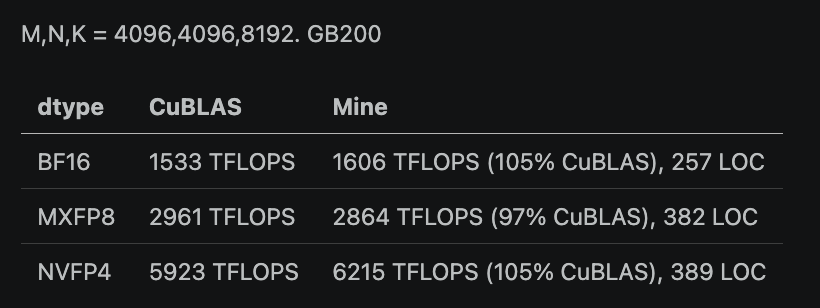
Beating CuBLAS was not a goal, but it came out pretty good. I think this is more useful as a concise and hackable "template", rather than being the fastest kernel: bring ur own epilogues, roll a megakernel, ask Codex to fork it. Just like when I first learned Triton.
Two moments every ML researcher knows. You get onto a new cluster, and week one goes to fitting the framework to your setup, not training. A new architecture lands, and trying it means hacking through a gigantic codebase to stay compatible with the pipeline. What you want to change is small. The code you wade through to change isn't.
This experience is likely not alone, and many researchers we’ve talked to run into similar issues. A year of this on CMU's FLAME cluster left us with one question: what if a framework were built for an agent to adapt and evolve, not just for humans to maintain?
So we introduce PithTrain: a compact, agent-native MoE training system, now ~11K lines of Python, on four principles:
- Compact: fits in one context window
- Python-native: readable tracebacks, no compiled-extension rebuilds
- No implicit indirection: direct calls, each model in its own file
- Agent skills: in-repo playbooks for recurring tasks
Then we measured the thing nobody measures. Same agent, same tasks, only the framework underneath changes: on PithTrain it finishes with up to 62% fewer turns and 64% less GPU time than production frameworks, while training just as fast.
We call this second axis agent-task efficiency, and we believe it deserves to sit alongside training throughput as a metric worth optimizing. Excited to see what people build with it.
Built with amazing collaborators @haok1402, Haozhan Tang, Akaash Parthasarathy, @Zichun_Yu, @junrushao, Todd Mowry, @XiongChenyan and @tqchenml.
Blog: https://t.co/byOKPs9rGQ
Code: https://t.co/AH5ZbwYluV
Paper: https://t.co/hkmDGx9Hc6
Flash-KMeans was only the beginning.
Today, from the Flash-KMeans team, we are releasing FlashLib — a GPU library for fast, predictable, agent-ready classical ML operators.
Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML).
Blog: https://t.co/P31SGl0cyT
Code: https://t.co/9nkO2hmeOl
For me, the coolest finding is that Muon optimizer is crucial for Parallax to move beyond Softmax Attention.
Lesson — don't evaluate new architectures solely under AdamW, you'll miss the good ones.
paper: https://t.co/yAqClXrJUz
code: https://t.co/D4pgIr1wM7
For the origin of Parallax, check out the LLA paper at ICLR 2026:
paper: https://t.co/85OzoOQlnF
code: https://t.co/eqMYZ0U6qO
Build your first game with Gemini 3.5 Flash.
Translate everyday objects directly into interactive, digital experiences without complex 3D modeling. Start with a Nano Banana prompt, turn your image into a game in Canvas, and refine your vision for optimal gameplay.
Excited about this new work
As KV compaction becomes increasingly important, we ask whether it’s worth adapting the model itself to perform better under compaction
Turns out, it can really matter
After some mathematical rewrite, turns out all of transformer is a series of gemm + epilogue. Given a few optimized primitives, LLMs (and novice humans) can write speed-of-light kernels for all transformer ops!
rolling up to MLSys '26 to meet with @ye_combinator and the winners of our B200 kernel perf competition
quick trip, so i packed a single bag, just my essentials
Pro-tip: using CUDA graphs and annoyed that all the kernels have no labels in your profiles? Get a nightly that has mark_kernels context manager: https://t.co/IF3sZhb4S2 (thanks Natalia and Shangdi for implementing!) You need 13.1 driver, but user mode driver is enough
It was an honor to give the keynote at MLSys
Covered how AI systems have evolved, why AI is needed to improve them, why results have disappointed, why the future looks amazing, and why I’m working on this at Core Auto
Recording should be out soon, in the meantime slides
Historically, we used https://t.co/uMrrnBoSPF for this. I think this forum is still good for things that are much more about discussion. But actual one big impetus for devlogs as a SSG website https://t.co/wDTjRlq1jK was to make the posts more easily accessible to LLM agents