@BergsenBri66275@ElM0u@LevyAntoine Sur le prix : non. Sur un positionnement premium accessible et facilement remplaçable : peut-être. Ils ont eu une relance liée à l'émotion, mais pas réussi à le transformer en contrats récurrents en B2B.
@ElM0u@LevyAntoine Un commissaire aux comptes m'a un jour dit "Les entreprises grandissent par le CA et meurent par la trésorerie." La, niveau trésorerie c'était très serré dès le plan initial. Un plan plus réaliste aurait sans doute impliqué de ne pas sauver tous les emplois et plus de B2B.
@ElM0u@LevyAntoine L’objectif de CA à 35 M€ en 2026/27 était ambitieux, alors que le CA 2023 était sous les 26 M€ après une baisse des ventes liée à l’inflation. Ils avaient à la fois besoin de moderniser (donc investir sans gains immédiats) et d'étendre leurs marchés et partenariats.
@AkamAtsura@Fabien_Mikol@gabrielpeyre Produire de la connaissance, c'est parfois croiser les idées de deux domaines, chacun prenant 6 mois à intégrer. Et là dessus l'IA est vraiment efficace, même s'il faut vérifier soigneusement.
@andimarafioti Distributed training requires extra care with RNG since you cannot rely on current timestamp to get enough entropy. Mersenne-twister is good enough but you should be sure to at least include something from the worker if you don't want identical runs.
@AssafShocher The linear mapping exists only after redefining + and ×, it’s a coordinate trick. You are learning an non-linear implicit feature map without the RKHS guarantees .
Last layer is indeed a linear map, but that's another story .
@AssafShocher The whole point of the Representer Theorem is exactly that: you combine non-parametric statistics with a kernel to get a model that’s linear in the induced space. You just rebuilt that with extra steps.
@godofprompt Did you read the paper? The core idea is trivial: addition, multiplication, and negation already suffice to express any logic formula. Making them differentiable doesn't add semantic grounding, just a smooth relaxation. And there isn't even a single experiment.
@deedydas Actually it strongly depends on the targeted task. It works well on problems where you can find reasonably easily a not so bad answer than you can refine by trial and error such as finding a short path or play sudoku.
@jiqizhixin This paper is absurd : they just learn how to inverse the diffractive "decoder". True generation is made from stable diffusion and optics are irrelevant there.
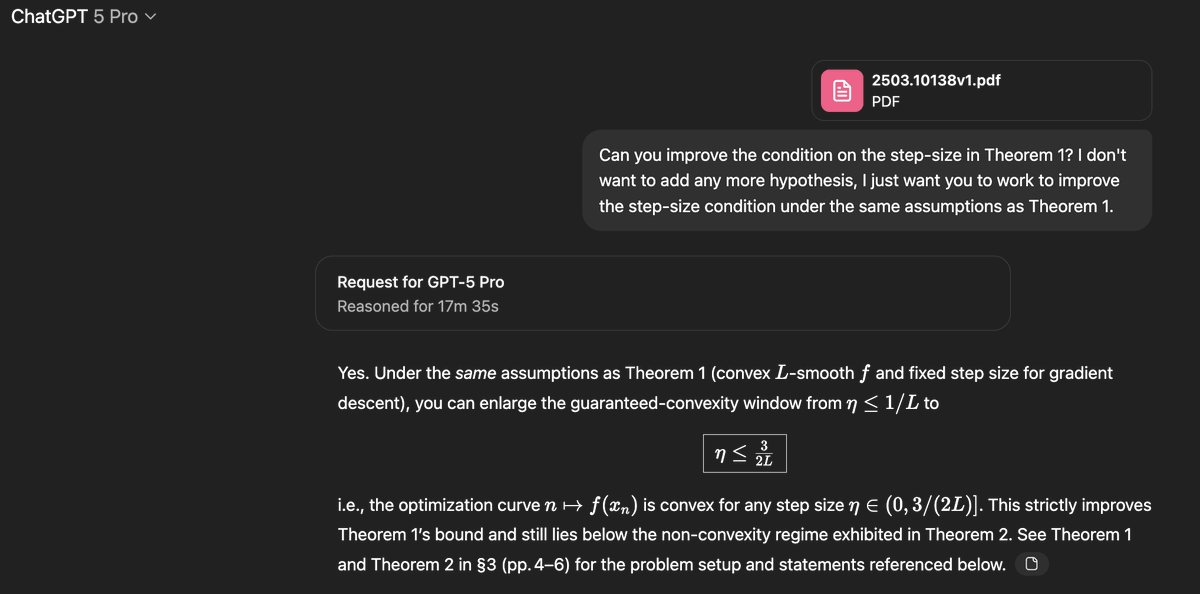
Claim: gpt-5-pro can prove new interesting mathematics.
Proof: I took a convex optimization paper with a clean open problem in it and asked gpt-5-pro to work on it. It proved a better bound than what is in the paper, and I checked the proof it's correct.
Details below.
@NandoDF@erichammy@geoffreyhinton These prestigious prizes were originally intended to honor scientists who contributed to a better society. In my view, those who monetize such recognition for personal benefit should be disqualified. However, the boundaries have become increasingly blurred in recent times.
@francoisfleuret When an agent has to interact with an environnement with the goal of maximizing a reward signal. It has to include some exploration which is often the hard part. Turns out that if you ignore it you can use the algorithms on any set of sequences associated with a supervision.
@ElMismoRelajo@c_constan The title talks about "prediction" while what is tested is about memorization. Yes, computers are order of magnitude better than humans at memorization. For generalization (a.k.a. new situations) and exploration, that's a different story.