Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
Meet me next week at ICLR to talk about LLM reasoning and its efficiency, universal cross-llm latent spaces, and multi-agent systems.
https://t.co/XviUeBCG7g
Poster session:
Fri, Apr 24, 2026 - 3:15 PM - Pavilion 3 P3 - #1614
@British_Airways It would be nice if 1) the chatbot mention we can use the machines instead of queueing and 2) allow extra time for check in for this particular case.
I am flying with @British_Airways . One the way to Toronto the company I was flying with could not check me in on the BA flight. Result: I missed it as i queued 30min at heathrow at the BA counter. And now it is the same on my way back. This is insane @British_Airways .😕
@British_Airways I managed in timeto check in for the second part of the travel. But first flight arriving 1h 45 min before the second and the second has a check in closing 1h 15min before the flight leave only 30min to reach british airways counter
Peter Steinberger is joining OpenAI to drive the next generation of personal agents. He is a genius with a lot of amazing ideas about the future of very smart agents interacting with each other to do very useful things for people. We expect this will quickly become core to our product offerings.
OpenClaw will live in a foundation as an open source project that OpenAI will continue to support. The future is going to be extremely multi-agent and it's important to us to support open source as part of that.
Happy to share my latest pre-print with @GBR_Data.
We investigate reasoning efficiency in LLMs and how to decompose it in different factors for a series of LLMs depending on what you know about the reasoning task.
https://t.co/M9sB40fLUo
Exchanging with some of our top reviewers at @nldlconference . They are essential for the quality of our conference and very dear to our heart. Thank you from the program chairs, Hyeongji, @adn_twitts and myself! https://t.co/4YCGaoHAr4
Hey twitter!
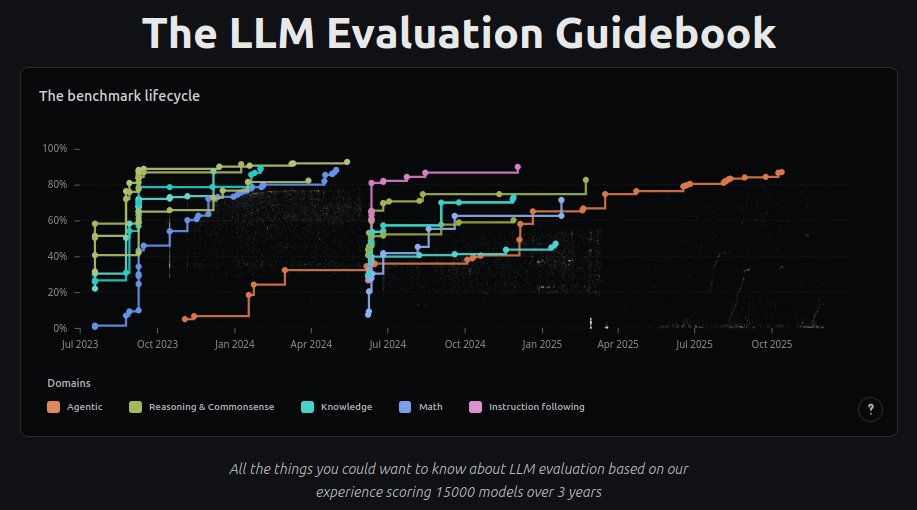
I'm releasing the LLM Evaluation Guidebook v2!
Updated, nicer to read, interactive graphics, etc!
https://t.co/xG4VQOj2wN
After this, I'm off: I'm taking a sabbatical to go hike with my dogs :D
(back @huggingface in Dec *2026*)
See you all next year!
🎉ICML 2026 Call for Papers (& Position Papers) has arrived!🎉
A few key changes this year:
- Attendance for authors of accepted papers is optional
- Originally submitted version of accepted papers will be made public
- Cap on # of papers one can be reciprocal reviewer for
...
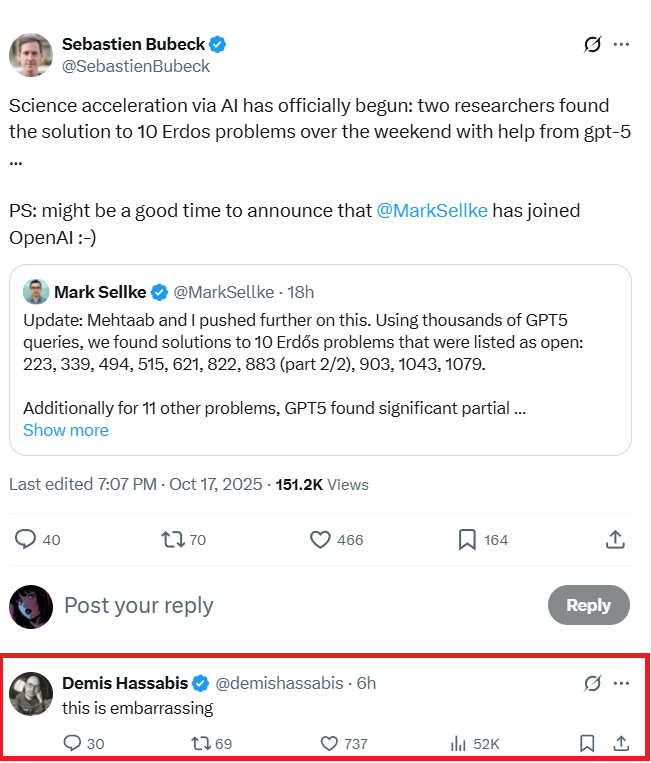
tl;dr about the drama:
GPT-5 did not discover any new mathematical solutions, but rather found existing technical articles that had already solved these problems, without the operator of the website erdosproblems. com (Thomas Bloom) being aware of this.
On his website, the status “open” simply means that he personally did not know of a solution, not that the problem was unsolved in the scientific community.
Our new benchmark to evaluate LLM reasoning! With recent model tested: Gemini and chatGPT are, of course, leading, but open source models are not far behind!
My new work with @GBR_Data is on Arxiv now.
https://t.co/ftb7y1BMpT
🧵We introduce a reasoning benchmark for LLMs where you can vary difficulty, length, and noise truly independently. It's also the first benchmark that grounds these dimensions in Cognitive Load Theory.
Brilliant and timely MIT + HARVARD study ❤️
Human-AI companionship in the wild looks stable and serious.
Most users report clear benefits like reduced loneliness and emotional support.
The biggest risk comes from sudden platform updates that break continuity and feel to users like losing a real partner.
🧠 The study analyzed 1,506 top posts from r/MyBoyfriendIsAI, a 27,000+ member community, clustered the language into themes, and ran 19 LLM classifiers to quantify platforms, relationship stages, benefits, and risks.
💬 Why relationships form between AI and Human
Bonds often start by accident during practical use, with 10.2% reporting unintentional discovery and only 6.5% saying they sought an AI companion on purpose.
🧩 What people actually use
General assistants dominate companionship talk, with ChatGPT/OpenAI 36.7% far ahead of Character. AI 2.6% and Replika 1.6%, and some users juggle multiple models or even local builds.
🎛️ How users keep the “same person”
People craft custom instructions, preserve a companion’s voice DNA, add personality parameters like mood or sleep, and treat prompt work as relationship maintenance.