Is equivariance necessary for a good 3D molecule generative model? Check out our #icml2025 paper, which closes the performance gap between non-equivariant and equivariant diffusion models via rotational alignment, while also being more efficient (1/7):
https://t.co/kFiZptFwsr
@zhuci19 You might also be interested in our previous work that explored something similar:). We used an autoencoder to learn rotations that aligned 3D molecules, which we found improved non-equivariant DMs: https://t.co/kFiZptEYCT
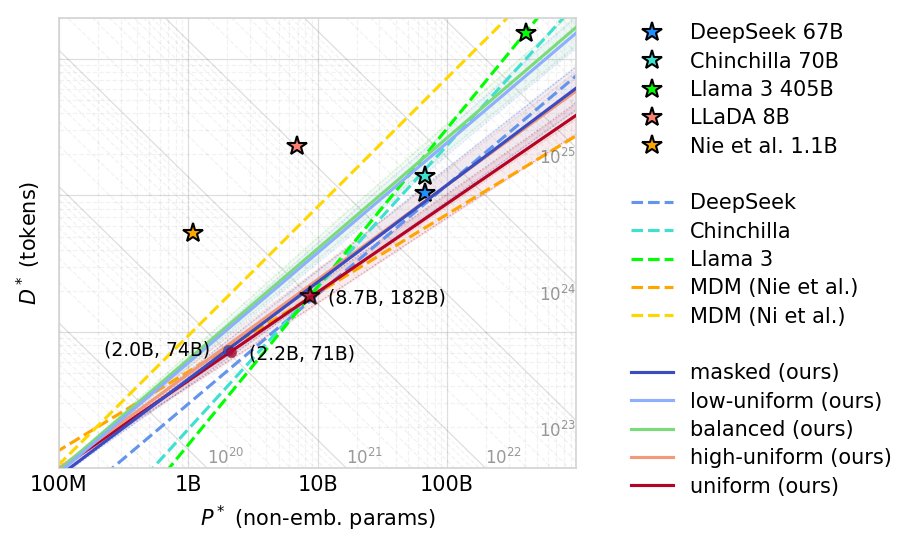
🚨 NEW PAPER! (this is a big one; 3B and 10B models included)
Masked diffusion LLMs are getting a lot of attention. They outperform other diffusion types (such as uniform diffusion) at small scales.
But what if I told you that uniform diffusion actually scales better? 🧵👇
I'll be at #ICML2025 in Vancouver next week presenting our GIDD (Generalized Interpolating Discrete Diffusion) paper together with @yuhui_ding and @orvieto_antonio!
Come chat to us at:
📅 Tue, July 15, 11:00–13:30
📍 Poster Session 1 East
@dvruette Good point! I believe large non-equivariant models still have great potential, especially on larger biochemical datasets where equivariant models face computational bottlenecks. Indeed, we found that the gap between "not aligned" and "aligned" became smaller with larger model
Is equivariance necessary for a good 3D molecule generative model? Check out our #icml2025 paper, which closes the performance gap between non-equivariant and equivariant diffusion models via rotational alignment, while also being more efficient (1/7):
https://t.co/kFiZptFwsr
We qualitatively visualize the learned rotations and find that molecules tend to arrange common structural semantics (e.g., rings) into similar orientations after alignment. (7/7)
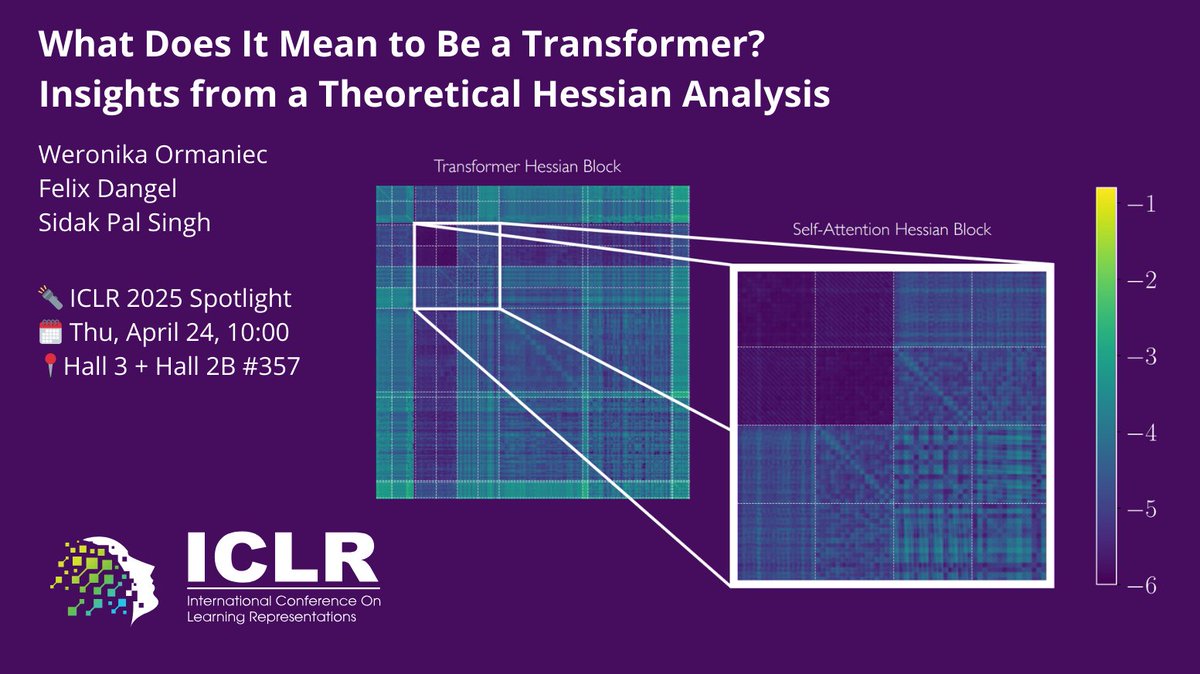
Ever wondered how the loss landscape of Transformers differs from that of other architectures? Or which Transformer components make its loss landscape unique?
With @unregularized & @f_dangel, we explore this via the Hessian in our #ICLR2025 spotlight paper!
Key insights👇 1/8
🚨 NEW PAPER DROP!
Wouldn't it be nice if LLMs could spot and correct their own mistakes? And what if we could do so directly from pre-training, without any SFT or RL?
We present a new class of discrete diffusion models, called GIDD, that are able to do just that: 🧵1/12
Announcing AlphaFold 3: our state-of-the-art AI model for predicting the structure and interactions of all life’s molecules. 🧬
Here’s how we built it with @IsomorphicLabs and what it means for biology. 🧵 https://t.co/gjw6Ip4F2M
Inspired by recent breakthroughs in SSMs, we propose a new architecture, Graph Recurrent Encoding by Distance (GRED), for long-range graph representation learning: https://t.co/59QoZsqefI
with @orvieto_antonio, @bobby_he and Thomas Hofmann (1/4)
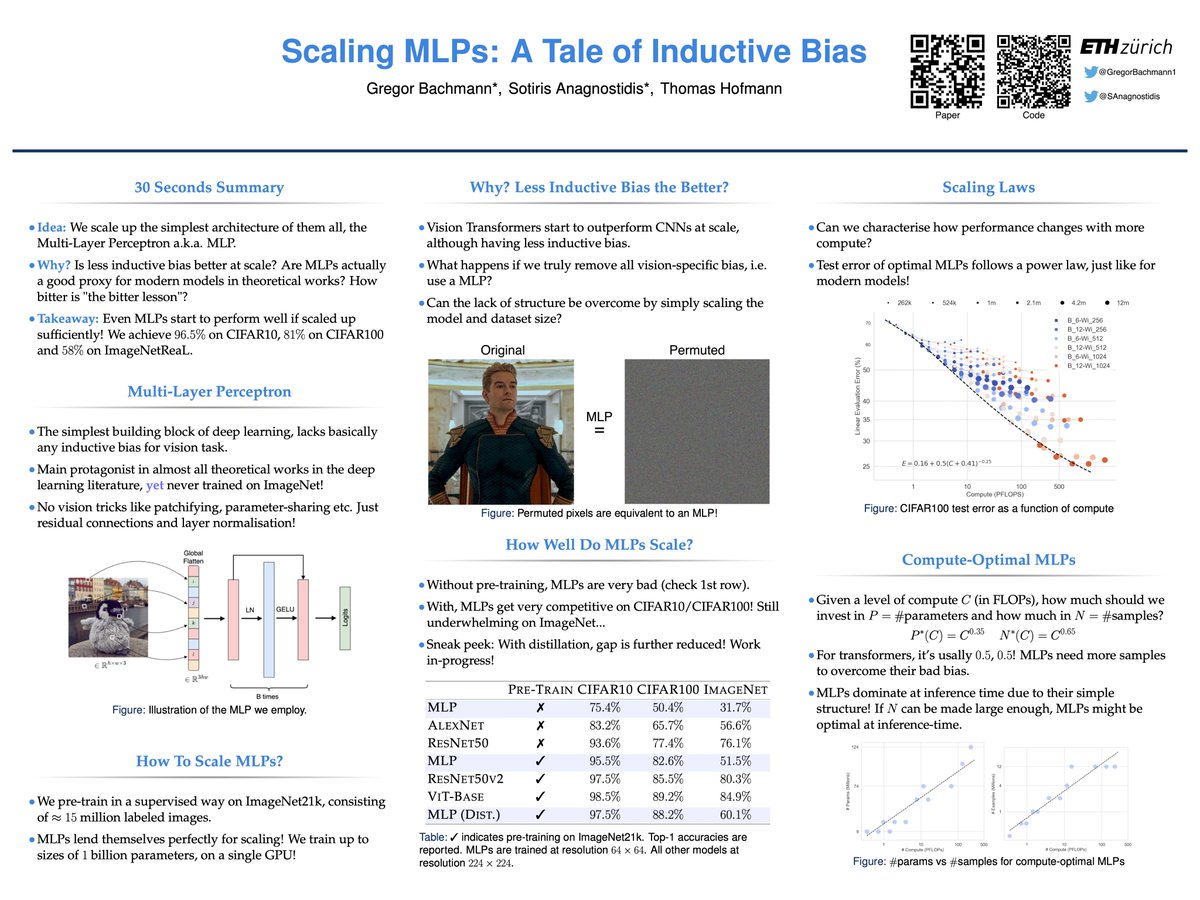
I’ll be presenting "Scaling MLPs" at #NeurIPS2023, tomorrow (Wed) at 10:45am!
Hyped to discuss things like inductive bias, the bitter lesson, compute-optimality and scaling laws 👷⚖️📈
Inspired by recent breakthroughs in SSMs, we propose a new architecture, Graph Recurrent Encoding by Distance (GRED), for long-range graph representation learning: https://t.co/59QoZsqefI
with @orvieto_antonio, @bobby_he and Thomas Hofmann (1/4)
@Genemmie@orvieto_antonio@bobby_he Thank you for your interest! Since the invariant neural network (AGG) can express an injective function on multisets, our model can encode the number of neighbors (thus the number of edges) for each node