They're burying a lot here. There's a 66% price cut from Opus 4.1 to $5/$25, it uses fewer tokens to solve problems, upgrades to Claude Code in the app, no more length limits on conversations, no more Opus-specific plan caps...
Introducing Claude Opus 4.5: the best model in the world for coding, agents, and computer use.
Opus 4.5 is a step forward in what AI systems can do, and a preview of larger changes to how work gets done.
@piercefreeman I agree and thought this was compelling specifically for logs https://t.co/nB8XN2G3wk
Treat walls of logs like a human would: poke at it from a distance
I had some early access to Sonnet 4.5. It is a really good model. I saw especially big jumps in doing finance and statistics, which tend to get overlooked in the focus on coding.
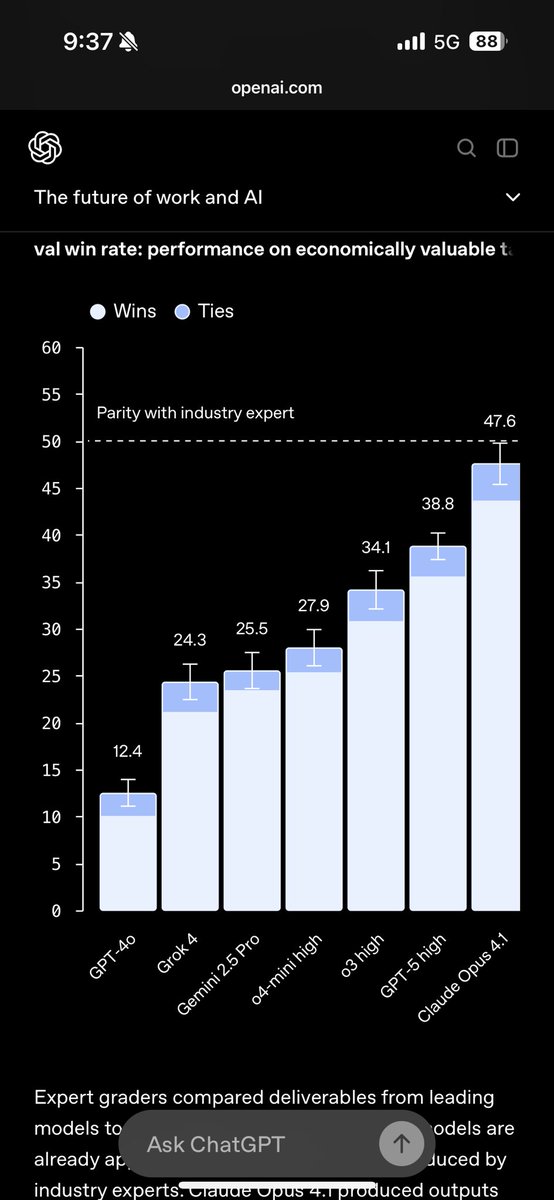
Incredible work - this should immediately become one of the most important metrics for policy makers to track.
We’re probably only a few months from crossing the parity line.
Huge props to OAI for both doing the hard work of pulling this together and including our scores. Nice to see Opus on top :)
The Claude Code SDK now supports custom tools and hooks directly in code.
Additionally, we’ve refreshed all our docs with complete references and 10 new guides on how to utilize the SDK.
Introducing ❄️ @snowglobe_so, the simulation engine for AI chatbots.
Magically simulate the behavior of your users to test and improve your chatbots.
Find failures before your users do.
Announcing DeepSWE 🤖: our fully open-sourced, SOTA software engineering agent trained purely with RL on top of Qwen3-32B. DeepSWE achieves 59% on SWEBench-Verified with test-time scaling (and 42.2% Pass@1), topping the SWEBench leaderboard for open-weight models.
Built in collaboration with the @Agentica_ team.
💪 DeepSWE is trained with rLLM, Agentica’s modular RL post-training framework for agents. rLLM makes it easy to build, train, and deploy RL-tuned agents on real-world workloads — from software engineering to web navigation and beyond.
🤗 As always, we’re open-sourcing everything: not just the model, but the training code (rLLM), dataset (R2EGym), and training recipe for full reproducibility.
🔥 Train DeepSWE yourself. Extend it. Build your own local agents. No secrets, no barriers.
DeepSWE and rLLM mark our major shift: from training language reasoners to building language agents that can truly learn from experience.
We believe the future of AI lies in experience-driven learning — and we’re here to democratize it.
Welcome to the era of experience. 🌍
Text diffusion models might be the most unintuitive architecture around
Like: let's start randomly filling in words in a paragraph and iterate enough times to get something sensible
But now that google's gemini diffusion is near sota, I think we need to take them seriously
The Nvidia Tensor Core is the most important evolution of computer architecture in the last decade
We explain why / how it's evolved
Shout out to collaborators @bfspector@tri_dao@colfaxintl@charles_irl@ia_buck Neil Movva Jonah Alben
esp @simonguozirui for the cutest cover pic