Real-world LLM interactions are conversational, yet LLMs are far more vulnerable to multi-turn than single-turn attacks.
Introducing DialTree: RL + tree search for automated multi-turn attack discovery.
📊 81.5% avg ASR@1 across 12 LLMs
📈 +44.2% over prior SOTA
#ICLR2026 [1/6]
“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
Knowledge is not evenly distributed across languages. For a given question, what if better information comes from another language?
🔥 We propose Language-Routed Policy Optimization (LRPO), an online reinforcement learning framework that lets LLMs explore and learn from cross-lingual generations during training.
#ICML2026
Real-world LLM interactions are conversational, yet LLMs are far more vulnerable to multi-turn than single-turn attacks.
Introducing DialTree: RL + tree search for automated multi-turn attack discovery.
📊 81.5% avg ASR@1 across 12 LLMs
📈 +44.2% over prior SOTA
#ICLR2026 [1/6]
[5/6] In addition, DialTree shows highest attack efficiency using fewest queries. Its branch expansion effectively increases trajectory diversity. More analyses are discussed in the paper.
Introducing @NeoCognition, the agent lab for specialized intelligence.
Everyone needs experts, but human expertise does not scale.
Backed by $40M seed funding, we build self-learning agents that specialize across domains to make expertise abundant.
I’m so tired of writing rebuttals to this kind of “lack of novelty” review: “This paper trivially combines A, B, and C, so the algorithmic novelty is limited.”
Technically, most (if not all) robotics papers are convex combinations of existing ideas.
I still deeply appreciate A+B+C papers—especially when they deliver:
- New capabilities: the “trivial combination” unlocks behaviors we simply couldn’t achieve before
- Sensible & organic design: A+B+C is clearly the right composition—not some arbitrary A′+B+C′
- Nontrivial interactions: careful analysis of the dynamics, coupling, or failure modes between A, B, C
- Rehabilitating old ideas: A was dismissed for years, but paired with modern B/C, it suddenly works—and teaches us why
- System-level & "interface" insight: the contribution is not any single piece, but how the pieces talk to each other
- Scaling laws or regimes: identifying when/why A+B+C works (and when it doesn’t)
- Engineering clarity: making something actually work robustly in the real world is not “trivial”
- New problem formulations: sometimes the real novelty is in the reformulation—only under this view does A+B+C make sense.
Maybe worth keeping these in mind when reviewing the next A+B+C paper : )
We released Nemotron Cascade 2 30B A3B.
What makes this release especially meaningful to me is that it reflects a 1.5-year journey at NVIDIA around one core idea: improving AI math reasoning through self-improvement at test time.
Each project tackled a different part of that problem.
With AceMath (24 Q4), we built an external verifier model to identify the right solution during test-time scaling.
With AceReason (24 Q1-2), we scaled the reasoning capabilities of the model through RL so the model could spend more time reflecting while solving problems. Along the way, we found a general, simple and effective RL recipe that we’ve kept using since.
And now with Cascade 2 (25 Q1), we’ve pushed that effort further: the model can generate hypotheses, verify them, and refine them on its own. That self-improvement loop is what enabled IMO gold-level performance at 30B level.
From MATH500, to AIME, and now IMO Proof.
This team is THE BEST.
Technical report:
https://t.co/V0XZn2ypPg
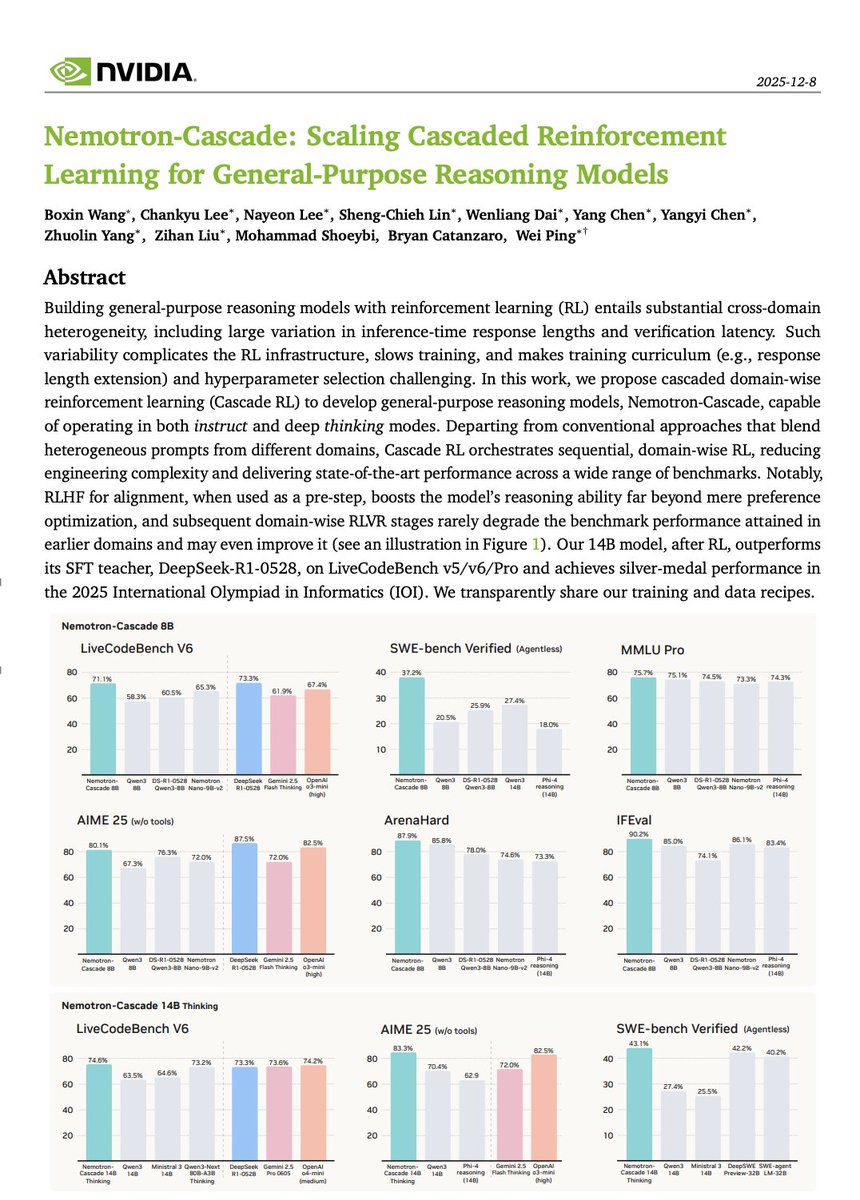
🥈 Silver Medal at IOI 2025 & Outperforms DeepSeek-R1-0528 on LiveCodeBench.
Instead of mixing different tasks together, we scale *Cascade RL* to develop general LLMs in curriculum (RLFH -> Instruct -> Math -> Code -> SWE).
So many learnings, check out our report!👇
At #NeurIPS2025 through Sunday. Come say hi and check out our posters on:
🔒Probabilistic reasoning for text anonymity estimation: Wednesday @ 11am
🤖 Efficient, self-improving agents: Friday @ 11am






![GuoOctavia's tweet photo. [5/6] In addition, DialTree shows highest attack efficiency using fewest queries. Its branch expansion effectively increases trajectory diversity. More analyses are discussed in the paper. https://t.co/qzKM8v0YTs](https://pbs.twimg.com/media/HGxuB7EaQAAsynW.jpg)

















![GuoOctavia's tweet photo. [5/6] In addition, DialTree shows highest attack efficiency using fewest queries. Its branch expansion effectively increases trajectory diversity. More analyses are discussed in the paper. https://t.co/qzKM8v0YTs](https://pbs.twimg.com/media/HGxuDW8bIAA2PGj.jpg)