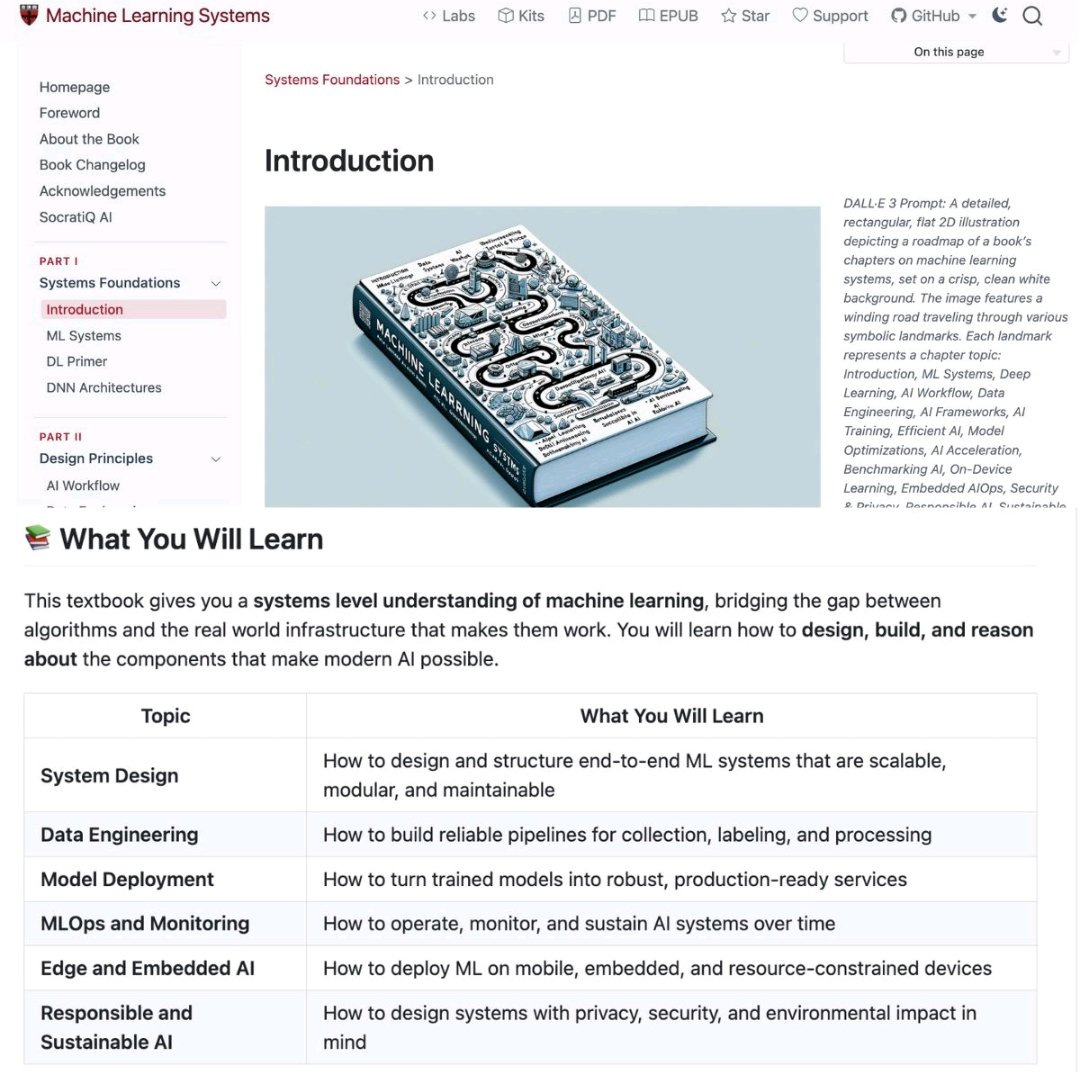
Harvard just leaked their Senior Engineer roadmap for free.
Stop paying for $2,000 bootcamps. Prof. Vijay Janapa Reddi just put the entire ML Systems (CS249r) curriculum on GitHub.
If you master these 6 pillars, you're ahead of 99% of the field:
🏛️ Architecture
🚿 Data Pipelines
🚢 Production
🛠️ MLOps
🔋 Edge AI
🔒 Privacy
This is the "Black Box" of Big Tech infrastructure, open-sourced.
This is the "Black Box" of Big Tech infrastructure, open-sourced.
Read. Learn. Bookmark.
i decided to put together all my AI engineering posts in a single pdf.
it covers:
> LLM foundations
> prompt engineering
> fine-tuning
> RAG
> context engineering
> AI agents
> MCP
> optimization
> deployment
> eval and observability
375+ pages. download link in next tweet!
Most "agentic" failures happen because the model lacks specific domain knowledge.
Here I'm showing how loading a Skills Plugin solves that for dataset generation. I turned a research paper (shows fine-tuning dataset creation from books) into a Skill and just gave a book link and asked it to generate the dataset.
Claude Code produced a clean SFT-ready dataset from a single URL.
The same process can be applied to anything.



































![makakmayum_sid's tweet photo. One of the most asked topic in Java/backend interviews: CQRS(Command Query Responsibility Segragation)
Scenario: An e-commerce Order service uses one relational database for:
- high-volume order writes
- customer order lookups
- heavy sales reports
During peak traffic, reporting queries slow down order creation.
The data model is becoming complex and hard to evolve.
What’s the real problem?
PROBLEM: forced reads and writes with very different workloads to share:
- the same database
- the same schema
- the same indexes
Transactional tasks and analytical queries are coupled, so obv. they fight each other.
Then:- performance degrades and the model keeps bloating.
SOLUTION::-
- CQRS
- Separate write paths and read paths.
How it works
[Writes] (Commands):
- orders are created/updated in a normalized write database, optimized for transactions.
[Reads] (Queries):
- reports and lookups read from a denormalized read database, optimized for fast queries.
Sync mechanism:
Write events are published via a message broker and update read models asynchronously.
CQRS solves the problem of mixing transactional and analytical workloads in one model.
-----------------------
This is well discussed in my Java+Spring boot+Microservices+Design Patterns+System design ebook curated for interviews, you can check it out from here https://t.co/iH4Ung369Y](https://pbs.twimg.com/media/G9JH5dwbgAAHVag.jpg)