Principal Research Scientist & Director @GoogleDeepMind, Gemini Team | Lead of Gemini Deep Think, LaMDA | Worked on Duplex, TensorFlow, Wide & Deep | Hiring!
Today I'm really excited to share a major upgrade to our Gemini 3 Deep Think that we've been building. I was deeply inspired to see how scientists and engineers use our model to help discover new semiconductor materials, accelerate engineering design, and identify blind spots in frontier math research. Achieving ICPC & IMO Gold few months ago was already a big milestone — but this is a big leap forward. The new Deep Think achieved unprecedented results on hard benchmarks like ARC-AGI-2, new heights on math and competitive coding, and Gold medal-level performance on the written sections of 2025 International Physics Olympiad and Chemistry Olympiad. It's an honor to have the opportunity to work with the whole Gemini team and many amazing collaborators to make this happen. It felt like a dream come true.
Really looking forward to seeing what you will discover with Gemini 3 Deep Think! 🚀
Learn more: https://t.co/WdumeXb8Xq
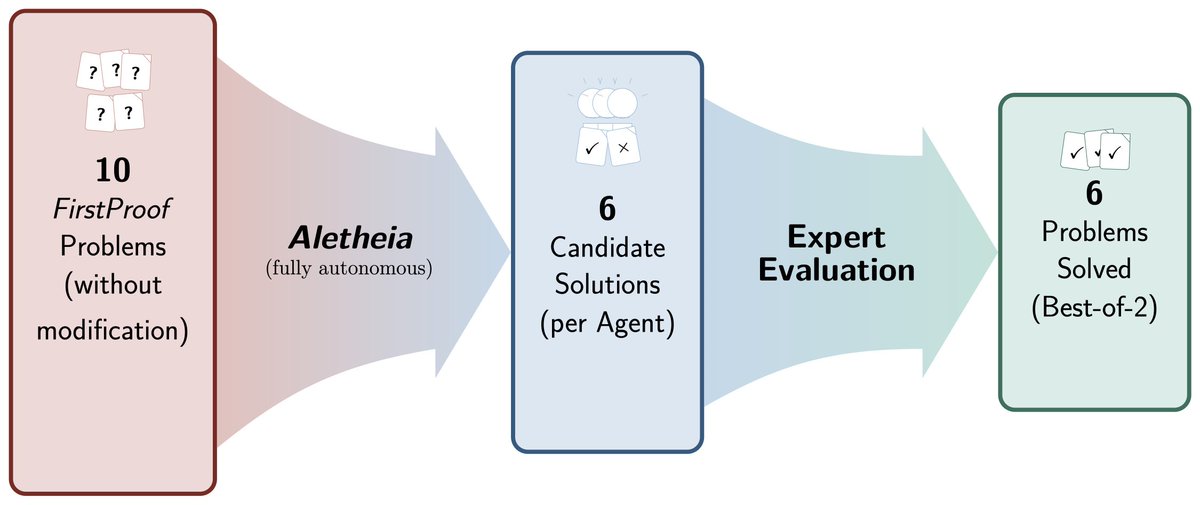
Aletheia, a math research agent powered by our latest Gemini 3 Deep Think, just solved 6/10 FirstProof problems autonomously! Incredible to see AI solving increasingly hard research-level problems.
Thrilled to share: #Aletheia, our math research agent, just solved 6/10 notoriously hard FirstProof problems autonomously, the best result in the inaugural challenge! To me, this is even bigger than our historic IMO-gold achievement last year; these problems challenge even top mathematicians. We share our results transparently, see paper and full thoughts in the thread. 👇
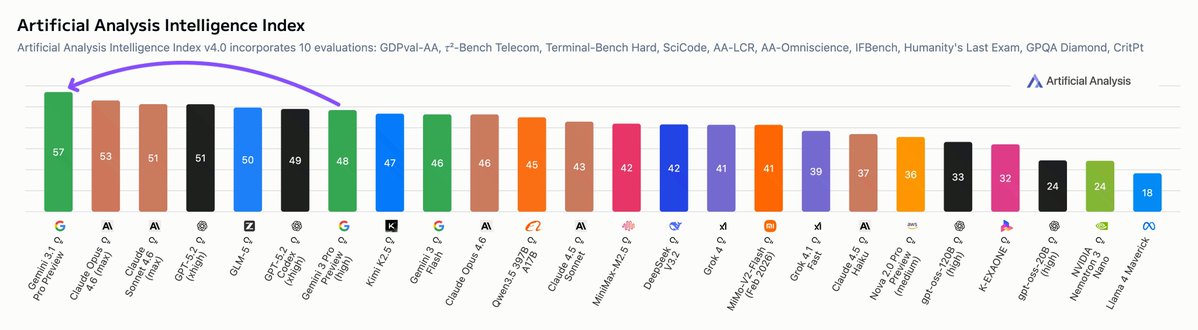
Google is once again the leader in AI: Gemini 3.1 Pro Preview leads the Artificial Analysis Intelligence Index, 4 points ahead of Claude Opus 4.6 while costing less than half as much to run
@GoogleDeepMind gave us pre-release access to Gemini 3.1 Pro Preview. It leads 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index and improves significantly over Gemini 3 Pro Preview across capabilities, with the biggest gains in reasoning and knowledge, coding, and hallucination reduction.
Gemini 3.1 Pro Preview also remains relatively token efficient, using ~57M tokens to run the Artificial Analysis Intelligence Index (+1M from Gemini 3 Pro Preview), lower than other frontier models at max reasoning settings such as Opus 4.6 (max) and GPT-5.2 (xhigh). Combined with lower per-token pricing, Gemini 3.1 Pro Preview is cost-efficient among frontier peers, costing less than half as much as Opus 4.6 (max) to run the full Intelligence Index, though still nearly 2x the leading open-weights model, GLM-5.
Key Takeaways:
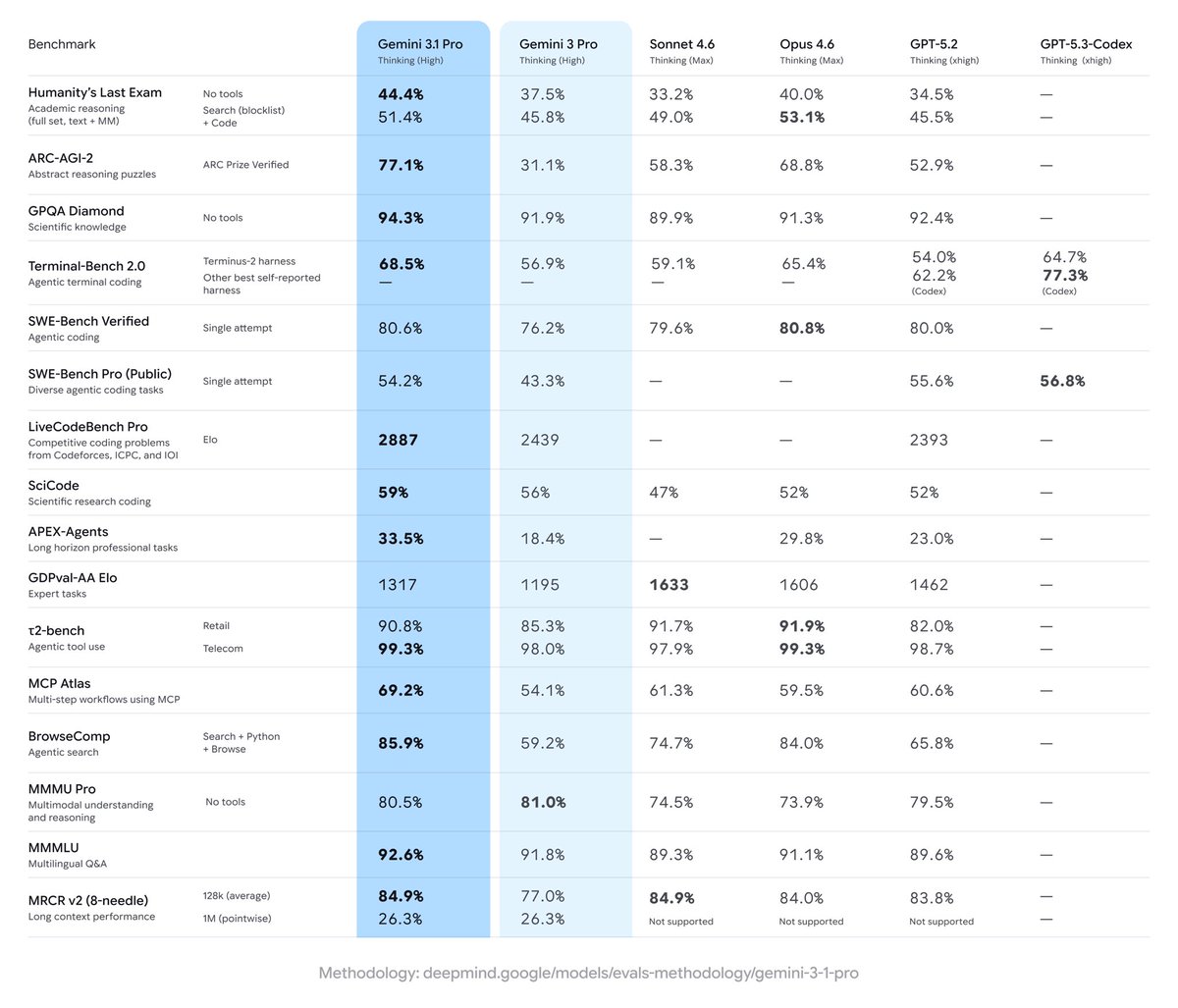
➤ State-of-the-art intelligence at lower costs: Gemini 3.1 Pro Preview is leading 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index at less than half the cost to run of frontier peers from @OpenAI and @AnthropicAI. It obtains the highest score in Terminal-Bench Hard (agentic coding), AA-Omniscience (knowledge & hallucination), Humanity’s Last Exam (reasoning & knowledge), GPQA-Diamond (scientific reasoning), SciCode (coding) and CritPt (research-level physics). The CritPt score is particularly notable, scoring 18% on unpublished, research-level physics reasoning problems, over 5 p.p. above the next best model
➤ Improved real-world agentic performance, but not leading: Gemini 3.1 Pro Preview shows an improvement in GDPval-AA, our agentic evaluation focusing on real-world tasks, but is still not the leading model in this area. The model increases its ELO score over 100 points to 1316 (up from Gemini 3 Pro Preview), however still sits behind Claude Sonnet 4.6, Opus 4.6, GPT-5.2 (xhigh), and GLM-5
➤ Leading coding abilities: Gemini 3.1 Pro Preview leads the Artificial Analysis Coding Index, achieving the highest score in both Terminal-Bench Hard (54%) and SciCode (59%)
➤ Reduced hallucinations: Gemini 3.1 Pro Preview shows a major improvement in tendency to guess incorrectly when it doesn’t know the answer, reducing its AA-Omniscience hallucination rate by 38 p.p. from Gemini 3 Pro Preview
➤ Maintained token and cost efficiency: Gemini 3.1 Pro Preview improves without material increases in cost or token usage. It uses only ~2% more tokens to run the Artificial Analysis Intelligence Index than Gemini 3 Pro Preview, and keeps the same pricing ($2/$12 per 1M input/output tokens for ≤200k context). Its cost to run the Artificial Analysis Intelligence Index of $892 is less than half of frontier models such as Opus 4.6 (max) and GPT-5.2 (xhigh), though still ~2x the cost of leading open weights models such as GLM 5 ($547)
➤ Google takes top 3 spots in multi-modality: Gemini 3.1 Pro Preview ranks #1 on MMMU-Pro, our multimodal understanding and reasoning benchmark, ahead of Gemini 3 Pro Preview and Gemini 3 Flash, reinforcing Google’s leadership in multimodal reasoning
➤ Other model details: Gemini 3.1 Pro Preview retains the same 1 million token context window as its predecessor, and includes support for tool calling, structured outputs, and JSON mode
Just one week following our major upgrade to Gemini 3 Deep Think, today we’re introducing Gemini 3.1 Pro! 77.1% ARC-AGI-2 level advanced reasoning, more than double of Gemini 3 Pro, will be available to consumers, developers, and enterprises. Really excited to bring the upgraded core intelligence to everyone!
Learn more: https://t.co/GPW16m9VcK
Really excited to share that the Gemini Deep Think that we’ve been building can now help accelerate knowledge discovery and tacking open research problems across many domains! This is a big step forward since our ICPC & IMO Gold few months ago.
6 months in, after the IMO-gold achievement, I’m very excited to share another important milestone: AI can help accelerate knowledge discovery in mathematics, physics, and computer science! We’re sharing Two new papers from @GoogleDeepMind and @GoogleResearch that explore how Gemini #DeepThink together with agentic workflows can empower mathematicians and scientists to tackle professional research problems. Some highlights:
The first paper built a research agent #Aletheia, powered by an advanced version of Gemini Deep Think, that can autonomously produce publishable math research and crack open Erdős problems.
The second paper, built on similar agentic reasoning ideas, helped resolve bottlenecks in 18 research problems, across algorithms, ML and combinatorial optimization, information theory and economics.
See the thread for details about the two papers and the joint blog post.
We’re rolling out Gemini 3 Deep Think to Gemini App Ultra users today! This is building on our recent advances in Deep Think that achieved ICPC & IMO Gold-level performances. https://t.co/91Q7F8p9Oa
Introducing Gemini 3, our most intelligent model yet! Really step-function improvements across many capabilities. Super proud and grateful for the whole Gemini team and all collaborators across Google! https://t.co/xHer1olI8N
Introducing Gemini 3 ✨
It’s the best model in the world for multimodal understanding, and our most powerful agentic + vibe coding model yet. Gemini 3 can bring any idea to life, quickly grasping context and intent so you can get what you need with less prompting.
Find Gemini 3 Pro rolling out today in the @Geminiapp and AI Mode in Search. For developers, build with it now in @GoogleAIStudio and Vertex AI.
Excited for you to try it!
Excited to share Gemini 3 Deep Think! We’re continuing to push the boundaries of advanced reasoning, building on our previous ICPC and IMO Gold medal-level performance. Learn more at https://t.co/PnHcGehcyU
I’m excited to announce that an advanced version of Gemini Deep Think achieved gold-medal level performance at the 2025 ICPC World Finals, one of the world’s most prestigious programming competitions! 🥇Learn more in our blog post: https://t.co/ktPxOO8pIN
An inspiring moment for me personally was when our model solved a problem that no university team solved during the contest — a true moment of innovation. With Gemini Deep Think achieving gold-level across ICPC & IMO, I think we’re seeing a profound leap in generalization across coding, math and reasoning capabilities, to generate novel solutions to complex problems.
This is a huge milestone for us on an amazing journey. Really grateful and proud of our team, for all the hard work and teamwork that made this breakthrough possible. Looking forward to continuing our research, helping people use Gemini to solve some of the hardest unsolved problems in the world!
Excited to launch the most intelligent Gemini model we’ve worked on! Great to see our whole team’s hard work continued to push the boundaries of AI and help all of our Gemini users. Onwards!
BREAKING: Gemini 2.5 Pro is now #1 on the Arena leaderboard - the largest score jump ever (+40 pts vs Grok-3/GPT-4.5)! 🏆
Tested under codename "nebula"🌌, Gemini 2.5 Pro ranked #1🥇 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer Query, and Multi-Turn!
Massive congrats to @GoogleDeepMind for this incredible Arena milestone! 🙌
More highlights in thread👇
We've been working hard on improving our Gemini models, and excited to share this latest Gemini 1.5 Pro model ranking #1 on LMSYS. Try it at https://t.co/5QrW75Iel7. Super proud of the progress by our whole Gemini team, and grateful for the amazing collaborations. Onwards!
Exciting News from Chatbot Arena!
@GoogleDeepMind's new Gemini 1.5 Pro (Experimental 0801) has been tested in Arena for the past week, gathering over 12K community votes.
For the first time, Google Gemini has claimed the #1 spot, surpassing GPT-4o/Claude-3.5 with an impressive score of 1300 (!), and also achieving #1 on our Vision Leaderboard.
Gemini 1.5 Pro (0801) excels in multi-lingual tasks and delivers robust performance in technical areas like Math, Hard Prompts, and Coding.
Huge congrats to @GoogleDeepMind on this remarkable milestone!
Gemini (0801) Category Rankings:
- Overall: #1
- Math: #1-3
- Instruction-Following: #1-2
- Coding: #3-5
- Hard Prompts (English): #2-5
Come try the model and let us know your feedback!
More analysis below👇
We’ve built Gemini Advanced and can’t wait for you to try it out, starting today at https://t.co/0txNPBBOmV!
For technical details, check out our updated Gemini tech report: https://t.co/keyV5CgOEP
Welcome to the next chapter in the Gemini era. ✨
We’re bringing our models to more @Google products you know, use & love.
From today, Bard will be known as Gemini — and you can access our most capable model, Ultra 1.0, with Gemini Advanced. → https://t.co/EfD6YDn6oK #GeminiAI