After multiple attempts to get different AI models to help me with my taxes, I was forced to give up and use a simple spreadsheet. AI couldn’t do simple math and kept inventing numbers or ignoring instructions. It was like hiring the world’s worst accountant.
Tried to use AI to convert my USD stock trades to CAD for the purpose of doing my taxes. Claude demanded money, Gemini hallucinated its own numbers and Grok just froze. Guess it's back to doing math the old fashioned way.
When I was taking a JR train in Osaka last month, I kept wondering: Wouldn't it be nice if Toronto had something similar? A post on the history, struggles and hope Japan can bring to the development of regional rail in Toronto. Filled with video of JR-W trains too. Next post...
I am no longer employed by CityNews. I am proud of my journalism at CityNews and I stand by my reporting. I will have more to say on this later but for now please stay tuned and thank you for those who have supported me.
This is absolutely infuriating. Yazdani has been doing amazing work covering education in this province, and holding the minister to account.
@CityNewsTO this is absurd and demands explanation.
FastTrackTO is launching and releasing our 10 point plan to fix the Toronto Streetcar network. A symbol of the city that could be great with achievable, common sense and low cost changes. The plan if implemented would transform the city.
https://t.co/9RpJtWQwtM
(1/2)
@EricONCA@RM_Transit To your point a boy was killed by a GO train today, so yeah, accidents do happen. I wonder though if trains were more frequent if people would actually learn to take train crossings more seriously. https://t.co/dbEu7FscXv
Back in September 2024, @nathanbenaich and I wrote about this nonsense purveyor: https://t.co/3K9NWhQL9w
Disappointing to see so many people taking this seriously.
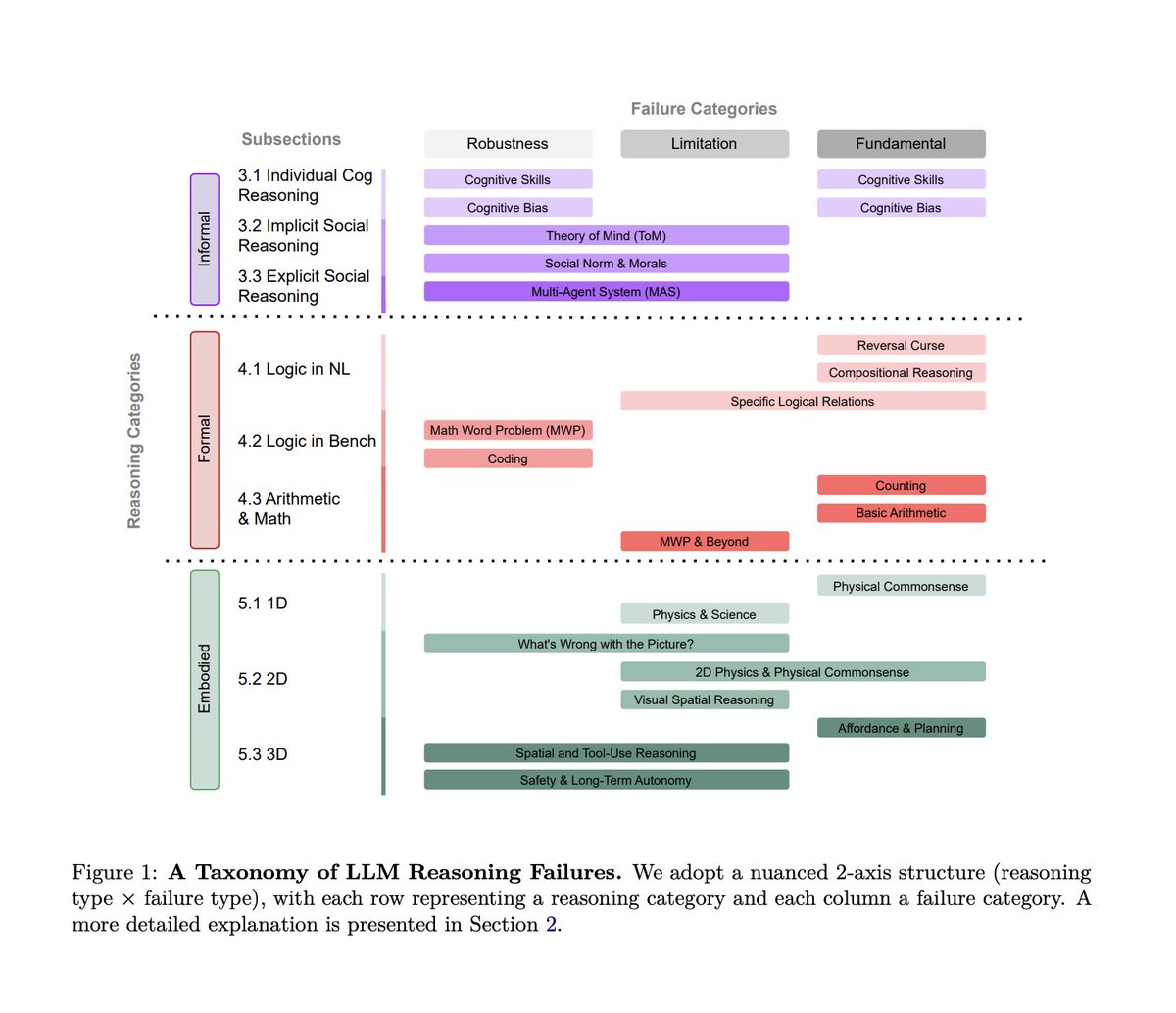
🚨 Holy shit… Stanford just published the most uncomfortable paper on LLM reasoning I’ve read in a long time.
This isn’t a flashy new model or a leaderboard win. It’s a systematic teardown of how and why large language models keep failing at reasoning even when benchmarks say they’re doing great.
The paper does one very smart thing upfront: it introduces a clean taxonomy instead of more anecdotes. The authors split reasoning into non-embodied and embodied.
Non-embodied reasoning is what most benchmarks test and it’s further divided into informal reasoning (intuition, social judgment, commonsense heuristics) and formal reasoning (logic, math, code, symbolic manipulation).
Embodied reasoning is where models must reason about the physical world, space, causality, and action under real constraints.
Across all three, the same failure patterns keep showing up.
> First are fundamental failures baked into current architectures. Models generate answers that look coherent but collapse under light logical pressure. They shortcut, pattern-match, or hallucinate steps instead of executing a consistent reasoning process.
> Second are application-specific failures. A model that looks strong on math benchmarks can quietly fall apart in scientific reasoning, planning, or multi-step decision making. Performance does not transfer nearly as well as leaderboards imply.
> Third are robustness failures. Tiny changes in wording, ordering, or context can flip an answer entirely. The reasoning wasn’t stable to begin with; it just happened to work for that phrasing.
One of the most disturbing findings is how often models produce unfaithful reasoning. They give the correct final answer while providing explanations that are logically wrong, incomplete, or fabricated.
This is worse than being wrong, because it trains users to trust explanations that don’t correspond to the actual decision process.
Embodied reasoning is where things really fall apart. LLMs systematically fail at physical commonsense, spatial reasoning, and basic physics because they have no grounded experience.
Even in text-only settings, as soon as a task implicitly depends on real-world dynamics, failures become predictable and repeatable.
The authors don’t just criticize. They outline mitigation paths: inference-time scaling, analogical memory, external verification, and evaluations that deliberately inject known failure cases instead of optimizing for leaderboard performance.
But they’re very clear that none of these are silver bullets yet.
The takeaway isn’t that LLMs can’t reason.
It’s more uncomfortable than that.
LLMs reason just enough to sound convincing, but not enough to be reliable.
And unless we start measuring how models fail not just how often they succeed we’ll keep deploying systems that pass benchmarks, fail silently in production, and explain themselves with total confidence while doing the wrong thing.
That’s the real warning shot in this paper.
Paper: Large Language Model Reasoning Failures
I always loved watching old SCTV reruns for Catherine O'Hara (but my favourite parts were when they just got totally absurd) So this little excerpt from Monster Chiller Horror Theatre: Whispers of The Wolf - was one of my fave, just out there performances. She was one of a kind.