They say the best time to tweet about your research was 1 year ago, the second best time is now. With RAI formerly known as Boston Dynamics AI Institute, we present DiffuseCloC - the first guidable physics-based diffusion model. https://t.co/P3PofBZl7t
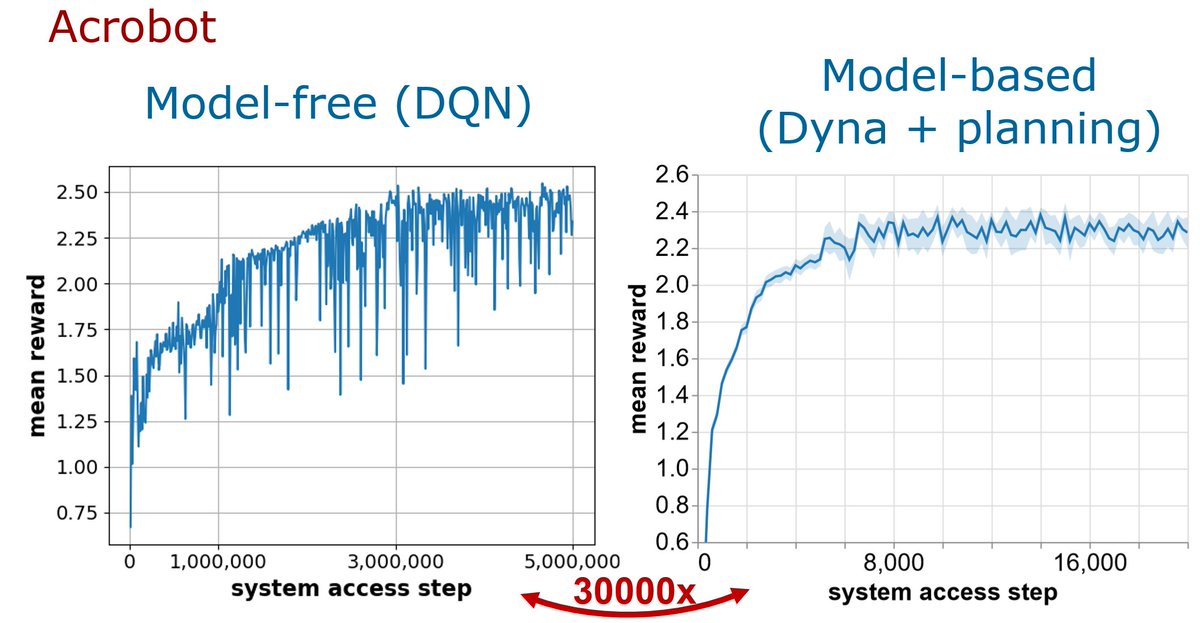
I agree just beg to differ on your last statement. In our experiments there is one need for (model-free) RL: learning a "guide" policy which is used in planning to cut down the size of the search space. Like the policy net in AlphaGo. Form another angle: "pure Dyna" would just use this policy as the final agent, but we find it advantageous to add planning to it.
I find it analogous to using optimization in ML. It's not good to overly optimize the guide policy because of the model/reality mismatch, it's like overfitting. The main message is that MFRL should focus on this use case, because this approach (model + model-free RL + planning) cuts down sample complexity by orders of magnitude. And the same way SGD is not the best optimization algorithm, the MFRL algorithm that works the best for optimizing but not overfitting on the model may be yet to be invented.
🌟 How can we unify image and video region understanding into a single framework?
🚀 Introducing Omni-RGPT — our latest multimodal LLM designed for interactive, region-level understanding across images and videos! 📽️🖼️
🤖 We are thrilled to announce AgiBot World with @agibotworld, the first large-scale robotic learning dataset designed to advance multi-purpose humanoid policies!
With 1M+ trajectories from 100 robots, AgiBot World spans 100+ real-world scenarios across five target domains, tackling fine-grained manipulation, tool usage, and multi-robot collaboration. Cutting-edge multimodal hardware features visual tactile sensors, durable 6-DoF dexterous hands, and mobile dual-arm robots with whole-body control, supporting research in imitation learning, multi-agent collaboration, and more.
Github:
https://t.co/EXaXiwipHS
HuggingFace:
https://t.co/wcbSESfQot
Homepage:
https://t.co/XBZTwJL86t
Discord:
https://t.co/ewad3dQgzM
Dataset Highlights:
- Cutting-edge sensor and hardware design
- Wide-spectrum of scenario coverage
- Quality assurance with human-in-the-loop
Got all 4 fingers and the thumb of the https://t.co/773ivvneGO moving! We have enough dexterity to pick up objects. Up next we are integrating V2 of the control glove to add wrist tracking via IMUs and haptic feedback using buzzers on the fingertips.
How to pack products with class? 👀
Innovative product packaging by Douglas Machine 📦
These robots can pack items standing up or lying flat in the case, making creating neat and appealing arrangements easy. They're designed to switch between different packing styles quickly, accommodating different products and layouts.
Using robot arms, they handle everything from getting the products to loading them into the case, all in one machine.
Thoughts?
P.S. That's what you call engineering flair! 🤘🏼
~~~
♻️ RT to help 1 robot find a new workplace.
Gen 1/2 Wrist vs. Gen 3 Wrist
At We, Robot we got a glimpse of the new 23 DoF (yes 23, not 22) hand.
In this post I will only address the change in actuation strategy for the wrist. Later posts will address the tendons.
The Gen 3 wrist is an improvement over the Gen 1/2 design. It is still driven by linear actuators. However, they solved an issue with the original design.
In the Gen 1/2 wrist (left), the black actuator needs to rotate to prevent the piston from binding during travel. It is a three-bar mechanism.
In the new wrist (right) an additional linkage is added to allow the actuator to remain stationary. Technically this is a four-bar mechanism.
The trade-off is an additional part is needed to keep the actuator fixed. This is needed to make the servo stack of the forearm compact, so the wrist actuators can be easily integrated into the design.
In the Gen 3 design, the new linkage is not straight as in the animation, but crooked to allow for better integration.
This new mechanism can be seen in video clips like this taken at We, Robot .
Training Language Models with Language Feedback
Proposes to learn from natural language feedback, which conveys more information per human evaluation.
https://t.co/YXCsKhL2NI