Excited to share XGrammar-2 has been accepted by #ACMCAIS 2026 @CAISconf! 🎉
⚡️ Up to 80x speedup
🛡️ Strict tool-calling correctness
🚀 Trusted by xAI in production systems
Join our presentation today at 4 PM at Bayshore Ballroom to see how we power critical agent workloads at scale.
🔗Blog: https://t.co/N0Tbl58Grf
🔗GitHub: https://t.co/lo4yScvfRN
Had a blast presenting Event Tensor at MLSys2026! 🚀
TL;DR: We make writing dynamic megakernels simple. ⚡
Thanks to my advisors & collaborators. Here’s pic from yesterday’s poster session 👇 Let’s chat! 🔗 https://t.co/jVqGkrnBMj
Today’s #MLSys2026 keynote featured @LukeZettlemoyer on rethinking the data and architecture behind pretraining: an exciting look at how the foundations of modern AI are evolving. Thrilled to see 1,100+ attendees joining MLSys this year!
🚀Introducing Motus Tracing: open-source observability for AI agents.
Without traces, an agent is a black box that burns tokens. Yet most agent observability and tracing stacks today live behind accounts and subscription tiers.
Motus Tracing is fully open source. Capture every model call, tool call, sandbox interaction, sub-agent action, retry, and error, for any agent framework.
One unified interface from development to production. Same spans for debugging, evals, and Learning Agents.
Blog: https://t.co/rXq3VkSvMm
Code: https://t.co/C4u6JUzige
@lithos_ai
🚀 Introducing Learning Agents in Motus Cloud.
Instead of manually tuning prompts, tools, models, and reasoning flows, Motus continuously optimizes deployed agents from real production traffic by building eval sets, proposing better versions, and surfacing the Pareto frontier across quality and cost.
Public preview, tokens on us👇
https://t.co/XDqomIiDr1
@lithos_ai
Excited to share that LessIsMore has been accepted to ICML 2026! 🚀
LessIsMore is a training-free sparse attention for efficient long-horizon reasoning. By enforcing cross-head unified token selection, it brings up to 1.6x E2E speedup while preserving reasoning accuracy under practical workloads.
Huge thanks to my amazing co-authors and mentors @Jackfram2, @JiaZhihao, Ravi!
Paper: https://t.co/AV1GbTxo2y
Code: https://t.co/5e4QC2A6S2
#ICML2026 #LLM #EfficientAI
Congrats to @LijieyYang and the team! 🚀 Excited to see LessIsMore at #ICML2026 — a simple, training-free sparse attention approach for faster long-horizon reasoning.
🚀Introducing Motus, the open-source agent infrastructure that learns in production.
Existing agent infra serves static agents: the harness, model, and workflow are fixed after deployment. But static agents degrade over time. The harness goes stale, new models go unincorporated, context drifts, and latency compounds.
Motus closes this gap by learning from every trace (failures, latency, cost, and task outcomes) and using those signals to continuously optimize agent harness, model orchestration, context memory, and end-to-end latency.
Early results: higher accuracy than any single frontier model at 2.3× lower cost (Terminal-Bench 2.0, SWE-bench Verified), with 52% lower latency and 45% better memory recall.
Open source under Apache 2.0. Works with any agent SDK. Deploy with one command.
https://t.co/C4u6JUzige
https://t.co/QIfKIikZQb
Excited to see our inaugural CMU Catalyst Research Summit bring together 120+ attendees!
A full day of discussions on the future of agentic AI systems, multi-modal AI, and ML compilation—with amazing energy from both academia and industry.
Co-organized with @tqchenml@BeidiChen@Tim_Dettmers — this is just the beginning 🚀
🌟 FlashInfer-Bench accepted to MLSys 2026!
FlashInfer-Bench is also the platform for MLSys 2026 AI Kernel Challenge. Tomorrow is the last registration day! If you're into agents and CUDA kernels, be sure to join! 👉 https://t.co/NfsM0Xrvh1
So proud of the team for this milestone. Over the past two months, we've witnessed rapid progress in AI Agents for GPU optimization. We have been upgrading our benchmark system and dataset to keep up this pace: better model coverage, stronger safety guardrails.
Check out our OSS project: 🔗 https://t.co/rlzNUXISfG
See you on the leaderboard, and see you at MLSys! 👋
🚀 MLSys 2026 Contest - @nvidia Track is LIVE!
Registration is now open for the FlashInfer-Bench Challenge! Submit high-performance GPU kernels for cutting-edge LLM architectures on NVIDIA Blackwell GPUs.
Three Tracks
* MoE (Mixture of Experts)
* DSA (Deepseek Sparse Attention)
* GDN (Gated Delta Net)
Human experts AND AI agents welcome — evaluated separately. Let's see who builds the best kernels! 🤖
🎁 Prizes: Winners take home NVIDIA GPUs and are invited for presentation at MLSys 2026.
⚡ First 50 teams to register get free GPU credits from @modal - huge thanks for the sponsorship @charles_irl !
Whether you're a kernel wizard or building autonomous coding agents, we want to see what you've got.
🔗 Contest details: https://t.co/0ILK1D4Z9o
See you at MLSys 2026! 🔥
#MLSys2026 is inviting self-nominations for the External Review Committee (ERC)!
If you want to contribute to the review process for the MLSys conference, nominate yourself and help shape this year's program. We especially welcome PhD students and early-career researchers!
https://t.co/IPzuKOdbad
⏰3 days left to submit to #MLSys2026 (deadline October 30)!
Submit your best ML systems work to the Research and Industrial Tracks, and join the MLSys community in Seattle next May.
👉https://t.co/z0va9DDnJE
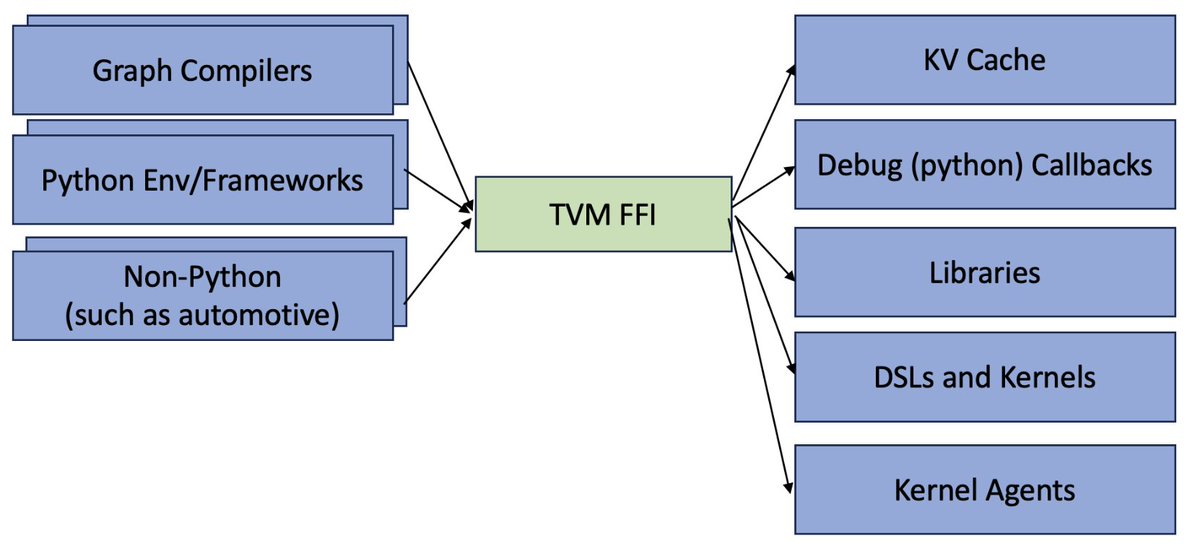
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust https://t.co/m2gHJRreol
🤔 Can AI optimize the systems it runs on?
🚀 Introducing FlashInfer-Bench, a workflow that makes AI systems self-improving with agents:
- Standardized signature for LLM serving kernels
- Implement kernels with your preferred language
- Benchmark them against real-world serving workloads
- Fastest kernels get day-0 integrated into production
First-class integration with FlashInfer, SGLang (@lmsysorg ), and vLLM (@vllm_project ) at launch🙌
Blog post: https://t.co/RG3oMO9brO
Leaderboard: https://t.co/R9T4jJJNd0
The #MLSys2026 submission deadline is only 2 weeks away (Oct 30)! Submit your best work on ML systems — spanning hardware, compilers, software, models, agents, and eval. This year features both Research and Industry Tracks! Join us in Seattle next spring! https://t.co/trj383wuVB
🚀Excited to share the #MLSys Call for Papers!
For the first time, we’re also welcoming submissions to the Industrial Track.
Research and industrial track deadline: Oct 30, 2025
Reviews available: Jan 12, 2026
Author responses: Jan 16, 2026
Notifications: Jan 25, 2026
https://t.co/yArzEAwQDc
https://t.co/o3hikWB14o
Kudos to @LijieyYang and the team for the exciting new sparse attention work! LessIsMore is an elegant and effective solution for reasoning tasks. And there is still a lot more we can do on top of this, so stay tuned!
[1/N] 🚀 Excited to introduce my first work at @Princeton:
LessIsMore – a training-free sparse attention method tailored for efficient reasoning in LRMs, achieving lossless accuracy with high sparsity up to 87.5% and 1.1x avg decoding speedup compared to Full Attention on reasoning tasks like AIME-24. (More details in 🧵)
💻 Code: https://t.co/5e4QC2A6S2
📄 arXiv: https://t.co/yXyTqRjPe0
🔍 HF Daily Paper: https://t.co/yXyTqRjPe0




















![LijieyYang's tweet photo. [1/N] 🚀 Excited to introduce my first work at @Princeton:
LessIsMore – a training-free sparse attention method tailored for efficient reasoning in LRMs, achieving lossless accuracy with high sparsity up to 87.5% and 1.1x avg decoding speedup compared to Full Attention on reasoning tasks like AIME-24. (More details in 🧵)
💻 Code: https://t.co/5e4QC2A6S2
📄 arXiv: https://t.co/yXyTqRjPe0
🔍 HF Daily Paper: https://t.co/yXyTqRjPe0](https://pbs.twimg.com/media/GyIKgWnXEAAjdrM.jpg)





























