this one is special.
it has been quite a ride. we built the entire training pipeline and data stack from scratch.
today we shipped ZAYA1-VL-8B: a strong compact MoE VLM that punches above its weight class.
so proud of this team. and we're just getting started🚀
Today we're releasing ZAYA1-VL-8B, our first vision-language model.
ZAYA1-VL-8B is a 700M active / 8B total MoE built on our ZAYA1-8B base trained on @AMD. We achieve strong performance for our size resulting in leading intelligence density and inference efficiency.
Zyphra Research is releasing Norm-AGnostic residual networks (NAG) - a new architecture that mitigates the diminishing returns of deeper residual models by controlling the residual stream geometry.
NAG makes Mixture-of-Depths practical for pretraining.
Today we're releasing ZONOS2, our next-generation real-time TTS model with high-fidelity voice cloning.
ZONOS2 is the most expressive open-source TTS model, released under Apache 2.0 and available on Zyphra Cloud on @AMD. 🧵
Vision workloads are notoriously demanding on memory and compute. Exploring SSMs in vision-language models opens up a different part of the design space—one where efficiency and capability can scale together.
Zyphra Research continues to explore architecture innovations beyond standard transformers.
Today we’re releasing Zamba2-VL, extending our prior Zamba2 hybrid SSM-Transformer work into vision-language modeling. 🧵
It all started with a basic question: what happens when you bring hybrid SSM-Transformer architectures to multimodal intelligence?
Zamba2-VL is an early step toward that future. Huge credit to our vision team for making it happen.
Zamba2-VL is competitive with the leading open Transformer vision-language models of comparable scale, including Qwen3-VL, InternVL3.5, Molmo2, and PerceptionLM, across image understanding, reasoning, OCR, grounding, and counting benchmarks.
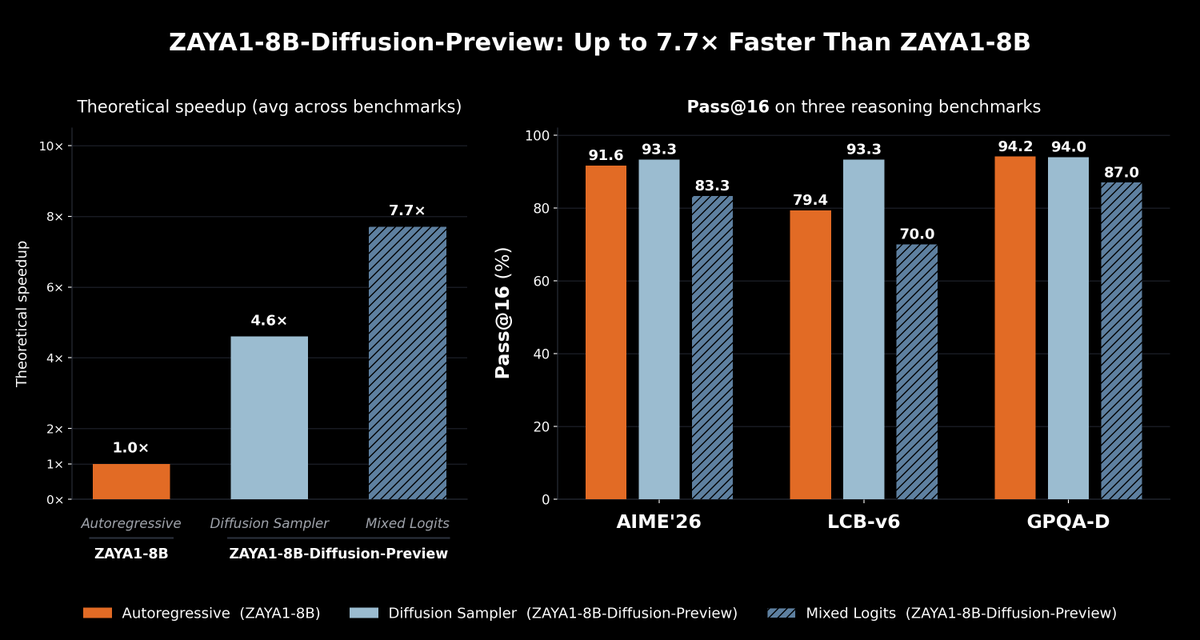
We present ZAYA1-8B-Diffusion-Preview, the first diffusion language model trained on @AMD.
Autoregressive LLMs generate one token at a time; diffusion generates a block in parallel, speeding up inference.
We show a 4.6-7.7x decoding speedup with minimal quality degradation 🧵
Today we're releasing ZAYA1-74B-Preview, a major milestone in scaling pretraining on @AMD.
ZAYA1-74B-Preview is a 4B active / 74B total MoE.
This preview model is a strong pre-RL base checkpoint. The final post-trained reasoning model is coming soon. 🧵
this model, and our next release was an insane ad hoc learning experience in scaling and reasoning about pretraining for me. All credit goes to @rawsh0 and team for extracting the most out of the pretraining base. It is insanely strong for its size
new model! strong <1B active MoE
led data and posttraining for this release. cca goat @rishiiyer01 and the pretraining squad cooked
https://t.co/j808U7FxG5
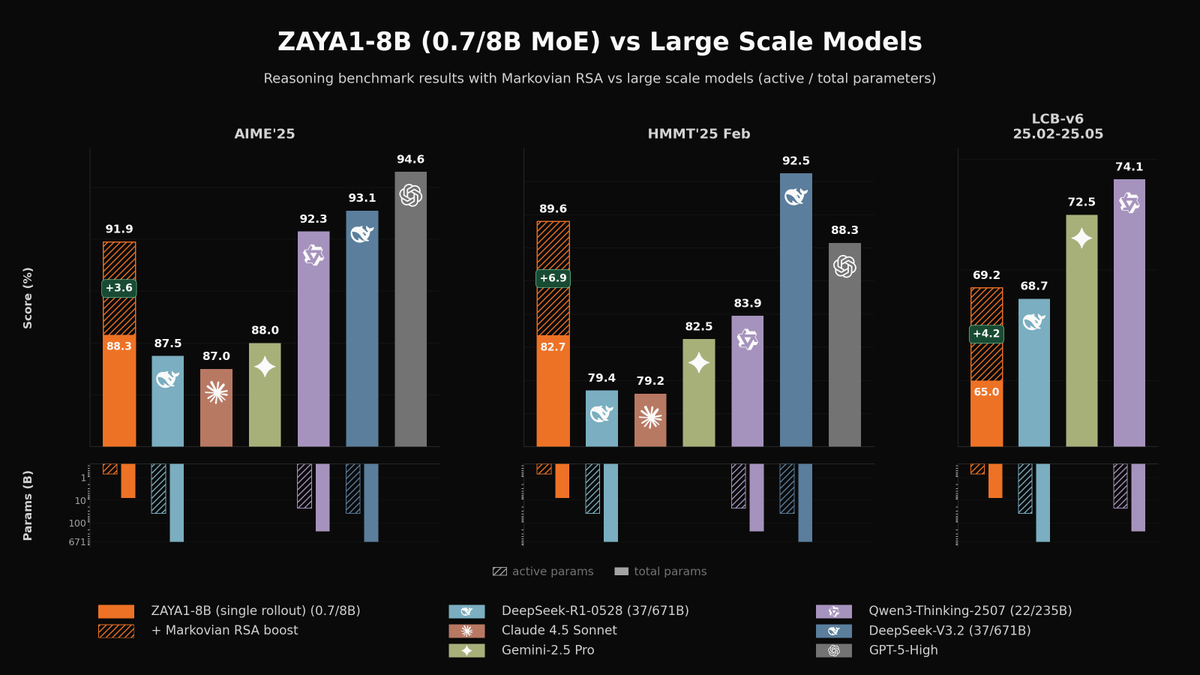
Incredible work from the entire Zyphra team for this one! We never expected that our small ZAYA1 would be able to compete (at least in math) with the frontier giants. Our post-training and pre-training stacks are strong.
More general thoughts on the ZAYA release, a 🧵
@ZyphraAI is an open superintelligence research and product company based in San Francisco, CA on a mission to build human-aligned AI that helps individuals and organizations reach their fullest potential.
Apply to join us! https://t.co/1Eika8rWxz
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
@ZyphraAI releases research on a new way to build hybrid models. We introduce a new architecture leveraging the complementary strengths of Transformers and RNNs for greater flexibility and performance than existing approaches.
We call it Hybrid Associative Memory (HAM). 🧵
Zyphra is hiring out of our new office in San Francisco.
We are on the mission to build open superintelligence and have multiple roles open across research, engineering, product, and GTM.
Join us: https://t.co/pqARkkw2hK
Happy Noruz, the first day of Spring, the Persian new year.
May the new year bring peace to the innocent, and wisdom to the powerful who can bring it about.
Introducing ZUNA, a 380M-parameter BCI foundation model for EEG data, a significant milestone in the development of noninvasive thought-to-text.
Fully open source, Apache 2.0.