@yoavgo@TacoCohen Then sample a bunch of latents and marginalize over them via the Bayes estimator for a given risk. LLM evals use 0-1 risk, in which case the Bayes estimator is the posterior mode. This is exactly the self-consistency=majority@N strategy
Excited to share that Learnability-Informed Fine-Tuning of Diffusion Language Models (LIFT) has been accepted at ICML 2026! 🎉
paper: https://t.co/R0Hhi0NYoh
code: https://t.co/TUsMWRnm5T
@hi_tysam So you reduce exposure bias by adding random noise to model inputs. I wonder what would happen if noise more closely followed inference-time noise, eg by replacing input tokens with tokens sampled from model by forwarding model once before each train step
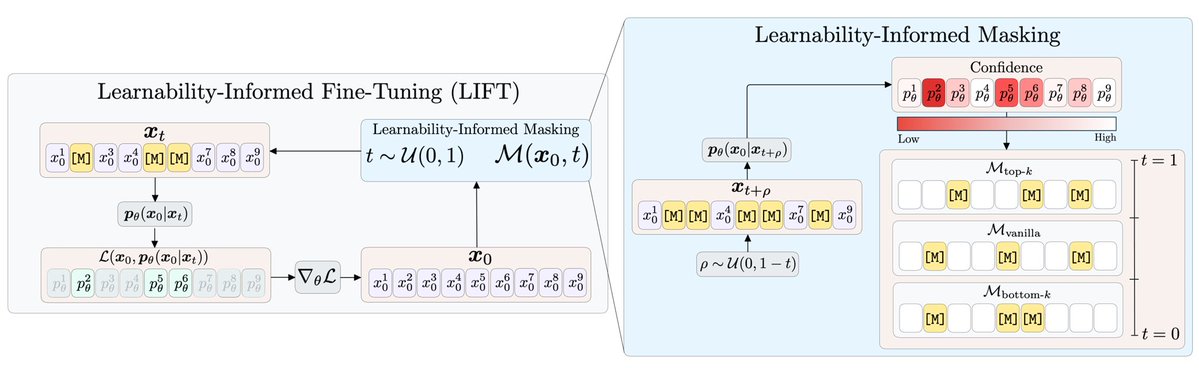
LIFT is the SFT recipe for dLLMs that actually understands the masking dynamics. Vanilla SFT on dLLMs often HURTS performance, and they finally pin down why.
Their analysis: vanilla SFT overlooks learnability. Rare tokens are difficult to learn when most of the input is masked because the model has nothing to ground them in. Common tokens are easy and of little value to learn when most of the input is unmasked because the answer is essentially already given.
LIFT aligns training with the information available at different diffusion time steps. Learn easy tokens when most of the input is masked (build up basic vocabulary at the noisy end), and learn hard tokens when more context is available (let the model use that context). The schedule matches the difficulty of each token to the moment the model is best positioned to absorb it.
Learnability-Informed Fine-Tuning of Diffusion Language Models
Paper: https://t.co/zUodVpjVgb
Code: https://t.co/gLW9OrR4bO
@kalomaze This paper https://t.co/Npqw53q4Sx guarantees parallel joint distribution sampling using spec decode-style verification/rejection. The idea (fig 9) is: in the same forward pass, decode multiple tokens AND vfy tokens from last fwd. Diffusion is in the title, but closer to MTP IMO
@novasarc01@teortaxesTex Yeah, multi-teacher OPD is super cool and was also used by GLM-5 and MiMo-V2-Flash. Remarkably, some insanely-cracked dev already shipped MOPD in VeRL: https://t.co/3Sot3Z7RDo
@tak3sh8 ODEs are continuous in time, and ResNets correspond to forward-Euler discretizations of the dynamics
w.r.t. @karpathy’s comment, SGD is the forward-Euler discretization of the gradient-flow ODE
@sasuke___420 As mentioned by another commenter, torch has sparse Adam, but nccl doesn't support sparse collectives, so I think it will only work with gloo backend. torchrec/fbgemm have some nice sparse optimizers, although they probably won't work with deepspeed/FSDP/Megatron
@kalomaze@sasuke___420 Is it possible that people have reached the conclusion that WD on embeddings is bad due to the gradient sparsity issue? (ie, by applying WD on token embeddings that don't appear in the current batch)
(7/7) The two supersonic flow datasets we generated for evaluating ShockCast are available on HuggingFace: https://t.co/saZdK60wZd
Paper: https://t.co/zOqH9urQjD
Code: https://t.co/n1puP80rru
(6/n) We explore several physical priors to better align the neural CFL model with the classical CFL condition. We also introduce timestep conditioning strategies inspired by neural ODE and Mixture of Experts.