🧵The way we benchmark generalist manipulation policies is broken.
• A single success rate can't capture a robot's capability.
• Overfitting demonstrations is not generalization.
We built EBench to fix both. EBench is a surgical diagnosis tool for robot foundation models. It provides not a leaderboard, but A CAT scan for your policy.
Here's what it reveals about π0, π0.5, Qwen-RobotManip (@Qwen), and the rest:
@SaketTiwari14 lol thanks! We're very interested in that too. We don't have access to the official π₀.7 model, but we'd love to see @physical_int get involved.😍
🧵The way we benchmark generalist manipulation policies is broken.
• A single success rate can't capture a robot's capability.
• Overfitting demonstrations is not generalization.
We built EBench to fix both. EBench is a surgical diagnosis tool for robot foundation models. It provides not a leaderboard, but A CAT scan for your policy.
Here's what it reveals about π0, π0.5, Qwen-RobotManip (@Qwen), and the rest:
(6/6) We built the infrastructure to match the metric⚙️🚀.
8x RTX 4090 → validation eval in 30 minutes ⏱️. 7×24 online platform 🌐. Auto-generated diagnostic reports with radar charts, migration curves, task-level heatmaps.
This isn't a paper artifact. It's a dev tool you plug into your training loop. Stop optimizing for a single number. Start optimizing for a shape. EBench is the shape factory.
Links: 🔗
📄 Paper: https://t.co/E3qld0HJOV
💻 Code: https://t.co/5pqYA1u6v9
🏆 Eval Platform: https://t.co/v8cA0is2TP
(5/6) EBench is sensitive to pretraining. And that's by design. 🧠📈
Here's something we found: under our strict object-level train-test isolation, models with large-scale pretraining show significantly larger performance gaps from scratch-trained baselines than on existing benchmarks like LIBERO or RoboTwin 2.0.
On EBench, the pretraining signal is visible. On other benchmarks, it gets washed out. If you're investing in pretraining data and compute, you want a benchmark that can actually measure the return.
(4/6) Generalization is where the rubber meets the road. 🛣️
Background & Instruction perturbation? Most models handle it. Object replacement? That's where the gap opens. Composition of all three? The real filter.
Qwen-RobotManip is the only one with a flat generalization curve across all four perturbation types (~45% each). No collapse. Others drop 10–25 points on Object and Mix. That's the signature of a real foundation model, not a benchmark gamer.
(3/6) Qwen-RobotManip just took #1 🥇, but the story is structural, not just numerical.
45.6% Test SR, 60.8% Test Score. But look at the five-dimensional breakdown:
Mobile: 43.8%
Dexterous: 50.0%
Short Horizon: 50.2%
Long Horizon: 33.1%
Low Precision: 50.6%
High Precision: 18.8% ← still the bottleneck
It's not a single spike. It's a *shape*. And that shape tells you exactly where to optimize next.
(2/6) The "overfitting game" is real, and EBench calls it out.
Validation-Train vs Test let you immediately see who's actually generalizing vs who's overfitting the training distribution. π0.5 has the tightest val-test gap. That's why the community feels it's "good at fine-tuning." The numbers finally explain the vibe.
(1/6) The "success rate" era is over 📊.
Every robotics benchmark gives you a number. EBench gives you a *profile*.
26 tasks, 5 dimensions: Operating Mode, Horizon, Precision, Atomic Skill, Scene. Plus 4 generalization axes: Object, Background, Instruction, Composition.
Same model can look like a genius on one slice and a toddler on another. The aggregate score was hiding everything.
🔥 Join our Challenge on Multimodal Robot Learning in InternUtopia and Real World!
🎮 Tasks: Manipulation & Navigation
🗺️ Each track includes an online qualifier and on-site finals
🧰 Starter kits open now
🥇 Winner prize: $10K
🔗 https://t.co/xEIqoH2Z1w
#IROS2025#Robotics
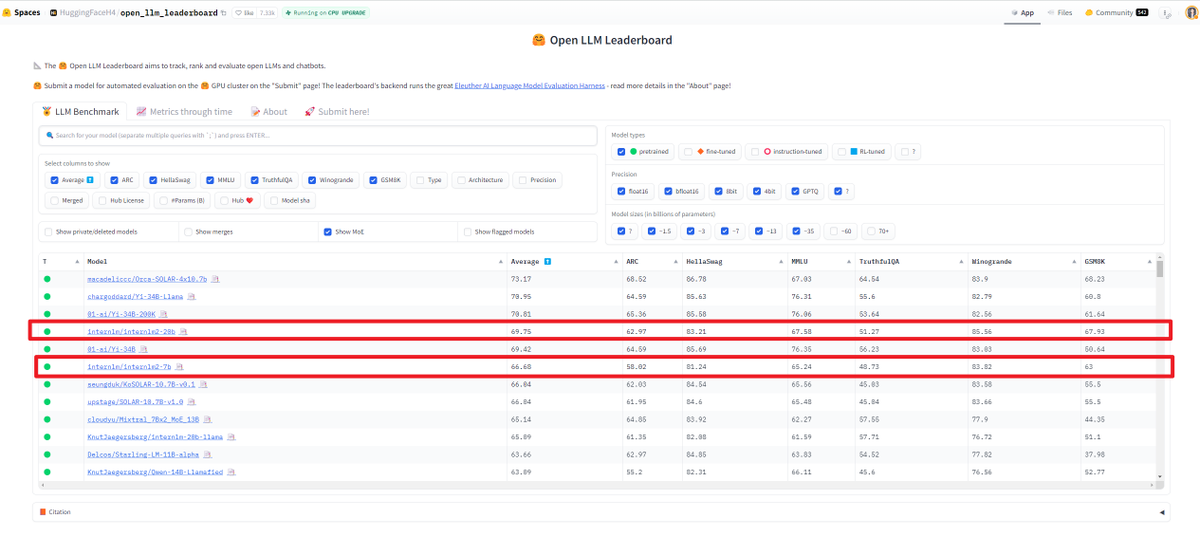
🚀 Exciting news! @intern_lm 7/20B models are now live on the @huggingface Open LLM Leaderboard!
🔍 Highlights:
- 200K context length for base/chat models.
- 20B model is on par with the performance of Yi-34B.
- 7B model is the best in the <= 13B range.
https://t.co/AzpQhlOfhy