🚀 Today, we’re excited to introduce SimpleTES for scaling the scientific discovery loop.
🧵 I always ask myself: what are we actually scaling in scientific discovery?
Most LLM discovery methods focus on test-time scaling generation — more tokens, more agents, more turns.
But science advances through the evaluation-driven loops: propose → evaluate → refine → repeat.
SimleTES captures this idea, discovering SOTA solutions across 21 scientific problems!
Key discoveries:
🏎️ 2.17x faster lasso solver than glmnet — the gold-standard LASSO solver, engineered for decades.
⚛️ 24.5% fewer quantum routing overhead on IBM Q20 — superior than previous standard library LightSABRE.
📐 0.380868 on Erdős Minimum Overlap — outperforming previous solutions from mixed-frontier ensembles or humans.
🧬 0.74 on Tabula Muris (scRNA-seq denoising) — new SOTA, generalizing to unseen tissue types without retraining.
#LLM #AI4Science #ScalingLaws #SimpleTES #MachineLearning
In AI for scientific discovery, the bottleneck isn't always generation — it's quite often evaluation. How do you design evaluators close to gold? Prevent reward hacking? And critically, how do you scale the evaluation-driven loop to reach genuinely novel discoveries?
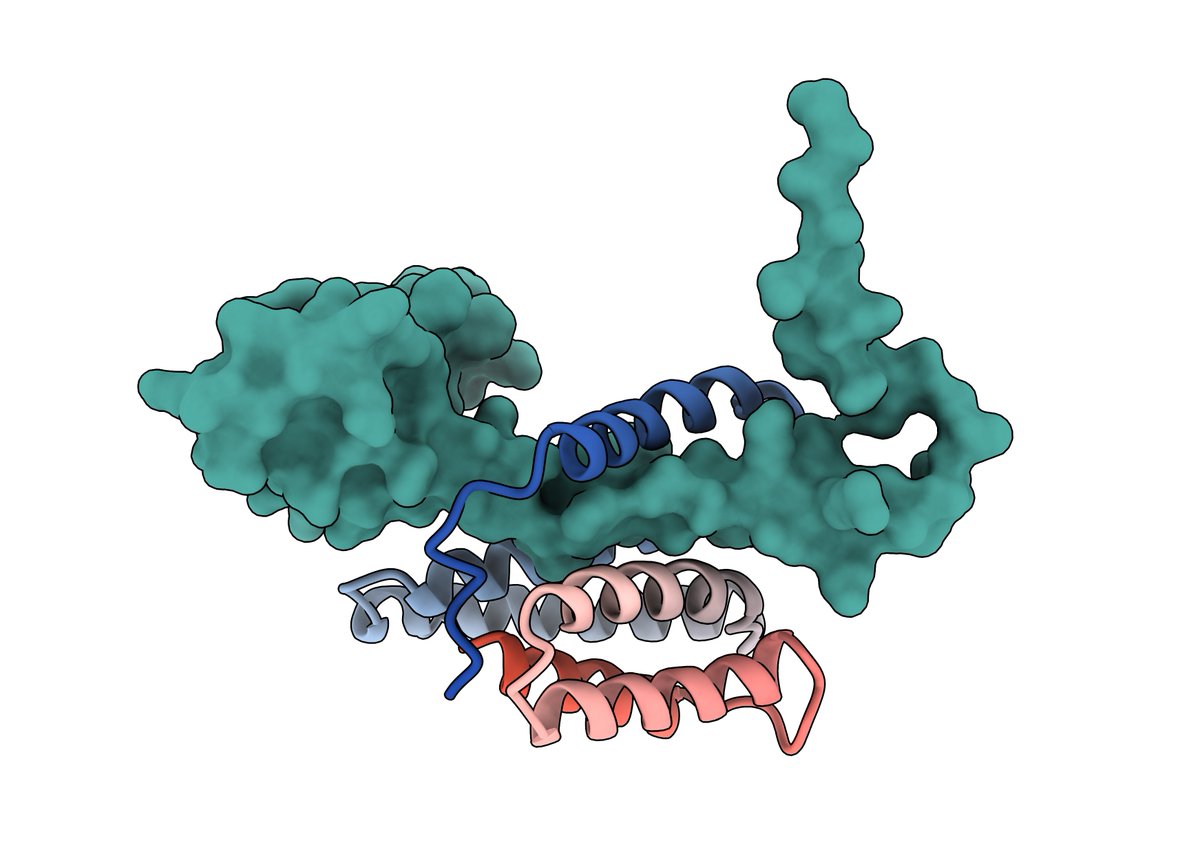
Extremely excited about the results of @adaptyvbio RBX1 binder design competition! 𝑩𝒊𝒏𝒅𝑪𝒓𝒂𝒇𝒕2 performed very well, with 3 out of 7 designs binding to the disordered tail. Overall, only 9 binders worked out of 322 tested, 2.8% hit rate! Proud of the BC2 team ♥️
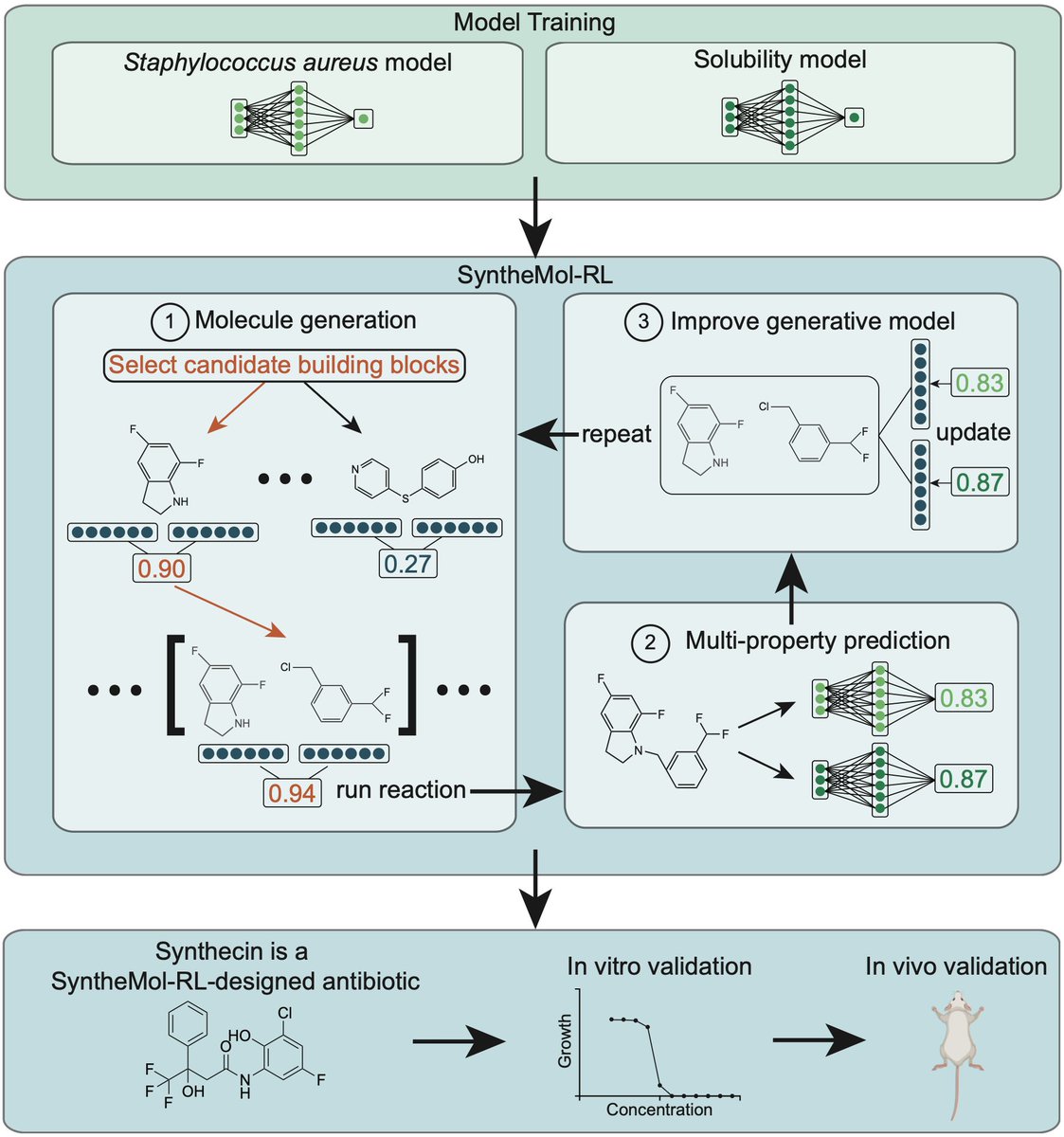
SyntheMol-RL has now been published! SyntheMol-RL is a reinforcement learning model for synthesizable small molecule drug design. We used it to design antibiotic candidates for the bacteria S. aureus with hits validated in vitro and in vivo in mice. 1/6 https://t.co/SuCMHik2tB
Finally getting to share one of my favorite projects. ICLR Oral! 🏆
It’s so strange how rigid video tokenization is. Think about it: why should a still landscape cost the same amount of tokens as a busy street?
We built InfoTok. We went back to basics with Shannon’s information theory to make tokens "adaptive" in a principled way. Its 2.3x better compression and 11x faster inference demonstrates the magic of the old-school theory ✨
Check it out: https://t.co/0PeYtaVY1y
Excited to share that our paper has been published in Nature Machine Intelligence! We conducted a randomized controlled trial at ICLR 2025 with 20,000+ reviews to test whether LLM feedback improves peer review quality.
Link: https://t.co/ioXpqRJEyN
@arpitrage Doesn't upzoning square the circle? Allowing 4 units on a SFH lot means each individual unit is cheaper for new buyers/renters, but the plot as a whole has higher value for the seller?
@DdelAlamo I have a pet theory that a GAN-style discriminator auxiliary head for post-training a diffusion model could be helpful, given some of the differences between generated and natural proteins (see the distances on page 5 https://t.co/Pxx4jEvnDd) but haven't tested this yet
To make a long story short, we uncover dozens of regions of our genome that control whether the virus persists or is cleared quickly. Further, we show that persistent EBV may serve as a biomarker of complex diseases-- from respiratory disease to autoimmunity.
@CalebLareau@MSKCancerCenter Congrats on the awesome work! This is a fascinating read.
I see you found associations with RA and SLE. Just curious, did you look for an association with Celiac as well?
@NielsRogge@ericzakariasson Do you notice a pattern of when this happens? My proposal is after every compacting it should re-read its https://t.co/dVBqPIbO6j where I tell it what env to use, or something like that. I find it will randomly forget env name later into long conversations
@bcherny Does Claude Code re-read it's https://t.co/KhvfvudzZH (or some equivalent) after compacting? I find it might forget some odd things during a long convo (e.g., what conda env it should be using)
🤔Want a principled way to RL your diffusion model?
Check Data-regularized Reinforcement Learning (DDRL)! Post-train @nvidia#Cosmos World Foundation models with a million GPU hours! 🤯
Novel formulation ➡️ Theoretically integrates SFT into RL ➡️ Robust to Reward Hacking 🛑
Details: https://t.co/1A9q8ho2xb
#DDRL #Diffusion #RL #NVIDIA #Cosmos
@sedielem Another fun tweak here is intentionally biasing the training distribution, e.g., SolubleMPNN only trained on soluble proteins, so that "natural" structures passed through the model intentionally come out more soluble than the original input