@fabiolauria92@rediffbusiness Africa’s AI gap isn’t just about training,it’s about application.
At JNS Cloud Solutions, we follow a Skill , Shape , Scale model:
Skill: Hands-on, role-based AI learning
Shape: Apply through real SME use cases & sandbox environments
Scale: Deploy & expand across the business#AI
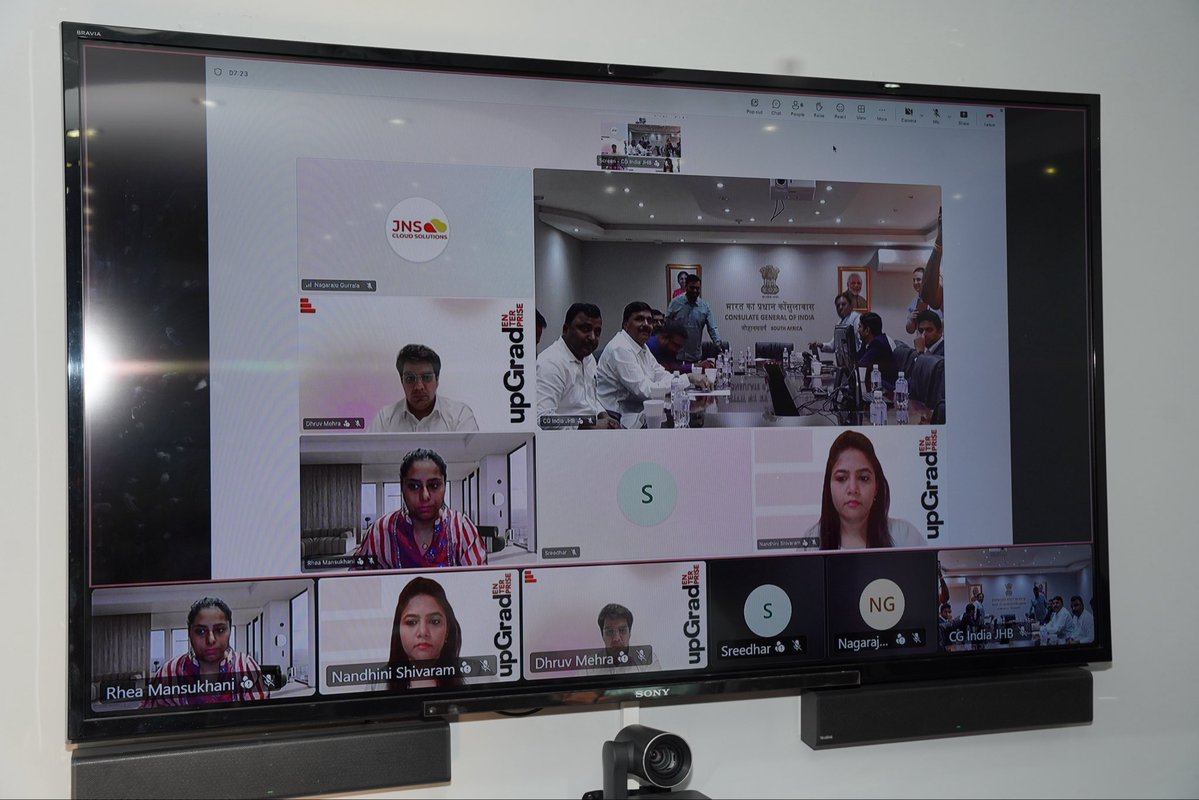
We are proud to mark the soft launch of the Africa AI Skilling Initiative and the signing of our MoU with upGrad Enterprise.
This milestone reflects our shared commitment to building a future-ready workforce across Africa Thank you @indiainjoburg@IBF_SA@upGrad_edu
Proud to have soft launched the Africa AI Skilling Initiative with the support @indiainjoburg and @IBF_SA, in partnership with @upGrad_edu
we are committed to empowering Africa with future-ready AI skills and driving inclusive digital growth. #AfricaTech@nagarajujns
IBF with CGI supported the soft launch of the Africa AI Skilling Initiative by JNS Cloud Solutions in partnership with upGrad Enterprise. This initiative builds on the momentum of the recent AI Summit, further strengthening collaboration on future-ready skills across Africa.
With the coming tsunami of demand for tokens, there are significant opportunities to orchestrate the underlying memory+compute *just right* for LLMs.
The fundamental and non-obvious constraint is that due to the chip fabrication process, you get two completely distinct pools of memory (of different physical implementations too): 1) on-chip SRAM that is immediately next to the compute units that is incredibly fast but of very of low capacity, and 2) off-chip DRAM which has extremely high capacity, but the contents of which you can only suck through a long straw. On top of this, there are many details of the architecture (e.g. systolic arrays), numerics, etc.
The design of the optimal physical substrate and then the orchestration of memory+compute across the top volume workflows of LLMs (inference prefill/decode, training/finetuning, etc.) with the best throughput/latency/$ is probably today's most interesting intellectual puzzle with the highest rewards (\cite 4.6T of NVDA). All of it to get many tokens, fast and cheap. Arguably, the workflow that may matter the most (inference decode *and* over long token contexts in tight agentic loops) is the one hardest to achieve simultaneously by the ~both camps of what exists today (HBM-first NVIDIA adjacent and SRAM-first Cerebras adjacent). Anyway the MatX team is A++ grade so it's my pleasure to have a small involvement and congratulations on the raise!