Last year at @tryramp I laid out three predictions for how language models would evolve. I was trying to clarify which bets might actually be durable over time.
A lot of it is now starting to take shape.
Here’s an update. Thread 👇
recipe i have wanted to try, mostly limited by how you get it into peoples hands
1. humans write N skills
2. collect data traces of execution of N skills
3. use traces to train / generate new tasks to RL on
4. train a LoRA
5. now Skills.MD -> Skill LoRA
6. Give agent a tool to apply LoRA to itself
My favorite part of working on the @trychroma Context-1 report was how easy interactive explanations have become with AI coding.
As a longtime fan of sites like https://t.co/HNG1jAHG5l and https://t.co/Xc5eKOo7Qd the barrier to quickly iterating on and building interactive explainers is now so absurdly low.
No excuse for every developer facing company to not invest in these.
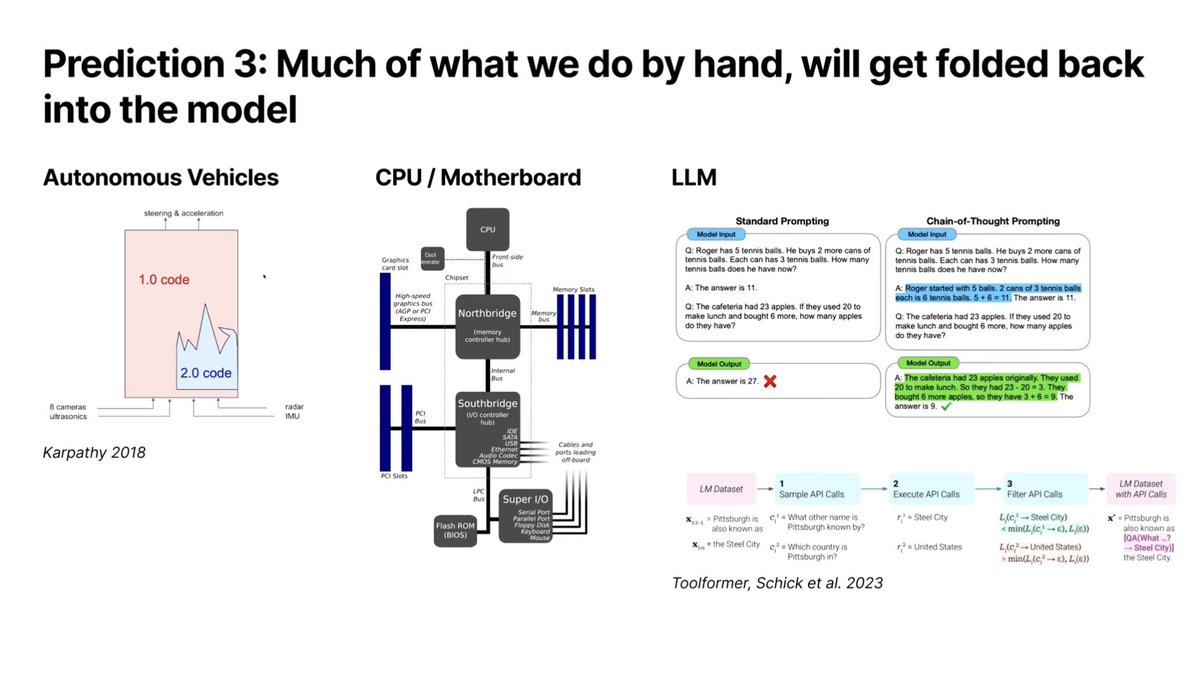
#3 - At first, capability gets discovered outside the model in prompts, chains, routers, tools, human supervision, and harnesses.
As models improve, more of that gets trained in.
This is part of why we bias toward giving models filesystem tools today. These tools are already being post-trained in.
What happens when models get better at generic tool use and composition? (They will.)
Is your system structured in a way that can accommodate that? Can you take advantage of it when it happens?
We’ve seen similar patterns before — in computer vision, and in hardware (e.g. northbridge/southbridge consolidation). Component consolidation is a fairly natural outcome in engineering systems.
@hvent90@trychroma For id hallucination “virtual” simpler ids helps. So map the ids to something simpler like an integer by order of first appearance during the rollout before passing to the model
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
@hvent90@trychroma context-1 is trained on using the prune tool, which edits context. Before training the base model is pretty inaccurate with using it
Scoop! Meta is forming a *new* elite AI lab. And it's not run by Alexandr Wang.
The tech giant quietly reorganized its recommendations division, RecSys.
It formed a top AI team run by TikTok's former head of growth.
RecSys has been luring OpenAI, Google, & Amazon talent.