We are really taking a long time to prove this: everyone is building big macs but we bring you a kiwi🥝 instead.
You have multimodal with K2.5 everywhere: chat with visual tools, code with vision, generate aesthetic frontend with visual refs...and most basically, it is a SUPER POWERFUL VLM
As long as K2.5/K2.6 is multimodal, we are also making it to use (I am really amazed by how it excels at long multi-image documents because we are not specially optimizing for them too much)
However still a long way to go
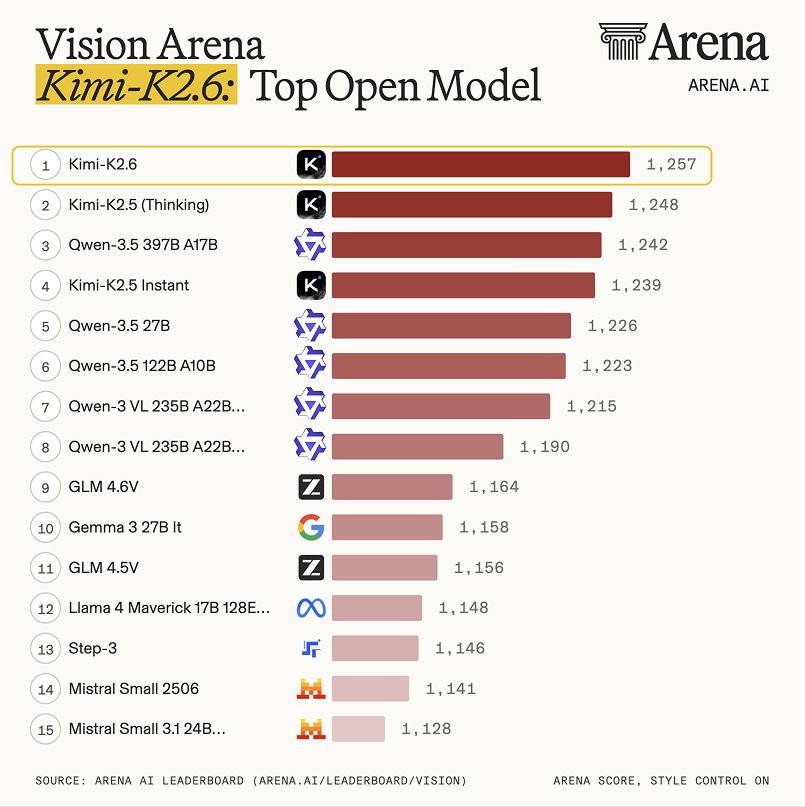
Kimi K2.6 is the new SOTA open model in Vision and Document Arena, with solid gains since Kimi K2.5:
- #1 open on Vision Arena (#15 overall), +14 over #2 Kimi K2.5 (Thinking)
- #1 open on Document Arena (#8 overall), +9 over K2.5 and on par with proprietary models like Muse Spark and Gemini 3.1 Pro.
Huge congrats again to the @Kimi_Moonshot team on the open source progress!
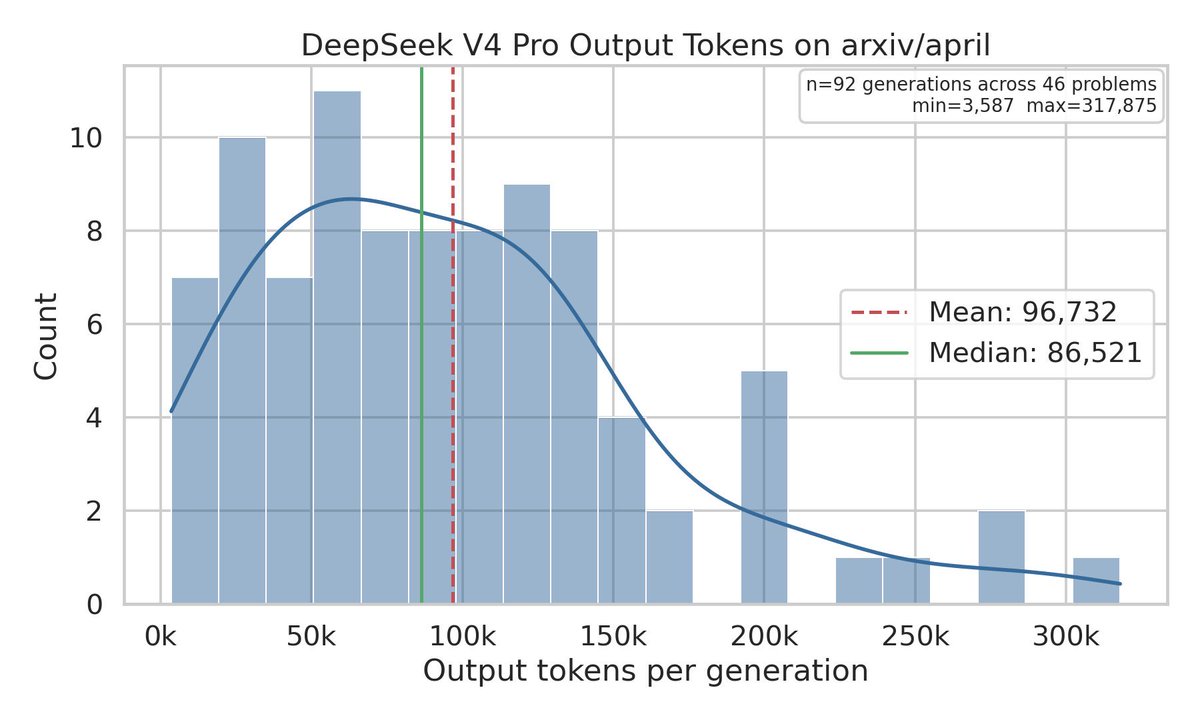
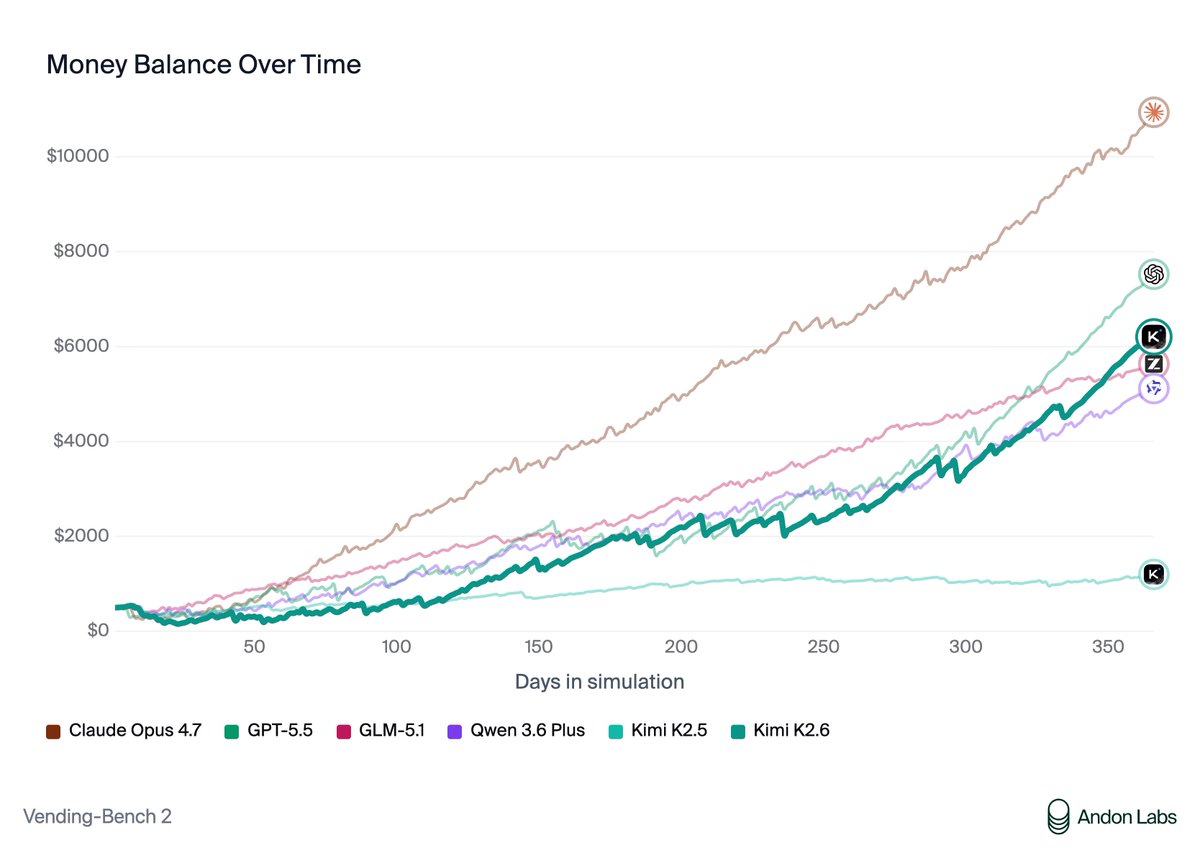
The 🐳 has surfaced and it’s a powerhouse on the Vals leaderboards, dominating on coding. DeepSeek V4 just landed #2 on the Vals Index, nearly tying Kimi K2.6 (only 0.07% behind).
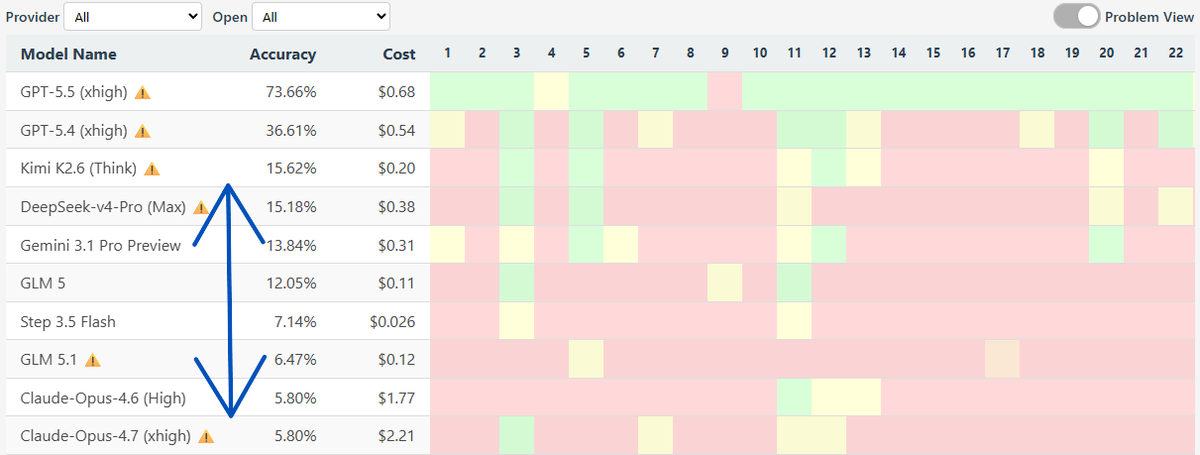
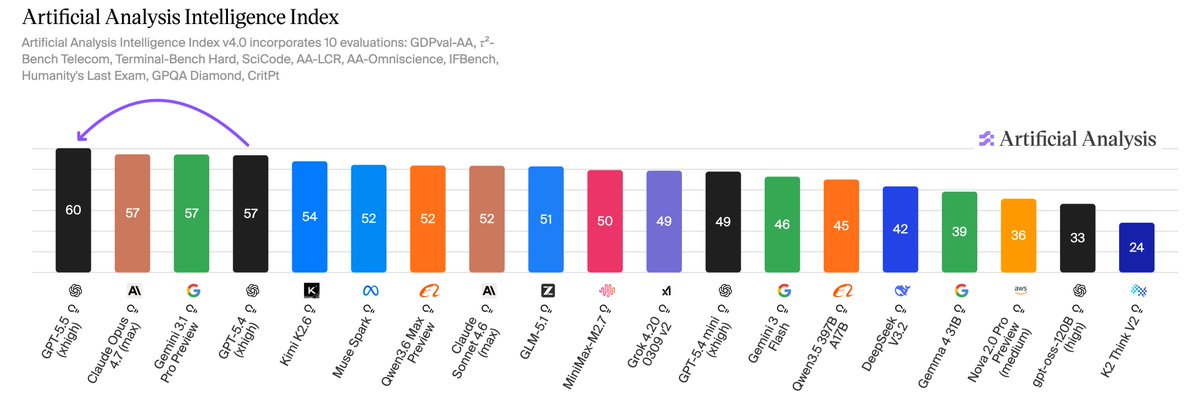
GPT-5.5 takes OpenAI back to the clear number one in AI. OpenAI’s new model tops the Artificial Analysis Intelligence Index by 3 points, breaking a three-way tie with Anthropic and Google
OpenAI gave us pre-release access to test all five reasoning effort levels: xhigh, high, medium, low and non-reasoning.
➤ OpenAI topping five headline evaluations: GPT-5.5 (xhigh) leads Terminal-Bench Hard, GDPval-AA and our newly hosted APEX-Agents-AA. The model trails only other OpenAI models in CritPt and AA-LCR, and comes second to Gemini 3.1 Pro Preview on three additional evaluations. The largest gains are on AA-Omniscience (+14 pts), our knowledge and hallucination benchmark, and τ²-Bench Telecom (+7 pts), a customer service agent benchmark.
➤ 20% more expensive to run our Intelligence Index: Per-token pricing has doubled from GPT-5.4 to $5/$30 per 1M input/output tokens. However, a ~40% token use reduction largely absorbs the hike - resulting in a net ~+20% cost to run our Intelligence Index.
➤ Effort a clear ladder for balancing intelligence and cost: GPT-5.5 (medium) scores the same as Claude Opus 4.7 (max) on our Intelligence Index at one quarter of the cost (~$1,200 vs $4,800) - although Gemini 3.1 Pro Preview scores the same at a cost of ~$900. GPT-5.5 (low) approximates Claude Opus 4.7 (Non-reasoning, high) on our Intelligence Index at half the cost to run (~$500 vs ~$1 ,000).
➤ Number one in GDPval-AA with an Elo of 1785: GPT-5.5 (xhigh) leads Claude Opus 4.7 (max) by ~30 pts and Gemini 3.1 Pro Preview by ~470 pts. GDPval-AA is Artificial Analysis’ benchmark that leverages OpenAI’s GDPval dataset to evaluate models on real-world economically valuable tasks.
➤ Top AA-Omniscience accuracy, but trailing the frontier on hallucination: Our private AA-Omniscience benchmark rewards factual knowledge across diverse topics, but punishes hallucination. GPT-5.5 (xhigh) has the highest accuracy at 57% - meaning the model can recall facts in the Omniscience corpus more effectively than any other model. However, it has a hallucination rate of 86% - vs Opus 4.7 (max) at 36%, and Gemini 3.1 Pro Preview at 50%. This makes it more likely to answer a question when it does not ‘know’ the answer. The 14 pt gain in AA-Omniscience from GPT-5.4 (xhigh) was largely driven by knowledge, with a modest improvement in hallucination.
Congratulations to the team at @OpenAI and @sama on the launch
@teortaxesTex hope they be fast... (from my very personal perspective day-0 open-source is better than day-X open-source but I am not working for business teams just a model trainer
💥 Kimi-K2.6-thinking is the new best open-weight model on HalluHard (without web search)!
K2.5 had 76.9% hallucination rate, whereas K2.6 now has 63.6%. Since our benchmark contains hard hallucination cases, this improvement is very notable.
Thank you @Kimi_Moonshot for providing API credits and @dyfan22 for running the eval!
Full results: https://t.co/BFzcZWC555
Paper: https://t.co/kKxIapQjkB