We’re hiring in Bonn! 📢
The University of Bonn seeks applications for a W2 Professorship in Mathematics in Medical Sciences.
📅 Deadline: July 5, 2026
https://t.co/ud9XdIrOmH
We’re hiring a Junior Group Leader - AI in immunotherapy - to join our team at the earliest possible date. The position is embedded within my Chair and the Chair of Cellular Immunotherapy (Michael Hudecek), and connected to CAIDAS center for AI.
https://t.co/ddYiddvUi8
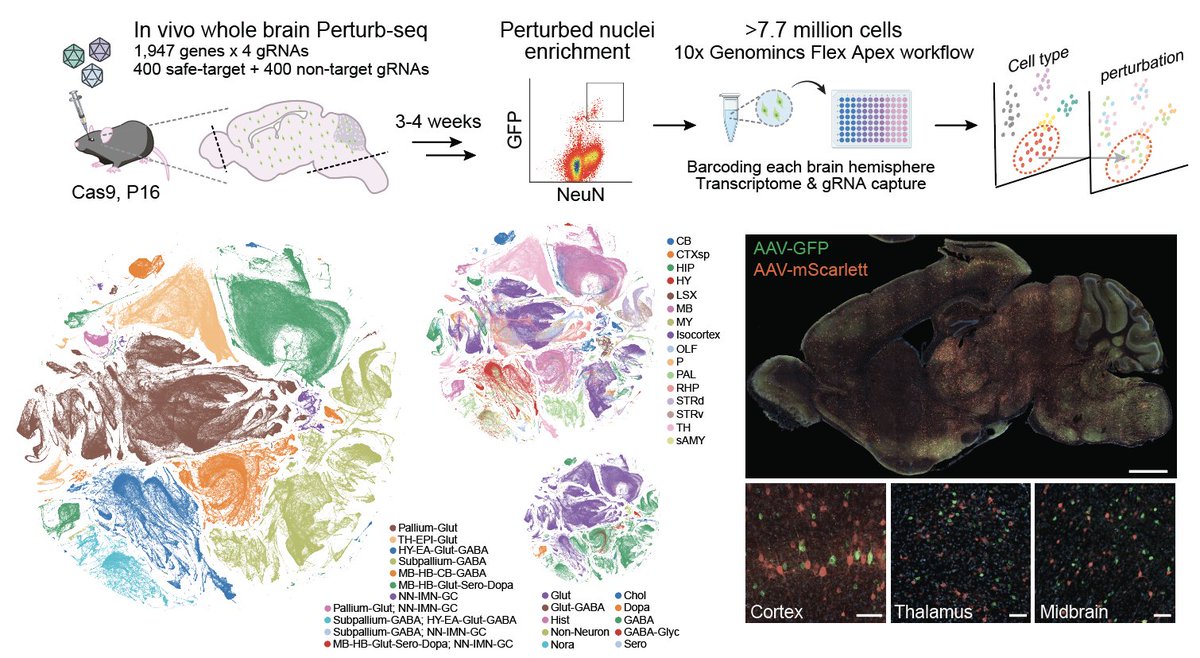
📢 Preprint: we present a whole-mouse-brain in vivo Perturb-seq atlas, 7.7 million cells, 1947 disease-associated perturbations, moving toward direct readout of how human genetics rewires cell states & circuits in vivo. Grateful for the Team! @NVIDIAHealth https://t.co/01c1KFuLFw
Download our extended database of postdoc fellowships.
276 funding opportunities. For each entry, we provide eligibility/requirements, amount, deadline, link, description, etc.
Download our database here: https://t.co/EbTahdzbkp
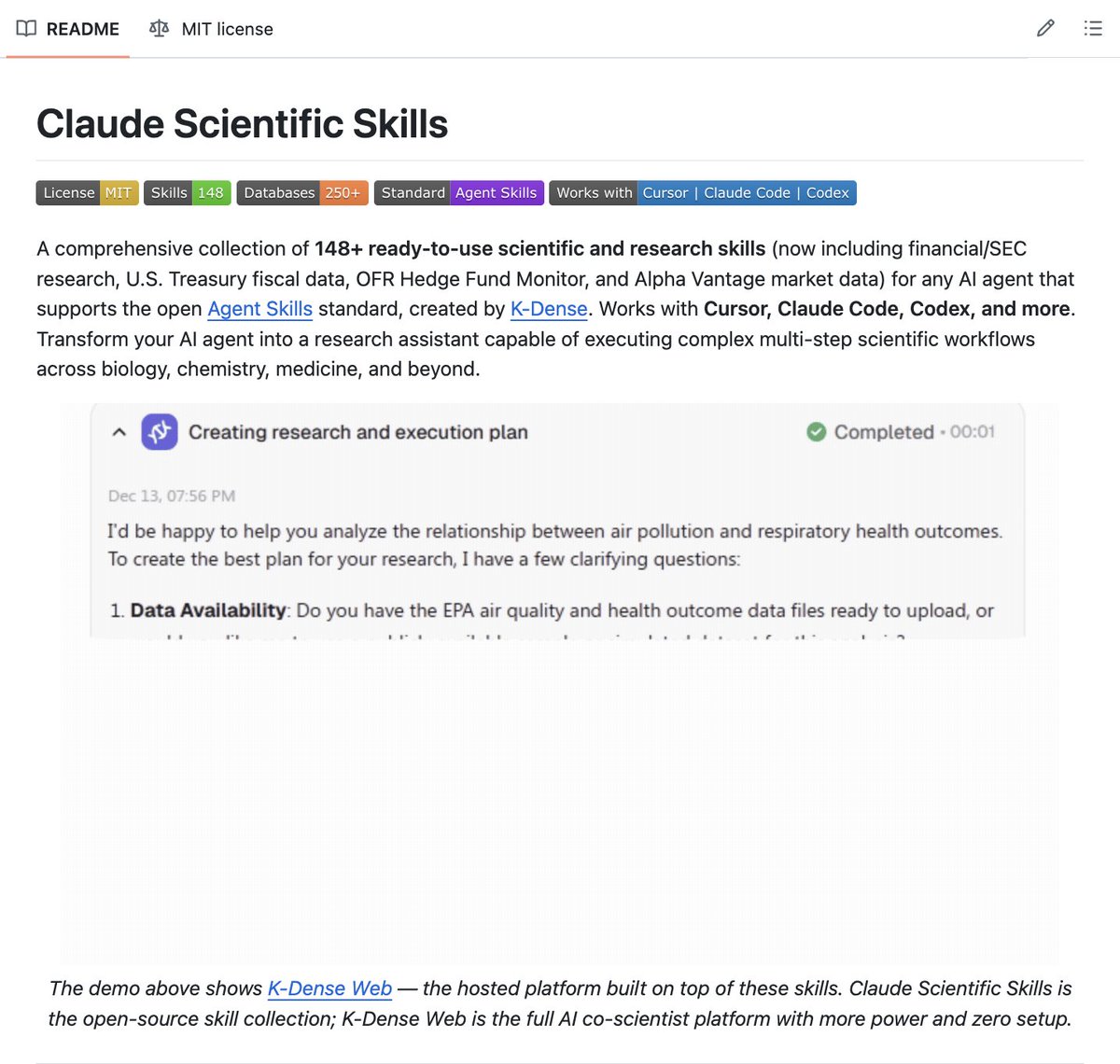
🚨 Someone just turned Claude into a full AI research scientist.
This GitHub repo called claude-scientific-skills just quietly changed what's possible with AI in science.
Most people are using Claude to write emails and summarize docs.
These researchers are using it to run actual drug discovery pipelines, analyze single-cell RNA sequencing data, interpret clinical variants, and generate publication-ready reports all from a single prompt.
Here's how it works:
You install one plugin in Claude Code. Claude automatically discovers and uses 140 scientific skills across every major research domain bioinformatics, cheminformatics, proteomics, clinical research, medical imaging, materials science, quantum computing, laboratory automation.
The skills connect Claude directly to the databases and tools scientists actually use:
→ Query ChEMBL for bioactive compounds
→ Annotate variants with ClinVar and Ensembl
→ Dock molecules with DiffDock against AlphaFold structures
→ Analyze 10X genomics data with Scanpy
→ Search ClinicalTrials. gov and match patients to trials
→ Generate PDF clinical reports with ReportLab
One prompt. Real scientific libraries. Live database APIs. Actual results.
This is what happens when someone stops treating Claude like a chatbot and starts treating it like a research platform.
/plugin install scientific-skills@claude-scientific-skills
100% Opensource. MIT License.
(Link in the comments)
Join us at Cell Symposia: Single-Cell Biology in the Era of AI (Dec 2–4, 2026, Munich) 🇩🇪
From multi-omics to AI-driven models of cellular dynamics — an exciting lineup across experimental & computational biology.
Hope to see you there!
🔗 https://t.co/bGczW7EYhS
This May 10-15 in Les Diablerets, Switzerland, we are bringing cutting-edge research from leaders in single-cell omics and artificial intelligence (AI) to GRC Single-Cell Genomics 2026! If you’re interested, please submit your abstract ASAP! https://t.co/RZ98FQrWuM
We are opening applications for our 2026 cohort of FutureHouse AI-for-Science Independent Postdoctoral Fellows! Apply our AI tools to specific problems in biology and biochemistry, in collaboration with world-leading academic labs:
--$125,000 annual stipend.
--Access to all tools developed by FutureHouse and Edison Scientific at scale, including Kosmos and several as-of-yet unreleased agents, with under-the-hood access to them to specialize them for your workflows.
--Receive dedicated software engineering support.
--1 year with possible 1 year extension.
Even more exceptional co-advisors than last year. Deadline for applications is February 13th, 2026. Link in next post.
Nature Methods names AI agents a “Method to Watch”!
We've started building active-learning loops with perturbation models, where AI proposes experiments & data closes loop. Supplying such models to agents could transform exp design into theory search.
https://t.co/NYlNlFchNf
We are searching for computational PhDs and Postdocs to join our group in collaboration with @TreutleinLab . We have exciting single-cell technology projects that incorporate bioengineering, computation, biology, translation. Send CV to [email protected]
biologists continue to mistake single-cell technical sampling noise for meaningful cellular heterogeneity. the apparent sparsity of single-cell data is due largely to technical artifacts like transcript capture and sequencing depth--if there are hundreds of thousands of transcripts per cell but you sequence only 5-10k unique molecules, of course you get mostly zeroes in any given cell. pseudo-bulking makes this clear: when you aggregate these noisy single cell samples, the vast majority of the genome shows expression greater than zero
this is because the entire genome is being pervasively (yet stochastically) transcribed across nearly all cell types, including terminally differentiated cells (with a few obvious exceptions, e.g. enucleated red blood cells, spermatozoa, etc). hence you should expect to find at least one copy of nearly every transcript if you sample a single cell deeply enough over time
it is the *relative* or *ranked* differences in expression compared to this low-level baseline that dictate cellular identity and function
yet this pervasive transcription extends to retrotransposons, heterochromatin, and other supposedly "silenced" regions of the genome--all of which are systematically discarded in most standard processing pipelines. stare at the raw .fastq for long enough and this becomes obvious
thus, this pervasive genome-wide transcription has implications not only for how we train virtual cell models on single-cell RNA count data, but for our understanding of cellular biology as a whole: to truly plumb the depths of the cell, we must venture beyond the reference genome into transcriptional terra incognita, where we will encounter eldritch species of non-coding RNAs that may throw into question much of what we know about the biology of the cell
We are hiring a Postdoctoral Fellow in Computational Biology at EMBL-EBI (Cambridge, UK). Focus: methods to study cell–cell com from sc/spatial omics data (building on LIANA+ and NicheNet), in collab with
@YvanSaeys VIB.
Details & apply by 13/10/25: https://t.co/MzCKhbykzP
Code to complex: AI-driven de novo binder design
1. This review by Fox et al. explores how AI has transformed de novo protein binder design, making it possible to rapidly generate high-affinity binders for diverse targets with improved efficiency and reduced resource requirements. The integration of AI into protein design marks a significant shift in the field, enabling the creation of custom binders that can neutralize toxins, modulate immune pathways, and engage disordered targets with high specificity.
2. The authors highlight the evolution of protein design from early rational design efforts to the current AI-driven approaches. They discuss how advancements in AI, such as the development of diffusion models and deep learning techniques, have enhanced the accuracy and flexibility of protein structure prediction and design. These improvements allow for the generation of binders with tailored architectures and functions, overcoming previous limitations in predicting sequence-structure relationships.
3. A key innovation is the use of generative diffusion models like RFdiffusion, which can design proteins with specific user-defined architectures and binding geometries. This approach, combined with sequence design models such as ProteinMPNN, has significantly increased the success rates of binder design compared to traditional methods. The integration of these tools into a powerful pipeline enables the in silico generation of binders with high experimental success rates.
4. The review also addresses the challenges and future directions in AI-driven protein design, including the need for better predictive accuracy, expanding the scope of targetable proteins, and addressing issues related to delivery and immunogenicity. Additionally, the authors emphasize the importance of ethical considerations, data integrity, and open access to computational resources to ensure equitable access and responsible use of these technologies.
5. The potential applications of AI-designed binders are vast, ranging from toxin neutralization and immune modulation to the development of novel diagnostics and therapeutics. Recent successes in designing binders for challenging targets like snake venom toxins and immune receptors demonstrate the real-world therapeutic potential of these approaches. As the field continues to advance, AI-driven protein design is poised to revolutionize medicine and biotechnology by enabling the rapid creation of highly specific and functional proteins.
📜Paper: https://t.co/YMmCMZmu8j
#AIDrivenDesign #ProteinEngineering #DeNovoBinders #StructuralBiology #Biotechnology #TherapeuticDevelopment
We're hiring a DFG-funded PhD student (TVöD E13, 65%) at Max Planck Institute, Marburg to study quorum sensing in Klebsiella & host–pathogen interplay. 3 yrs, start flexible. Apply by Sep 30, 2025 (rolling). Send 1 PDF to [email protected]