We are announcing our shared task on narrative similarity and narrative representations. SemEval 2026 Task 4: https://t.co/jYfydWXv2C.
We invite you to benchmark LLMs, embedding models, or even test your favorite narrative formalism. Development data is now available!
Search/acc⏩Probably the hottest BoF at #EMNLP2024! Nearly 100 researchers packed the room for 12 back-to-back talks on search foundation models - covering everything from code embeddings, distilled rerankers, ColPali, ColBERT, late chunking & smaller LMs. Killer lineup featuring @HansHatzel@gangi_official@Robro612@ManuelFaysse@zhichaoxu_ir @memray0 @SFResearch and many others! Big thanks to everyone who came out and showed such enthusiasm for search foundation models! 🙌 We are looking forward to seeing you next @emnlpmeeting!
Let’s discuss:
- How could story embeddings be useful in your work?
- Why don’t our embeddings work well for retellings?
- How can story embeddings be improved upon?
More details in the paper!
Paper: https://t.co/pg5jP9Ihfi
Github: https://t.co/TJmrpAktc1
🧵 (6/6)
Excited to tell you all about our EMNLP paper on story embeddings! We present a novel approach for representing story summaries as embeddings. This is my first proper paper thread, so please be kind 😅
See you in Miami! 😎
🧵 (1/6)
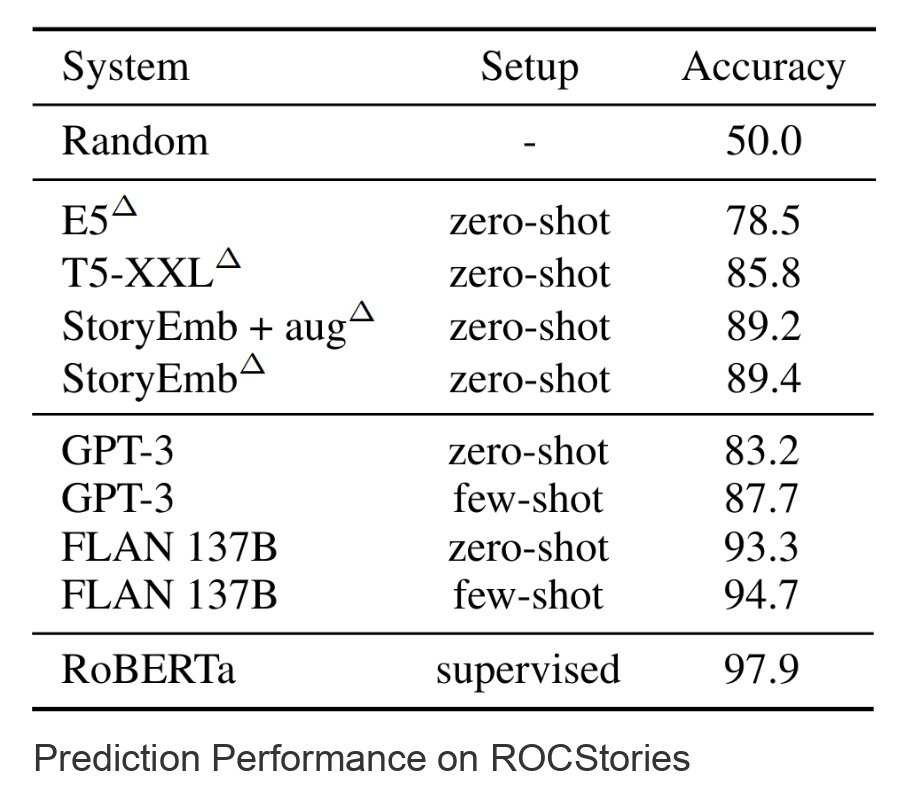
Our paper has plenty of experiments on measuring embedding capabilities for retrieval and exploring which aspects of story summaries our embeddings focus on. Big surprise: the embeddings perform well on ROCStories, a commonsense reasoning task.
🧵 (5/6)
What should the ACL peer review process be like in the future? Please cast your views in this survey: https://t.co/fBGWIwXRCo by 4th Nov 2024 #NLProc@ReviewAcl
"Tell me again! A Large-Scale Dataset of Multiple Summaries for the Same Story" a dataset of 96k summaries across 29l stories, harvested from five language versions of Wikipedia, and annotated with metadata from Wikidata.
(Hatzel and Blemann, 2024)
https://t.co/nreZw3Mc33
@PyTorch Some native dependencies didn't compile on the target system (either due to compiler versions or native libraries). I ended up building a docker image which had everything pre-installed (based on the torchserve one); worked well but it's a bit of work. Conda is typically easier.
@PyTorch When deploying models using torchserve you can (iirc) specify a requirements.txt but this is not feasible for large libraries with native dependencies. Are there easy ways to specify a complete environment (e.g. via conda)? I found this to be the main pain point in demo hosting.
@RealAAAI Not sure if this is a good way to reach out but this link and any paper from the conference seem to be unavailable (HTTP 500): https://t.co/cLPC9aX3ya