Exploring in neural networks from inside purely biological mind with heavy cognition architecture & mapping the phase space where thought becomes destiny.
Can coding-agents replicate scientific ML papers?
We know this is possible because we can already do this @dair_ai.
Still a great read.
So they try to replicate an ML paper from its materials alone.
They use a coding-agent skill that turns each selected paper claim into a target with recorded evidence. The agent reconstructs the method, runs experiments, links outputs to provenance, compares against the paper's claims, and passes validation checks before completion.
Completion depends on workspace evidence, not on the agent's final message.
Across twelve runs over four scientific ML papers, all twelve workspaces pass the completion gate and all 158 recorded targets are matched with report coverage. Yet repeated runs still differ in how papers are split into targets, in numerical fidelity, in elapsed time, and in the rules used to accept evidence.
Basically the completion becomes reproducible even when the path is not.
Paper: https://t.co/IkhknqCUiv
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
Gradient, divergence, and curl decode how scalar and vector fields change through space.
- The gradient of scalar field φ equals ⟨∂φ/∂x, ∂φ/∂y, ∂φ/∂z⟩ and points toward its steepest rise.
- Divergence of vector field F, given by ∂Fx/∂x + ∂Fy/∂y + ∂Fz/∂z, tracks net outward flow to identify sources and sinks.
- Curl of F equals ⟨∂Fz/∂y - ∂Fy/∂z, ∂Fx/∂z - ∂Fz/∂x, ∂Fy/∂x - ∂Fx/∂y⟩ and gauges rotational strength according to the right-hand rule.
Biomedical engineers apply these operators to model blood circulation patterns and detect irregularities in vascular flow.
Sparsity in neural network layers limits both the number of active connections and firing neurons to boost efficiency.
The structure shows the prior layer feeding into a linear transformation stage through sparse weights, which generates intermediate linear values for every unit.
A k-winner-take-all selection then keeps only the strongest units active in the output, producing sparse activations.
It enables faster and more memory-efficient processing in deep learning systems for tasks such as real-time object detection on mobile hardware.
Logistic and softmax regression underpin many classification tasks.
The upper part shows logistic regression: inputs x1 to xm with weights w1 to wm and bias b sum together, sigmoid converts the net input to a probability, and a quantizer thresholds it to binary y.
Error feedback helps adjust the model.
The lower part details softmax regression for k classes. Class-specific weighted sums plus biases go through softmax for probabilities t1 to tk. Argmax determines y, optimized with cross-entropy on one-hot labels.
It flags spam emails and to identifies animal species in wildlife photos.
In the age of AI, the skills that matter most are problem selection and resource allocation. The resources that matter most and are within your control are your time, network, and reputation. Focus on these and the reward will come.
AI is going to shift humanity’s focus from Survival Mode to Creative Mode.
Cognition CEO @ScottWu46:
“ We've been spending all this time living in Survival Mode as a species. Now we're going to be living in Creative Mode.”
”Minecraft Survival Mode is where you're growing food, you're making sure you're safe from the monsters at night.”
“Creative Mode is—everything's up to you. You have all the resources at your disposal. If you want something to happen, it'll happen. The only question for you is: what do you want to make happen?”
NEW paper worth reading.
(bookmark it)
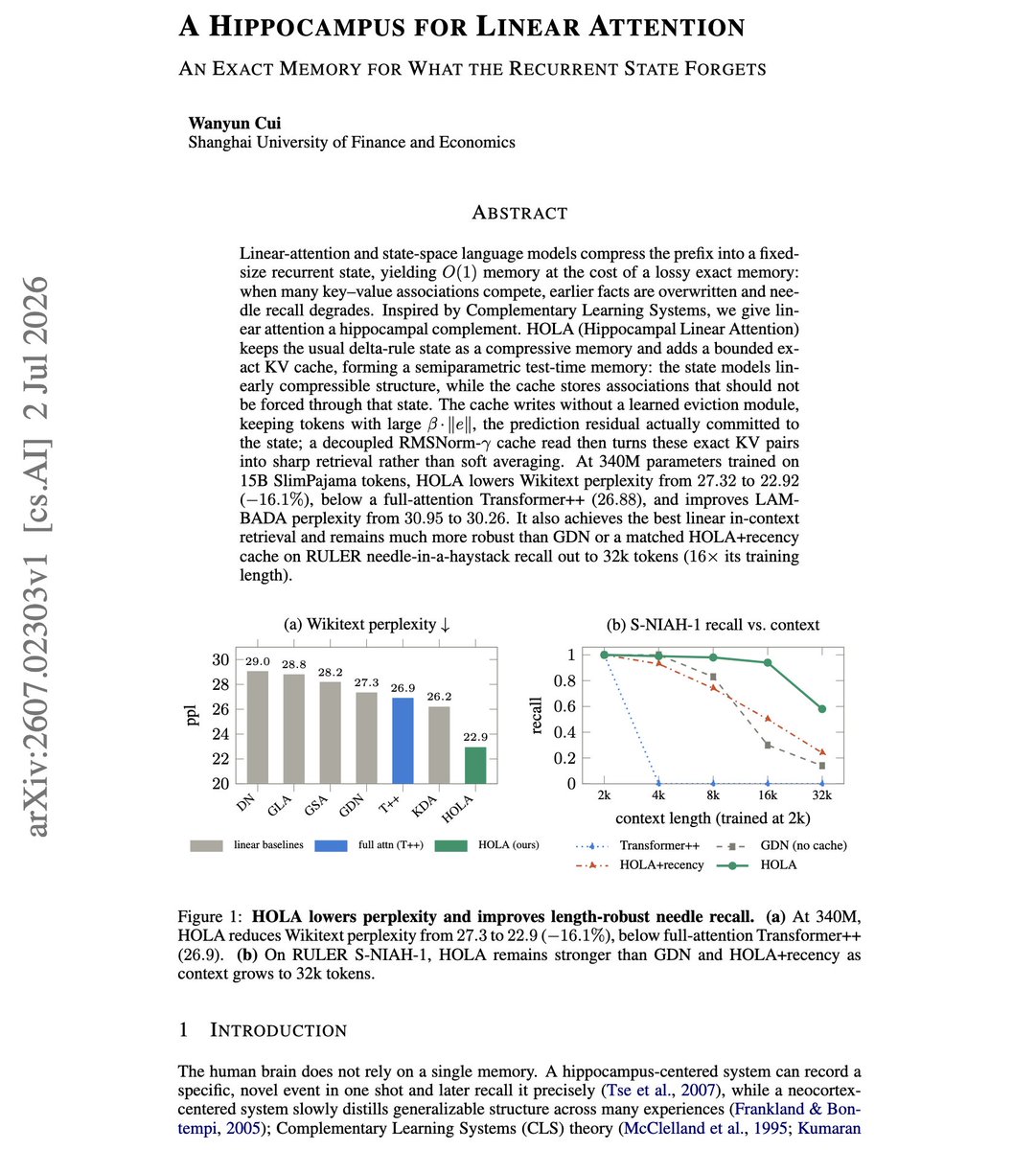
The basic idea is to pair a compressive recurrent state with a small exact memory, which helps to recover long-range recall without giving up the efficiency of linear attention.
More on it below:
Linear-attention and state-space models compress the whole prefix into a fixed-size state. That buys O(1) memory, but when many key-value associations compete, earlier facts get overwritten and needle recall degrades.
HOLA gives linear attention a hippocampal complement. It keeps the usual delta-rule state as compressive memory and adds a bounded exact KV cache, forming a semiparametric test-time memory.
The state models linearly compressible structure while the cache stores associations that should not be forced through it. The cache writes without a learned eviction module, keeping only tokens whose prediction residual was actually committed to the state.
At 340M parameters on 15B SlimPajama tokens, HOLA lowers Wikitext perplexity from 27.32 to 22.92, below a full-attention Transformer++ at 26.88, and stays robust on RULER needle recall out to 32k tokens, 16x its training length.
Paper: https://t.co/z1Jzp7qQ6B
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Cognitive scientist Joscha Bach:
"at the moment, we are not building systems that are minds — we are building systems that predict text and visual patterns made for human consumption"
True machine perception has never been tried, but once it is, it may surpass human reasoning
The new @GoogleDeepMind Omni video is amazing! This is the best cartoon animation of a T cell killing a cancer cell that I was able to create to date! I love it 😍
I cannot wait for the debut of our coding agents with computer use on public harnesses like OpenCode and Cursor. I’ve been testing it for a while. Go Muse Spark!
For decades, biology textbooks have enshrined a simple rule: DNA is made by copying a template. After one enzyme unzips a DNA double helix into separate strands, another called a polymerase builds a complementary sequence, base by base, for each strand. Presto: two copies of the original DNA.
But recent research into how bacteria defend themselves from viruses now shows this synthesis rule isn’t absolute. The team describes a bacterial enzyme that synthesizes DNA without a nucleic acid template, using its own structure as a guide.
Learn more: https://t.co/TeUWvyO0OD @NewsfromScience
Introducing EdgeBench, a benchmark designed to study how agents learn from environments over at least 12~72-hour runs. We find that performance follows a log-sigmoid function of environment interaction time with high precision.
EdgeBench is built with three ingredients:
- 🌍 Real & Diverse: 134 real-world tasks across 6 task categories, spanning scientific problems, professional knowledge work, software engineering, optimization, formal math, and games.
- ⏳ Ultra-Long-Horizon: Each task supports 12–72 hours of agent work. Recorded human effort averages 57.2 hours.
- 🔁 Informative Feedback: Agents receive real-world feedback for continuous improvement.
After 38,000 hours of agent runs on EdgeBench, a scaling law for learning from environments emerges:
- 📈 As agents interact with task environments over time, their aggregate performance is precisely fit by a log-sigmoid function.
- 🧠 This phenomenon can be explained by an elegant theory of graph exploration.
We are releasing an initial 51 of the 134 tasks, together with the full evaluation framework, to help advance long-horizon agent research. Check our blog & paper for more findings!
Blog https://t.co/nMOzFsOhbT
Paper https://t.co/rZb3eWuvik
GitHub https://t.co/oemXd4UrFw
Dataset https://t.co/P4SQMrM47o
Details below 👇🧵