One English screenplay → 18 shot-level prompts → final cut.
• Seedance 2.0 + Omni Reference via @tapnow_ai
• @elevenlabs for voice + score
• @topazlabs for the 4k upscale
• @Prompt_Driven orchestrating the whole pipeline
@sisozo_ wrote in English. Pipeline did the rest
We just shipped the first programmatic-video use case for Prompt Driven at film scale.
UNWRITTEN: a 3-minute AI short film by @sisozo_ & @GregTanaka just made Top 5 Best Film at @soulscapefilm 2026 (out of 39 films).
Here's how we built it in 36 hours 🧵
Watch the 3-minute film → https://t.co/rZXlYpsi2I
Open-source pipeline → https://t.co/LOw7zzzJqA
Saloni handled the creative. I handled the technology.
@sisozo_ wrote a film I couldn't have built without her story.
The real unlock: treating the screenplay as the source of truth.
Color palette (cold blue → gold → golden hour) was ONE directive inherited across all shots in an act. Not 18 per-shot prompt tweaks.
You iterate on the script. The pipeline iterates on the prompts.
The real unlock: treating the screenplay as the source of truth.
Color palette (cold blue → gold → golden hour) was ONE directive inherited across all shots in an act. Not 18 per-shot prompt tweaks.
You iterate on the script. The pipeline iterates on the prompts.
Hardest problem: character consistency across 18 shots from one hero reference.
1st pass: ~37% usable (model drifted to generic features).
2nd pass: ~100% after adding explicit eth/age/features to every prompt body + "NO TEXT" neg directives.
The ref inspiration, not a lock.
Hardest problem: character consistency across 18 shots from one hero reference.
1st pass: ~37% usable (model drifted to generic features).
2nd pass: ~100% after adding explicit eth/age/features to every prompt body + "NO TEXT" neg directives.
The ref inspiration, not a lock.
One English screenplay → 18 shot-level prompts → final cut.
• Seedance 2.0 + Omni Reference via @tapnow_ai
• @elevenlabs for voice + score
• @topazlabs for the 4k upscale
• @Prompt_Driven orchestrating the whole pipeline
@sisozo_ wrote in English. Pipeline did the rest
@jeremyberman@MLStreetTalk Great interview! I like your strategy around using natural language instead of Python. It is similar to @Prompt_Driven. Perhaps we can chat more about it?
Ever get that "grenade in the codebase" feeling from agentic coders like Claude Code? You're never sure what they'll add, delete, or duplicate. I started exploring a new approach: what if prompts themselves were the source of truth instead of merely being used to patch the code?
>>> Qwen3-Coder is here! ✅
We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves top-tier performance across multiple agentic coding benchmarks among open models, including SWE-bench-Verified!!! 🚀
Alongside the model, we're also open-sourcing a command-line tool for agentic coding: Qwen Code. Forked from Gemini Code, it includes custom prompts and function call protocols to fully unlock Qwen3-Coder’s capabilities. Qwen3-Coder works seamlessly with the community’s best developer tools. As a foundation model, we hope it can be used anywhere across the digital world — Agentic Coding in the World!
💬 Chat: https://t.co/V7RmqMaVNZ
📚 Blog: https://t.co/syL1hsSGKq
🤗 Model: https://t.co/1LWwUKMrBN
🤖 Qwen Code: https://t.co/qqwj5nAO3Z
I attended a vibe coding hackathon recently and used the chance to build a web app (with auth, payments, deploy, etc.). I tinker but I am not a web dev by background, so besides the app, I was very interested in what it's like to vibe code a full web app today. As such, I wrote none of the code directly (Cursor+Claude/o3 did) and I don't really know how the app works, in the conventional sense that I'm used to as an engineer.
The app is called MenuGen, and it is live on https://t.co/bQonQT88t0. Basically I'm often confused about what all the things on a restaurant menu are - e.g. Pâté, Tagine, Cavatappi or Sweetbread (hint it's... not sweet). Enter MenuGen: you take a picture of a menu and it generates images for all the menu items and presents them in a nice list. I find it super useful to get a quick visual sense of the menu.
But the more interesting part for me I thought was the exploration of vibe coding around how easy/hard it is to build and deploy a full web app today if you are not a web developer. So I wrote up the full blog post on my experience here, including some takeaways:
https://t.co/2kkQh0ElgB
Copy pasting just the TLDR:
"Vibe coding menugen was exhilarating and fun escapade as a local demo, but a bit of a painful slog as a deployed, real app. Building a modern app is a bit like assembling IKEA future. There are all these services, docs, API keys, configurations, dev/prod deployments, team and security features, rate limits, pricing tiers... Meanwhile the LLMs have slightly outdated knowledge of everything, they make subtle but critical design mistakes when you watch them closely, and sometimes they hallucinate or gaslight you about solutions. But the most interesting part to me was that I didn't even spend all that much work in the code editor itself. I spent most of it in the browser, moving between tabs and settings and configuring and gluing a monster. All of this work and state is not even accessible or manipulatable by an LLM - how are we supposed to be automating society by 2027 like this?"
See the post for full detail, and maybe give MenuGen a go the next time you're at a restaurant!
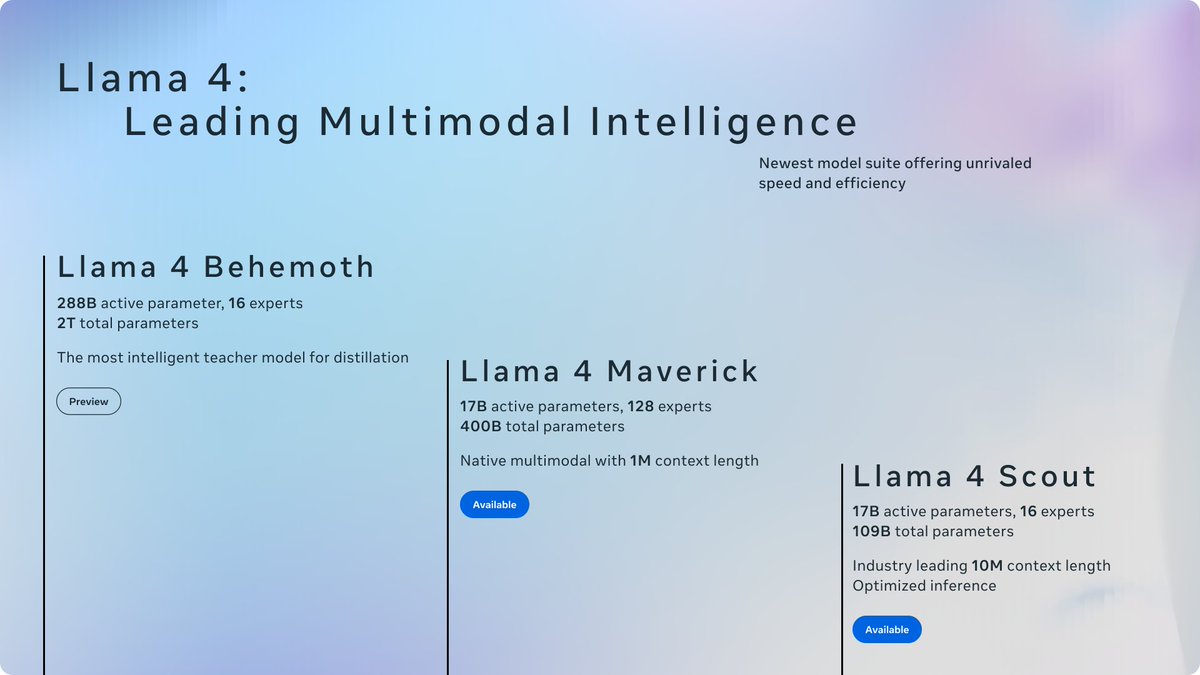
Today is the start of a new era of natively multimodal AI innovation.
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
Llama 4 Scout
• 17B-active-parameter model with 16 experts.
• Industry-leading context window of 10M tokens.
• Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.
Llama 4 Maverick
• 17B-active-parameter model with 128 experts.
• Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
• Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
• Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
• Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.
These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
Read more about the first Llama 4 models, including training and benchmarks ➡️ https://t.co/9G3QgVdCkB
Download Llama 4 ➡️ https://t.co/eVomRvEr0w
Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.
Blog: https://t.co/jpNEx0Ck8p
HF: https://t.co/h91przQmoP
ModelScope: https://t.co/p0ztmZpWIZ
Demo: https://t.co/sxVVRFwunC
Qwen Chat: https://t.co/bg4tAU1p74
This time, we investigate recipes for scaling RL and have achieved some impressive results based on our Qwen2.5-32B. We find that RL training con continuously improve the performance especially in math and coding, and we observe that the continous scaling of RL can help a medium-size model achieve competitieve performance against gigantic MoE model. Feel free to chat with our new models and provide us feedback!