True multimodal AI needs to understand the world spatially 🎯
🚀 Excited to release #CVPR2026 TIPSv2 from @GoogleDeepMind, a foundational image-text encoder with spatial awareness, leading to strong overall results and massive gains on patch-text alignment. 🔥
1/N
This is Gemini 3: our most intelligent model that helps you learn, build and plan anything.
It comes with state-of-the-art reasoning capabilities, world-leading multimodal understanding, and enables new agentic coding experiences. 🧵
Shraman is one of the best young researchers I have been working with. He has demonstrated profound skill in multimodal LLMs for visual grounding, segmentation and reasoning. Reach out to him if you need a top-tier vision-language multimodal expert!
My role at Meta's SAM team (MSL, previously at FAIR Perception) has been impacted within 3 months of joining after PhD.
If you work with multimodal LLMs for grounding or complex reasoning, or have a long-term vision of unified understanding and generation, let's talk.
I am on the job market starting immediately.
#metalayoffs #FAIR #MSL #SAM
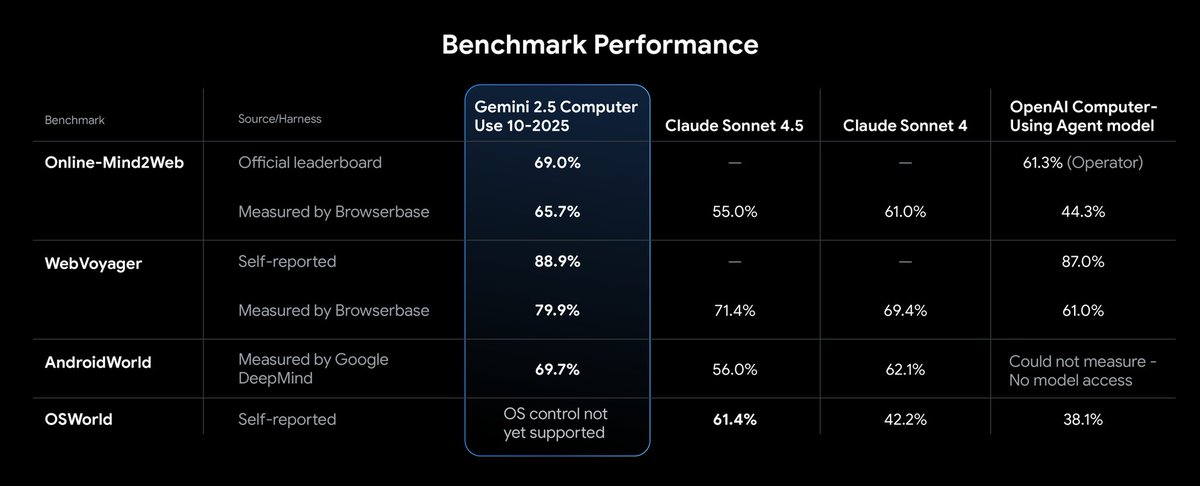
Our new Gemini 2.5 Computer Use model is now available in the Gemini API, setting a new standard on multiple benchmarks with lower latency. These are early days, but the model’s ability to interact with the web – like scrolling, filling forms + navigating dropdowns – is an important next step in building general-purpose agents.
Developers can try these capabilities via API in @googleaistudio + Vertex AI.
Thrilled to welcome @windsurf_ai founders @_mohansolo & Douglas Chen and some of the brilliant Windsurf eng team to @GoogleDeepMind. Excited to be working with them to turbocharge our Gemini efforts on coding agents, tool use and much more. Great to have you on board!
Gemini 2.5 Pro + 2.5 Flash are now stable and generally available. Plus, get a preview of Gemini 2.5 Flash-Lite, our fastest + most cost-efficient 2.5 model yet. 🔦
Exciting steps as we expand our 2.5 series of hybrid reasoning models that deliver amazing performance at the Pareto frontier of cost and speed. 🚀
Think you know Gemini? 🤔 Think again.
Meet Gemini 2.5: our most intelligent model 💡 The first release is Pro Experimental, which is state-of-the-art across many benchmarks - meaning it can handle complex problems and give more accurate responses.
Try it now → https://t.co/sxHWaCUzRp
Multimodal AI encoders often lack spatial understanding… but not anymore! Our #ICLR2025 TIPS model (Text-Image Pretraining with Spatial awareness) from @GoogleDeepMind can help 💡🚀
Check out our strong & versatile image-text encoder 💪
Paper & code: https://t.co/LCiqV4gaQ0
Excited to release a super capable family of image-text models from our TIPS #ICLR2025 paper! https://t.co/1scX7H1DIb
We have models from ViT-S to -g, with spatial awareness, suitable to many multimodal AI applications. Can’t wait to see what the community will build with them!
Very happy to see learnings from our TIPS method (ICLR'25 accepted https://t.co/IP6JowSDcE) adopted into SigLIP2! A very nice collaboration, great outcome!
Want some TIPS? Well, then check out “Text-Image Pretraining with Spatial awareness” :)
TIPS is a general-purpose image-text encoder, for off-the-shelf dense and image-level prediction. Finally image-text pretraining with spatially-aware representations!
https://t.co/LCiqV4gaQ0
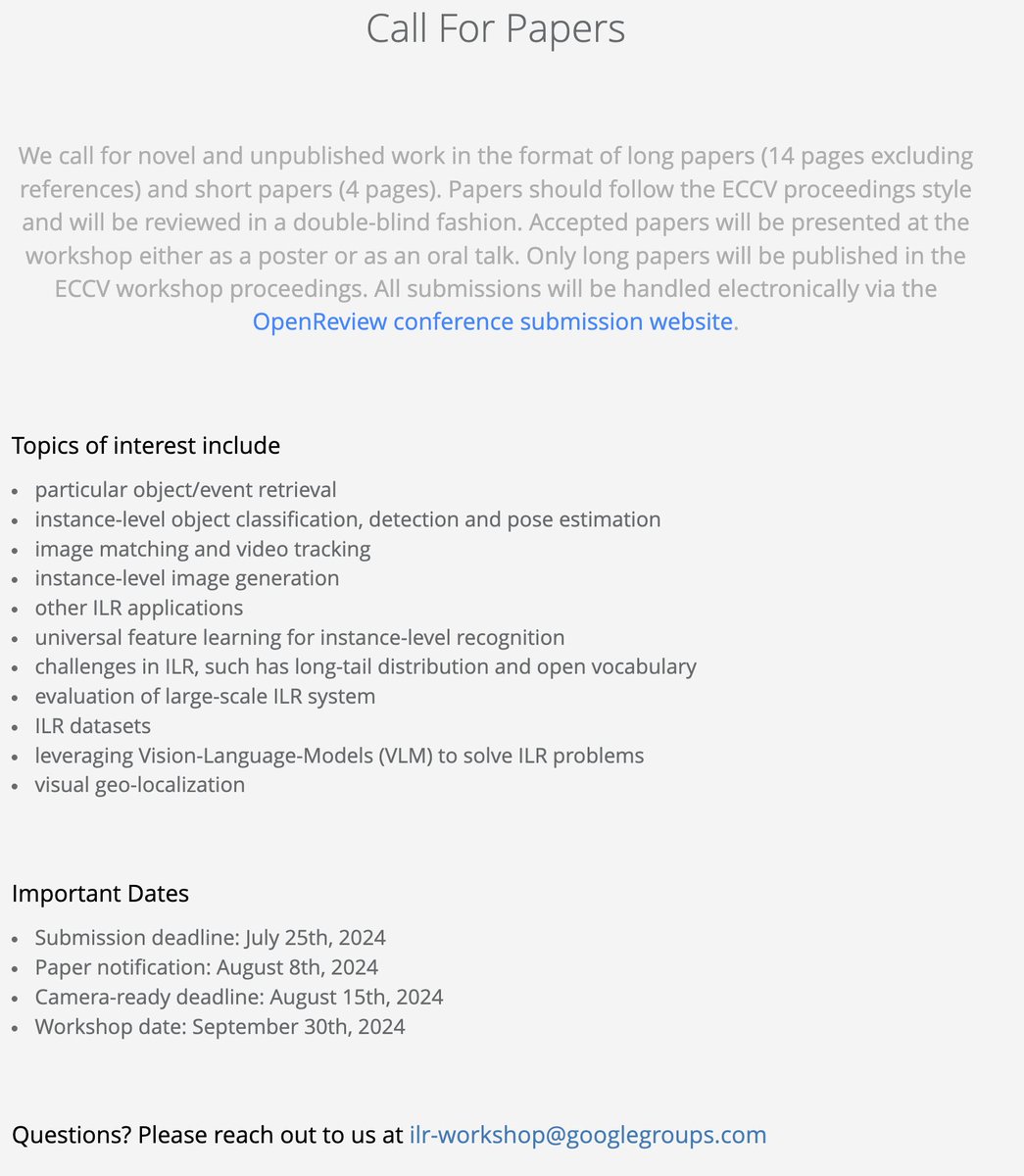
Our call for papers for the ILR workshop at #ECCV2024 is open! Deadline on July25th, options for both long and short papers. Don't miss this opportunity to showcase your work in the broad area of instance-level recognition!
Submit at: https://t.co/K0amT3liUC
Announcing the #ECCV2024 workshop on Instance-Level Recognition (ILR)! This is the 6th edition in our workshop series, with amazing keynote speakers: @CordeliaSchmid, @jampani_varun and @g_kordo.
Call for papers now open!
All information on our website: https://t.co/y2jJrvpDAa