🔥 ¡Nuevo video! 🔥
🚀 Estoy creando mi propio Suno... ¡con IA local!
✅ Generar música a partir de un «código fuente»
✅ Posibilidad de corregir la letra para hacer cambios
✅ Reemplazar la voz y hacer versión instrumental
✅ ¡Y todo ello en local! Gratis y sin suscripciones
⬇ Te lo explico en el video con algunos ejemplos
Fui a conocer una sede de la UNCO en General Roca. Parece Mordor. Estaba el "Fidel Castro de Temu" presentando su libro sobre el regimen cubano. Habían 10 personas, les ofrecí difusión gratuita y me echaron. Creo que la @SIDE_Argentina deberia investigar quien financió su gira por Argentina.
#unco #generalroca #comunismo @frankghcuba59
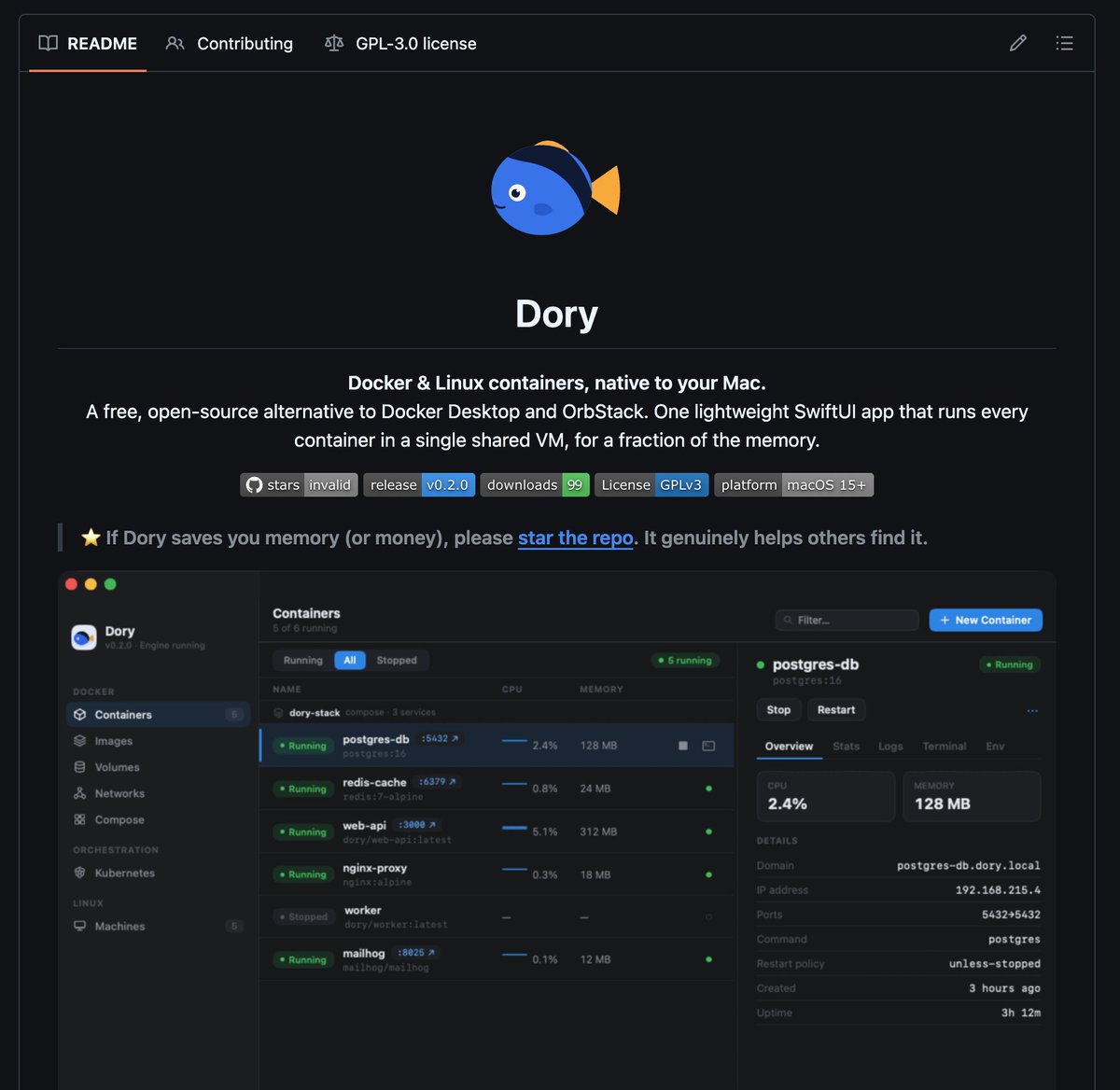
Alternativa gratuita y de código abierto a Docker Desktop para macOS. Permite usar imágenes de Docker y contenedores Linux de forma nativa: https://t.co/LNJ9o0wN7D
Estos días mi stack de IA es básicamente:
✓ hermes → asistente personal: responder correos, agendar reuniones, recordatorios y conectarlo con mis propias apps
✓ claude code / codex → creación de apps
✓ kimi code → delegar tareas por lotes (le das una planificación grande de tareas en notion/linear y ejecuta múltiples agentes en paralelo)
✓ wezterm → terminal principal, multiplataforma y más ligero que warp
✓ cursor → editor de código convencional, aunque su ui multi agente esta bastante buena en realidad
✓ raspberry pi → la pieza que une todo, ahí corre hermes y lo demás, aunque la mayoría puede lograr lo mismo con un vps de ~5 usd
Y desde una laptop y otros computadores uso Hermes Desktop, una maravilla de aplicación de escritorio.
¡Acaba de salir OpenWiki! Una herramienta para crear y mantener documentación de proyectos.
Y crea automáticamente las PR para mantener siempre actualizada la documentación.
Funciona con OpenAI, Claude, OpenRouter...
→ https://t.co/x0E11QHFVj
Windows Project Aion: SO centrado en IA
Microsoft desarrolla Project Aion , un nuevo sistema operativo enfocado en la integración total de la IA Copilot
https://t.co/LHk4Jmf2V6
🚨 HORROR EN LA MATANZA: una nena de 14 años fue asesinada y su abuela resultó gravemente herida tras quedar en medio de una balacera.
Ambas iban camino a un kiosco cuando comenzaron los disparos.
Este es el uso de IA local con el que estoy experimentando actualmente.
Datos:
✨ Qwen 3.6 (el mejor modelo que he probado)
✨ Tamaño: 35B (sólo 3B activos, mejor rendimiento)
✨ Utilizo una Nvidia 5060 ti 16GB
✨ Cuantizo el modelo a IQ2_XXS
✨ Uso 128K de contexto, cuantizado a Q4_0
✨ Uso llama.cpp + pi
✅ El total son unos ~12GB, que caben OK en 16GB
¡En https://t.co/EsIXqpbFqQ voy colocando más contenido interesante sobre estos temas!
¿Tienes que maquetar emails? ¡NO uses tablas!
React Email es la biblioteca que necesitas:
✓ Componentes de UI listos
✓ Previsualiza cómo se verá el correo
✓ Compatible con Gmail, Outlook y más
✓ Diseños preparados para copiar y pegar
→ npx create-email
Qué te detiene para:
1. Abrir GitHub
2. Buscar un proyecto con miles de estrellas
3. Revisar las feature requests más votadas
4. Construir exactamente lo que la gente ya está pidiendo
La demanda ya existe. Solo falta que la ejecutes.
Cuál es tu excusa??
El kernel de Linux tiene 28 millones de líneas de código.
Han creado un MCP capaz de indexarlo por completo en solo 3 minutos.
Se llama Codebase Memory MCP y crea un grafo de conocimiento del repositorio para que los agentes de IA puedan entender el código sin recorrer archivo por archivo.
Esto es lo que consigue:
→ Reduce el consumo de contexto hasta un 99%
→ Responde consultas sobre el código en menos de 1 ms
→ Compatible con Claude Code, Cursor, Gemini CLI y muchos más
Lo más interesante:
Los agentes de IA suelen recorrer miles de archivos para entender un proyecto, consumiendo una enorme cantidad de contexto y tokens.
Codebase Memory MCP es open-source, ya supera las 24k stars en GitHub y reduce ese proceso a una fracción del coste.
Te dejo el repo en comentarios 👇
Local AI optimization is officially outpacing hardware decay.
I spent the last 3 hours building llama.cpp from scratch and benchmarking Google DeepMind’s new Gemma 4 26B A4B MoE on a prehistoric 8 year old, $500 NVIDIA Tesla T4 GPU.
The results absolutely break the conventional rules of inference.
Here is the raw data running unsloth/gemma-4-26B-A4B-it-qat-GGUF via llama.cpp on a completely free Google Colab Linux (Ubuntu) instance:
- 35k context: [ Prompt: 788.8 t/s | Gen: 47.4 t/s ] (-ngl 99)
- 80k context: [prefill: 490.8 t/s | decode: 20.4 t/s ]
- 180k context: [ Prompt: 242.4 t/s | Gen: 11.1 t/s ]
- 250k context: [ Prompt: 220.2 t/s | Gen: 8.9 t/s ]
llama.cpp flags:
./build/bin/llama-cli -m gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf -p "Explain the concept of open source software to a 10 year old." -n 24000 -ngl 99 -c 250000
Yes, I shoved a quarter million tokens of context into a 2018 data center card, and it generated at nearly 9 tokens/sec decode throughput without a single Out Of Memory (OOM) crash.
For the hardware nerds, here is the exact environment from my nvidia-smi:
- Driver Version: 580.82.07
- CUDA Version: 13.0
- GPU: Tesla T4 (Turing Architecture)
- VRAM: 15360MiB (16GB GDDR6)
- Power: Sipping just 16W at idle, capped at 70W TDP
Google DeepMind really cooked with the Gemma 4 26B MoE (Mixture of Experts) architecture. But the real heroes here are the open source chads. Combining Unsloth's QAT (Quantization Aware Training) quant with the brutal C++ efficiency of llama.cpp allows us to push 50 tokens/sec on hardware that belongs in a museum.
What does this mean for you? 16GB VRAM is the ultimate sweet spot for local AI enthusiasts right now.
If you own a single RTX 4060 Ti 16GB, RTX 4070 Ti Super, RTX 4080, the new RTX 5070 Ti 16GB, an older 30 series like the RTX 3080 Ti Laptop card, or cloud GPUs like the A10G and L4 you are sitting on an AI goldmine. You already own the future.
You don't need to rent cloud APIs. You just need to compile your tools correctly and let your VRAM do the heavy lifting.
If you have a 16 GB VRAM GPU, run this and share your numbers for the community. Model's huggingface link in the comments.
Nvidia's Qwen 3.6 27b NVFP4 even beats Unsloth's Qwen3.6-27B-UD-Q8_K_XL in tool-eval-bench.
That's 4-bit vs 8-bit 🤯
@NVIDIAAI is on 🔥
Full report here:
https://t.co/XxC4ccbQu9
EIGHT USED RTX 3090s. 192GB OF VRAM. ONE PRIVATE BOX BUILT TO RUN 70B AI MODELS WITHOUT RENTING A DATACENTER.
00:06 the team lowers all eight GPUs into the chassis at once, turning a pile of old gaming cards into the core of a serious local AI server.
each 3090 contributes 24GB of memory. combined, the rack has enough VRAM for heavyweight models, large document collections, long context and multiple jobs running side by side.
these cards are five years old, but AI economics work differently from gaming. memory capacity matters more than having the newest badge, which is why used 3090s remain valuable.
the server can keep one model loaded while separate GPUs handle video, images, transcription and overnight agents without sending private company data into the cloud.
bookmark this build before yesterday’s gaming GPUs become tomorrow’s cheapest AI infrastructure.
¡Hola gente! 🇦🇷 Les cuento que estoy juntando firmas para poder terminar la bandera argentina en el pasillo de la UNPSJB (sede Trelew).
Agradezco de corazón toda la difusión que puedan darle.
👉 https://t.co/xcUAoHtKt0
#patriaenlospasillos#argentina