Why Fortune 500s Trust a Farm Kid to Build Their AI 🤖🌾
(And how baling hay taught me to cut through Silicon Valley’s BS)
14 years ago, I left our 4th-gen Kansas farm to build tech.
2 exits. 44 fails.
Now I've deployed AI for Adobe, NBC, PGA Tour and governments.
The secret?
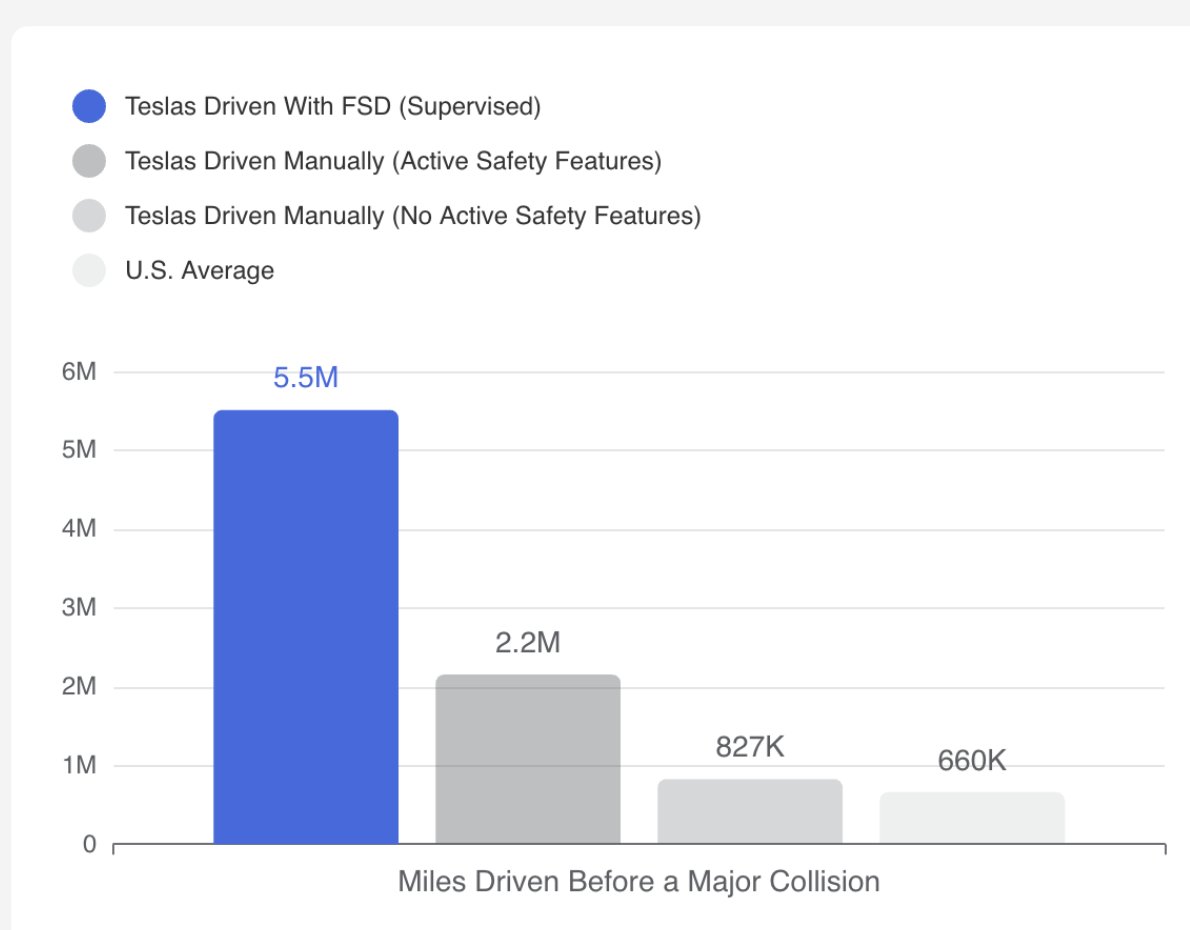
People completely miss the most important thing about Tesla FSD
It’s not just about convenience. It’s not a "cool self-parking trick."
It’s about the fact that car crashes are the #1 killer of healthy people aged 5-29 globally and one company has gathered over 10 billion miles of real-world data to actually solve it
Look at the recent data: Tesla just became the FIRST vehicle to pass NHTSA's new ADAS safety tests. Not the first EV. The first vehicle. Period.
The reality is harsh but simple. Countries that approve FSD get safer roads overnight. Countries that delay will literally watch their citizens die in preventable crashes while bureaucrats sit in meeting rooms debating "safety."
The "safety" argument against FSD is officially dead
Introducing PostHog Code, the product editor that:
- Understands your product
- Identifies usage patterns
- Triages bugs and errors for you
- Creates PRs to fix them
- Continuously monitors and improves your product
Join the waitlist: https://t.co/pTuwqCzo1I
The 0.01% Are Building the Next Layer
@gkisokay posted a stat this week that stopped me mid-scroll. 84% of people have never meaningfully touched AI. 0.3% pay for it. 0.01% are doing what you and I are doing: running agents at 2 AM, building toolchains, compounding every day.
That number felt right. But what struck me wasn't the gap. It was the acceleration.
Three stories from this week show what the 0.01% are actually doing while everyone else debates whether AI is useful.
A guy sequenced his entire genome on his kitchen table.
@SethSHowes used a MinION sequencer, Evo2, and AlphaGenome. All running locally. Never connected to the internet. Found mechanisms behind multigenerational health patterns his family had tracked for decades but never understood.
This wasn't a research lab. It was a kitchen table in what sounds like a normal house. The sequencing hardware costs less than a used car. The models are open source. The compute ran on consumer GPUs.
A decade ago, this required a university partnership, six figures in funding, and months of institutional review. He did it over a weekend because he refused to hand his genetic data to a company.
That refusal is the part that matters. The tools existed before. The conviction to use them on your own terms is what created the outcome.
@NicolasZu shipped something that broke my mental model of what a development environment is.
He built a full game inside OpenAI's Codex. Thousands of zombies. Factory optimization. Browser-based. 100% AI engineered. But the part that matters: he was designing INSIDE the running environment. Not writing code in one window and checking output in another. He was playing the game, making design decisions in real-time, and the AI was implementing changes around him.
This is what building looks like when the loop between intent and artifact collapses to zero. The separation between "thinking about what to build" and "building it" disappeared.
I've been writing about taste being the new bottleneck. This is what happens when production cost hits zero: the person with the clearest vision ships the most. Not the fastest coder. The clearest thinker.
Then @bcherny nailed the piece most AI coding workflows skip: verification.
His /go skill has Claude test itself end to end, simplify the code, then put up a PR. One command. The output is code that was reviewed before a human ever touched it.
I've been building something similar for my own workflows. The pattern is the same every time: the builders who survive the next two years won't be the ones who generate the most code. They'll be the ones who built the tightest verification loops.
Dark code, the kind nobody understands because an AI wrote it and automated checks passed it, is already the biggest liability in most codebases. @bcherny's approach is the antidote.
Zoom out and the pattern is clear.
Genome sequencing on a kitchen table. Game development inside a living runtime. Self-verifying code pipelines. None of these are theoretical. All of them shipped this week. All of them were built by individuals, not teams.
The 0.01% aren't early adopters. They're infrastructure builders. The tools they're creating today become the platforms everyone else uses tomorrow.
I think about this through a lens that most tech commentary misses. We're not just building faster. We're deciding what gets built. Every tool, every workflow, every automation carries the values of the person who made it. The 0.01% aren't just gaining a competitive advantage. They're shaping what AI becomes.
That's a responsibility, not just an opportunity.
The early internet had the same dynamic. The people who learned HTML in 1995 didn't just get jobs at startups. They shaped what the web became. The decisions they made about openness, accessibility, and distribution still echo today.
We're in that window now with AI. The gap between the 0.01% and everyone else isn't closing. It's accelerating. And the choices being made right now, by the people building at 2 AM on their kitchen tables, will determine whether this technology serves human flourishing or just serves itself.
Lock in. But lock in with purpose.
A design tool now reads your codebase and brand assets, then outputs a machine-readable skill file any future AI agent can consume to produce on-brand work.
Design systems just became agent infrastructure.
The pattern keeps repeating. Every domain, from coding to design to ops, eventually produces a portable context file that agents can read. Google's DESIGN.md spec this week does the same thing from a different angle.
The moat isn't the model. It isn't even the product. It's the context layer that makes agents useful in your specific world.
Most organizations are generating enormous volumes of AI-touched knowledge right now. Meeting summaries, strategy documents, research outputs, Slack threads.
Almost all of it is write once, read never.
Nobody is synthesizing across those documents. Nobody is flagging that the Q2 strategy deck contradicts what the CEO said in last week's all hands. Nobody is checking that engineering's 12-week estimate matches what sales promised the client in 8.
Your company's AI-generated knowledge is either a compounding asset or a growing pile of noise. Which one are you building?
Six months ago, any piece of software without an API was effectively outside the automation conversation. You had to wait for the vendor to ship hooks or build the integration yourself.
Computer use changed that math. If the software has a screen, an agent can drive it. Clicking, typing, navigating, all in the background while you work on something else.
The surface of what's automatable just got much larger than most people are budgeting for. And the reason it works now isn't the model. The model is the brain. The harness around it is the body. The body is what changed.
Language models predict tokens. World models simulate physics.
@odysseyml just shipped Odyssey-2 Max and it advances SOTA on physical accuracy. Models that simulate and interact with the real world in real time.
This is the piece the agent stack is still missing. You can give an agent a coding tool, a browser, a file system. But agents that operate in physical space need something beyond text prediction. They need a world model that understands gravity, friction, and spatial relationships.
The next frontier isn't smarter chat. It's accurate simulation.
@nikitabier just revealed what might be X's biggest distribution shift since the algorithm went public.
Custom Timelines. 75+ topic channels you can pin to your home tab, powered by Grok. The monolithic feed is splitting into niches.
For creators, this changes the math. Your content doesn't just compete in one feed anymore. It lands in topic-specific channels where intent is higher and competition is narrower.
For builders: narrower channels mean your technical posts reach the people who actually care about the subject. Distribution just got more precise.
The people who built reasoning at OpenAI just started a lab to automate research itself.
@sethbannon describes @CoreAutoAI as the world's most automated lab. Jerry Tworek, who led the development of reasoning models, is building systems that optimize and automate the scientific process.
The recursion here is the point. Researchers building tools to replace the research process. Not in theory. As the first product.
Two weeks ago I watched an agent run 910 experiments in 8 hours for under $300. That was a demo. This is a company.
A new AI lab built from the ground up around automated research.
Led by the legend Jerry Tworek, former VP of Research at OpenAI, where he led the development of reasoning models. Absolutely incredible founding team. Heavy hitters out of OAI, Anthropic, DeepMind.
Core idea: scaling models, data, and static deployment won't get us to the promised land. We need something different: new learning algos, new architectures, and systems that automate the process of building itself.
As they say, they're "pursuing new learning algorithms that supersede large-scale pretraining and reinforcement learning, and architectures that scale better than transformers."
An AI to build AI.
Google just open sourced something that matters more than most model releases.
DESIGN.md: a portable specification that lets agents understand design intent. Export your design rules from one project, import them into another. No guessing. No hallucinated layouts.
This is the pattern I keep watching unfold. Context portability. The same principle behind why your personal AI outperforms the corporate rollout: it knows your preferences. DESIGN.md does that for visual systems.
Agents that can read design specs will ship better products than agents that guess from screenshots.
Today, we’re open-sourcing the draft specification for DESIGN.md, so it can be used across any tool or platform. We’re also adding new capabilities.
DESIGN.md lets you easily export and import your design rules from project to project. Instead of guessing intent, agents know exactly what a color is for and can even validate their choices against WCAG accessibility rules.
Watch David East break down this shared visual language in action👇. New capabilities and links in 🧵
The compute layer just married the product layer.
@SpaceX has a million H100 equivalents. @cursor_ai has the most popular coding interface in the world. Now they're one entity.
This isn't a partnership announcement. It's a vertical integration play. The company that trains the models now owns the surface where developers use them.
Six months ago, the bet was that models would commoditize and distribution would win. That's still true. But this move says something else: if you control both the training cluster and the IDE, you can optimize the full loop. Model to interface to feedback to retraining.
Every other coding AI company just lost a step in the supply chain.
SpaceXAI and @cursor_ai are now working closely together to create the world’s best coding and knowledge work AI.
The combination of Cursor’s leading product and distribution to expert software engineers with SpaceX’s million H100 equivalent Colossus training supercomputer will allow us to build the world’s most useful models.
Cursor has also given SpaceX the right to acquire Cursor later this year for $60 billion or pay $10 billion for our work together.
Your AI knows four things about you that matter. Most people only think about one.
1. Domain encoding: your industry vocabulary, products, competitive landscape, regulatory environment.
2. Workflow fingerprints: the specific sequences you follow, the tools you chain together, the order you check things.
3. Relationship maps: who you go to for what, which stakeholders need which framing, the org chart that lives in your head.
4. Judgment calibration: the thresholds where you escalate, the patterns that trigger your attention, the tradeoffs you make automatically.
Most agent setups only capture layer one. The real leverage is in layers three and four. And those are the ones you can't just type out in a prompt.
Don't make your first agent your personal assistant. Make it the one that prepares you to have a personal assistant.
The most common message in agent community forums is two words: "Now what?"
People install the agent in 10 seconds. Then they stare at it. They don't know what to tell it because they've never articulated what they actually do at work in enough detail for delegation.
15 paragraphs of text instructions still fail. Not because the agent is dumb, but because professional expertise lives in layers you don't think to describe. The patterns you notice without noticing. The judgment calls that feel automatic.
Before you delegate anything, extract what you know. That's the step everyone skips.
You're building the most valuable asset of your career inside AI tools you don't control.
Every prompt, every correction, every document you feed into Claude or ChatGPT teaches the system your vocabulary, your market, your judgment patterns. Months of honing. And it's locked to one platform under terms you didn't negotiate.
We need BYOC: Bring Your Own Context. A portable professional identity that moves between tools, between jobs, between whatever AI platform wins next quarter.
The person who builds their context portably today compounds their AI effectiveness across every tool shift. The person who doesn't starts over. Every time.
Cloudflare just shipped a versioned file system that speaks git. Every object gets a content-addressed hash, branches, and merge semantics built in.
@dillon_mulroy called it the coolest thing he's ever built. I think it matters because of what it enables for agents.
Agents need durable state. Not just memory, not just context windows. Actual versioned artifacts they can create, branch, and roll back. This is the storage primitive that was missing.
Agents can write, code, talk, and operate autonomously. They couldn't edit video. Now they can.
@liu8in open sourced HyperFrames: an HTML-based video toolchain that lets agents compose and edit video the same way they manipulate web pages.
The abstraction is the insight. Video editing was locked behind proprietary timelines and frame-level manipulation. HTML made it text-addressable. Suddenly agents have a surface they already understand.
What's the next creative domain that gets unlocked by the right abstraction layer?
500+ commits across 100+ public repos in 72 hours. GitHub suspended the account.
This is the collision point between agent-speed output and human-speed infrastructure. The platforms weren't built for this throughput. Rate limits, abuse detection, review queues: all calibrated for humans.
The tool call bottleneck pattern keeps showing up everywhere. The agent isn't the constraint. The systems around it are.
The Tools Are Free. The Judgment Isn't.
A list of 10 open source repositories went viral this week. Voice synthesis, agent platforms, knowledge bases, file detection. All free. All replacing tools that cost $1,500 a month six months ago. @seelffff compiled the list and it hit 337,000 views in four days.
That number should make every SaaS founder uncomfortable. But the real story isn't about pricing pressure. It's about what happens when the capability layer becomes commoditized and the judgment layer doesn't.
Three things happened this week that tell the same story from different angles.
@bcherny shared his Claude Code workflow. He built a single skill called /go that has Claude test itself end to end, simplify the code, then put up a PR. One command. The output is code that works, not code that compiles.
This sounds simple. It is not. Most builders using AI coding tools generate code, eyeball it, and ship. The verification step is where the quality lives, and almost nobody automates it. Generation became free. Verification stayed expensive. @bcherny closed the loop, and that's the difference between shipping software and shipping something good.
Meanwhile, @SethSHowes sequenced his entire genome at home. On his kitchen table. Used a MinION sequencer smaller than an iPhone, open source DNA models running locally, and never exposed a byte of data to the internet. Found mechanisms behind multigenerational autoimmune conditions that clinical medicine missed.
The tech for genome sequencing existed for years. The barrier wasn't capability. It was trust. The moment you require a cloud round trip for genomic data, you lose everyone who will never opt in. Seth solved a trust problem, not a technology problem. The open source models running on local hardware made the trust model work.
Same pattern as I wrote about with Gemma 4 running on phones last week. The infrastructure for private AI is arriving faster than the applications being built for it.
Now zoom out to the enterprise. Companies are building world models, AI systems that maintain a living picture of everything happening across the organization. Status, dependencies, resources, customer signals. The pitch is compelling: nobody waits for the Monday meeting, nobody needs a middle manager to carry context.
But the failure mode is subtle. When the system surfaces information ranked by relevance, that ranking is an interpretation. It's a claim about what matters. Nothing in the architecture distinguishes surfacing from interpreting. The editorial function gets automated by default, without anyone deciding to automate it.
When a company removes managers and replaces them with nothing, the chaos is visible. Diagnosable. Fixable. When a company removes managers and replaces them with a world model, the information keeps flowing. Status gets synthesized. Reports get generated. But the judgment disappeared, and nobody noticed because the dashboards look so clean.
This is the pattern connecting all three stories.
The capability layer is collapsing toward free. Voice synthesis, code generation, genomic analysis, organizational intelligence. All of it increasingly available, increasingly open source, increasingly running on hardware you already own.
But the judgment layer remains stubbornly human. Knowing what to verify. Knowing what to trust. Knowing when the system's confident output deserves skepticism. Knowing that a correlation in transaction data is not causation, even when the data is clean.
The builders who win in this environment aren't the ones with the best models. They're the ones who close the verification loop. Who build trust architectures that make sensitive applications possible. Who draw the line between "act on this" and "interpret this first" before the system draws it for them.
I keep coming back to something I wrote about taste last week. AI made production cheap. Taste stayed expensive. Now I'd add: AI made capability cheap. Judgment stayed expensive.
The moat was never the model. It was never even the data. It's the ability to know what matters when everything looks equally authoritative.
What's the judgment call in your work that no model can make for you?
Kimi K2.6 just posted open-source SOTA on SWE-Bench Pro, BrowseComp, and HLE with tools. Beating closed models on coding benchmarks that matter.
Six months ago, open source was two generations behind. Now the gap's measured in weeks.
The commoditization curve keeps steepening. Closed model providers have to outrun open source on reasoning speed, not just capability. How many quarters before the distinction stops mattering entirely?
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: https://t.co/uvoSJKyGCY
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/9wWvgIQSS3
🔗 Weights & code: https://t.co/Be0hjs2RTP