Genomic Technologies Group // The Garvan Institute of Medical Research // Australia's leading long-read sequencing service // Enquiries: [email protected]
Cornetto v0.2.0 is now released for using programmable selective nanopore sequencing for genome assembly.
GitHub: https://t.co/Sp2CHp1BmT
Paper: https://t.co/9y00QcmBfF
Datasets: https://t.co/8cFKDUcoZh
... and a banner made by Ira @GenTechGp referring to ‘no boring bits’.
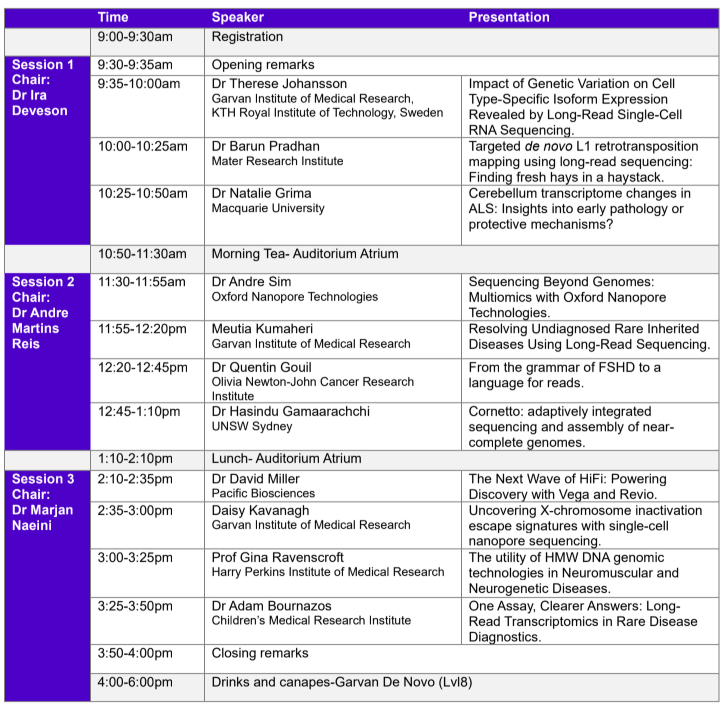
Not long now until our Long-Read Research Symposium on November 13th. See below the amazing line-up of speakers and talks. It's not too late to register for this free event - click the link --> https://t.co/vMc0x3mwmz
Join us for a day (Nov 13) of fascinating talks and discussions on the latest in long-read sequencing tech and related research in genomics, transcriptomics, and epigenetics. A great opportunity to network and hear from leading experts from around Aus.
https://t.co/DLugyQwJ6u
Tha Garvan long read research symposium is BACK! Sponsored by @nanopore and @PacBio this event is FREE to join. Learn all about the fun you can have with long reads 🤓
register below
https://t.co/TynhVx5YgO
Come join us this November 13th for the Garvan Long-Read Research Symposium! You'll hear about the wonderful things you can do with @nanopore and @PacBio long reads from a great line-up of speakers. FREE to attend. Register below
https://t.co/vMc0x3mwmz
For many of those who were asking on BLOW5 vs POD5 for nanopore signal data, here is a finally detailed benchmark we did:
https://t.co/ZspXSlrW9e
Summary: performance of BLOW5 is >= POD5 (from ~= to 100X, see below), with benefit of having ~3 dependencies instead of >50.
Check out the excellent line-up of speakers we have for the @GarvanInstitute Long Read Research Symposium day
It is FREE to come along - this November 7th. Reserve your spot https://t.co/fvgVtzOpfs
Not long now until the @GarvanInstitute Long Read Research Symposium on November 7th. We will have talented speakers covering the advantages of both @nanopore and @PacBio data
Only a few spots left - don't miss out! 💃
https://t.co/fvgVtzOpfs
Introducing ex-zd, a lossless+lossy signal compression for @nanopore signal data. While lossless can only save about 1-3% over vbz, lossy can cut the file sizes by almost half with no noticeable impact on basecalling or methylation calling accuracy.
https://t.co/xnGcLOlaCQ
@mprous1@Hasindu2008@nanopore That’s a good point, however we don’t think this will happen because the bits that are being removed in our 3-bit-reduction appear to encode noise, not signal (see fig 2a). We speculate that if the basecallers were retrained on bit-reduced data they may even perform better.
We are hosting a Long Read Research Symposium at @GarvanInstitute ! Our talented speakers will cover the advantages of both @nanopore and @PacBio data.
Join us to find out what long reads could do for you 🧬
https://t.co/fvgVtzOpfs
@ClarksysCorner Two papers that sat with them for up to 6 months with nothing happening, and no responses to emails. One did end up going to review and eventually published, the other rejected. Complete shambles, and have heard others with similar stories there.
@Stoibs11@hiruna72@Hasindu2008 Hiruna can elaborate, but also pls take a look at SupNote3 for more detailed explanation of the calculate-offset feature
@Hasindu2008 @josiegleeson @Psy_Fer_@nanopore Hi Josie, the UHR we sequenced is actually from Agilent https://t.co/iIK2QmuS62
(catalog number 740000), which is from a cell line
Our #slow5curl paper is out! https://t.co/TbmcA8c1X4
Big projects storing hundreds/thousands of @nanopore signal datasets on cloud storage like @awscloud#s3 will be able to save 💸,⏲️ and bandwidth while improving the accessibility of datasets to those with limited computing ..