Thrilled to share that today we report our human protein interactome in @ScienceMagazine! Predicting which pairs of proteins in the human proteome is a great challenge due to the shallow eukaryotic evolutionary signals but hugely important to understand. https://t.co/OtDqhcfG19
We are pleased to share our new preprint: “De novo design of RNA and nucleoprotein complexes”.
This work extends the principles of de novo protein design to RNA and DNA, enabling the generative design of complex multi-polymer structures! (1/6)
https://t.co/QPqpNZr0er
pH gradients are central to physiology, from vesicle acidification to the acidic tumor microenvironment. But how do we program proteins to respond to pH? In our new preprint https://t.co/ovuJf8D6m4, we developed computational methods to rationally design pH-sensitive binders. 🧵
Phosphorylation on tyrosines control key pathways in immunity, cancer, and metabolism. For the first time, we can now design proteins that specifically recognize individual phosphotyrosines, even in disordered regions. (1/8)
Preprint: https://t.co/iIucGbMSDp
We sought to make proteins both potent and FAST. We used #proteindesign to design precise control over protein interaction lifetimes, enabling us to construct rapid-response circuits, biosensors, and switchable cytokines. Now published @Nature! Links to paper and tutorial below.
Thrilled to share that today we report our human protein interactome in @ScienceMagazine! Predicting which pairs of proteins in the human proteome is a great challenge due to the shallow eukaryotic evolutionary signals but hugely important to understand. https://t.co/OtDqhcfG19
This effort is the culmination of a series of proteome interaction prediction stories from Ecoli (https://t.co/9Cn55FaGQL), to yeast (https://t.co/DqKtaIrzXw), and human bacterial pathogens (https://t.co/NPKmEJzils)!
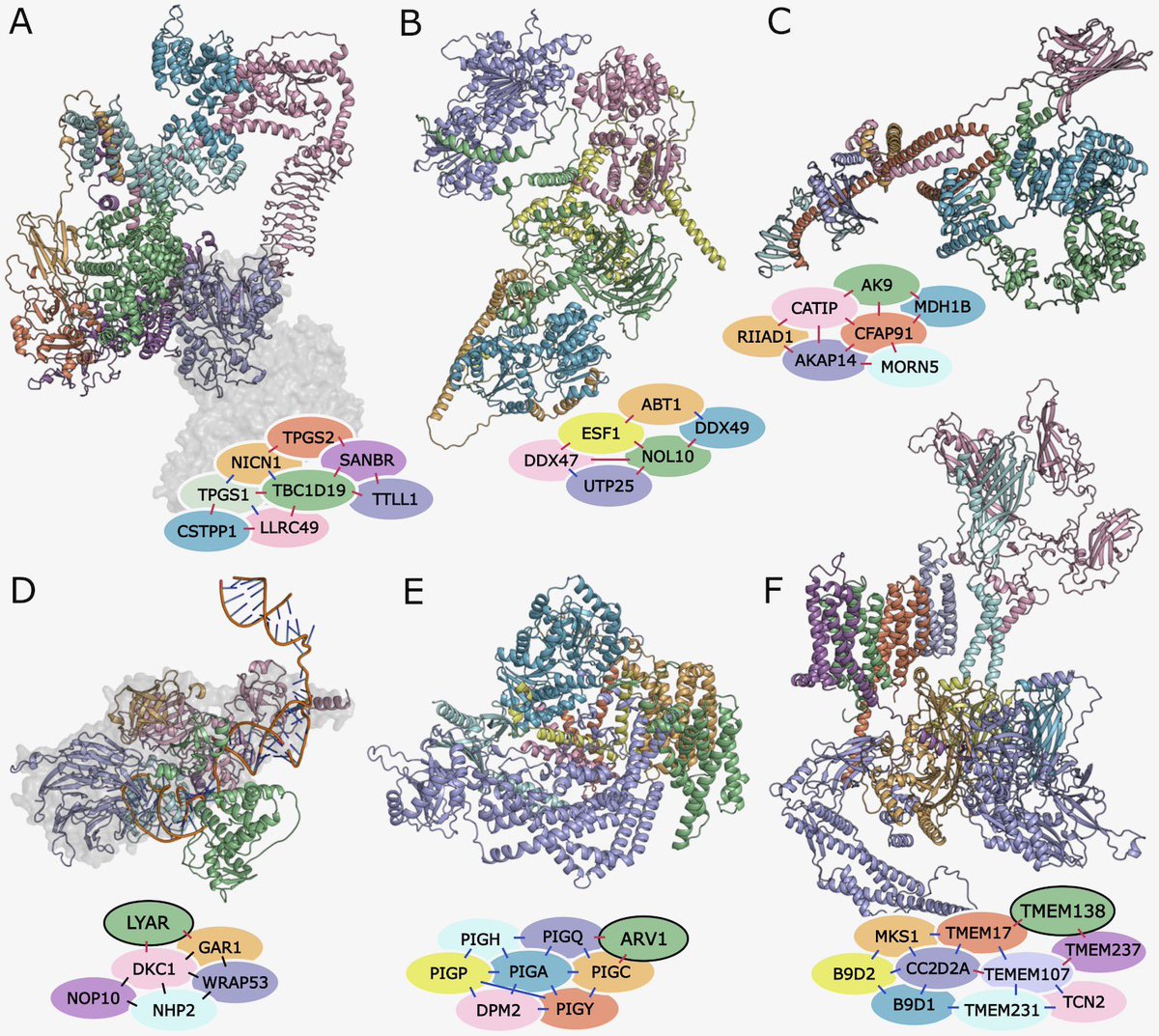
We find predicted interactions which can be linked to GPCRs, cancers, and other genetic diseases. We map SNP data into the interfaces, and assemble higher order oligomers to explore some of these systems, but there’s much more to look at on our website: https://t.co/QFIS4lS9BM
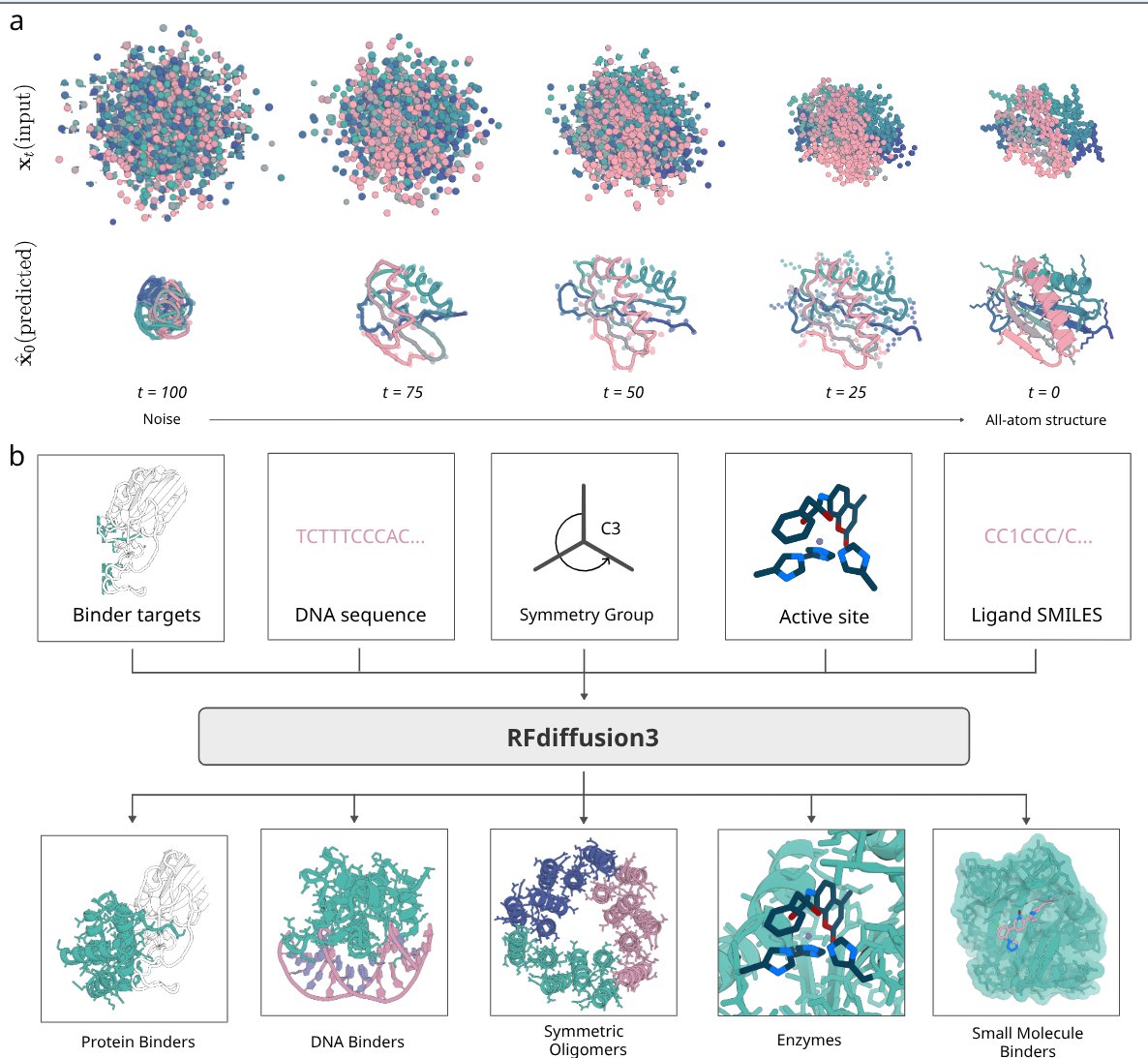
We asked ourselves what could we do if we worked cooperatively as a team to create a single model that could design any biomolecular interactions.
Yesterday, we reported details of RFdiffusion3, the next step towards building functional proteins straight from the computer.
We built RF3 with @nvidia’s latest cuEquivariance accelerations, letting us iterate fast.
Now we’re sharing the full stack: ModelForge — open-source infra for training biomolecular AI.
Start your project here 👉 https://t.co/aFJOkxhJ9a
Excited to share work with @ZhidianZ, Milot Mirdita, Martin Steinegger, and @sokrypton
https://t.co/pkWeguhQ4l
TLDR: We introduce MSA Pairformer, a 111M parameter protein language model that challenges the scaling paradigm in self-supervised protein language modeling
🧵
The #AlphaFold 3 model code and weights are now available for academic use. We @GoogleDeepMind are excited to see how the research community continues to use AlphaFold to address open questions in biology and new lines of research.
https://t.co/kVB9hWJZTI
With David and the Baker Lab in the spotlight today, I wanted to share some insights into the @UWproteindesign and how it operates, a glimpse behind the curtain. I had planned to write this post-graduation, but now seems as good a time as any. (Got twitter blue free trial so this could all fit in less tweets!)
First, the lab is enormous. ~60 grad students, ~60 postdocs, a handful of visitors, undergrads, and a surrounding institution of another 150 or so. Collaboration is strongly encouraged (even mandated) by David, who sets up pro-collaboration incentives. Notably, he's fine with grad students graduating without a sole first-author paper—it's acceptable to "only" have worked as a co-first author. This is a key ingredient in the secret sauce: the tight collaboration between wet lab and dry lab. It ensures that all our work is ultimately grounded in strong wet-lab validation—our "oracle" is the real world, not another computational model.
While we have regular meetings for different subgroups and the entire group, much information travels through the lab via informal one-on-one interactions. In some ways, it reminds me of a classic "tribe of humans in the state of nature"—100-200 people with no clear hierarchy, passing information via "gossip". It’s maybe not the most complete way of ensuring everyone is on the same page, but saves time as we aren’t drowning in endless meetings.
Does David stay in touch with all these grad students and post-docs? Remarkably, yes. Unlike some very large labs known for being run entirely by post-docs, he knows exactly what everyone is working on and the stage of their projects. Each member has monthly one-on-ones with him, and monthly subgroup meetings that David attends. If he suggests you try something at your previous one-on-one, you'd better have it done by the next.
Does he actually contribute research ideas, or is he more of a detached big-picture project manager? Definitely the former. He understands the intricacies of a shocking range of topics. I'll be discussing some arcane deep learning concept with him, and then he'll turn around and talk to someone about the details of a catalytic mechanism. He's actually the most hands-on PI I've ever had—if anything, he verges on over-managing rather than being too detached.
How does he keep track of everything? Partly, he's just a brilliant person with exceptional recall. But he has also built infrastructure above and below him in the lab to handle many of the details, bureaucracy, big picture, and management tasks. This allows him to spend most of his day doing what he's most passionate about and skilled at: walking around talking to people about science. He also lives very much in the moment and in his own words, “never thinks very far ahead". To keep up with tools, methods, and wet lab techniques, he does the occasional project and design campaign himself on the side when time allows.
It's still a tremendous cognitive load to keep all this in his head, but as much as possible, he has offloaded non-scientific cognitive burdens. It helps that he’s in the lab in person most days of the year, rarely traveling for conferences or talks, instead doing them over Zoom or not attending. (1/2).
BREAKING NEWS
The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Chemistry with one half to David Baker “for computational protein design” and the other half jointly to Demis Hassabis and John M. Jumper “for protein structure prediction.”
@AndreyFeklistov Hi Andrey, the PDBs should be available. If you go to a specific pair there’s a download button on the side for example:
https://t.co/G3YplKtmUO
Otherwise you can bulk download the full dataset here: https://t.co/QXThXbmqKj (https://t.co/3g8cUPEoOQ)
Here’s our human protein-protein interactome. We mined the SRA, devised a new distillation dataset for protein complexes, trained a new version of RF2 to screen millions of protein pairs, and identify > 18k binary interactions. https://t.co/rfEOJIlW1x