Future prediction is deep research under uncertainty. It requires evidence gathering, tracking change, and careful reasoning. Apodex take the top 4 spots on FutureX with our experimental prediction harnesses — using only Apodex-1.0-mini, our 35B model: https://t.co/jInixUj5Ki
Meet 𝗔𝗽𝗼𝗱𝗲𝘅 𝟭.𝟬 🔭 — a heavy-duty agent team for deep research, which sets the SOTA! The team searches the web, reasons over evidence, and writes reports where every claim is backed by an explicit 𝘦𝘷𝘪𝘥𝘦𝘯𝘤𝘦 𝘤𝘩𝘢𝘪𝘯, independently audited before delivery.
🌐 https://t.co/pOQAjL92uF
Just wrapped our first @aiDotEngineer singapore. Hats off to @agrimsingh@SherryYanJiang@swyx for this incredible event.
3 days at Capitol Singapore, hundreds of builders in the room.
A year ago, "more AI Engineers than ML engineers" was a forecast. Today, you could feel it on the floor.
At our booth, the most common question wasn't "what does your agent do?" It was "how do you know when it's wrong?" Conversations skipped the demo and went straight to traces, eval setups, error handling, how the agent verifies itself. #AIESG
Can we actually TRAIN LLMs for scientific discovery — or only prompt them to brainstorm? 🧬✨
🎉 MOOSE-Star → #ICML2026
Most work on LLMs for hypothesis discovery focuses on inference-time agents or feedback-driven refinement. The core generative process — P(hypothesis | research background), or P(h|b) — has been largely sidestepped: directly training it remains an open problem. We show why: a combinatorial complexity barrier makes naive end-to-end training mathematically intractable.
First scalable recipe for training P(h|b), with clean scaling laws on both training data and test-time compute.
📄 Paper: https://t.co/VH36cDIIz0
💻 GitHub: https://t.co/H3ewP99ydj
🤗 HF: https://t.co/BnLb7tcsRc
🧵👇
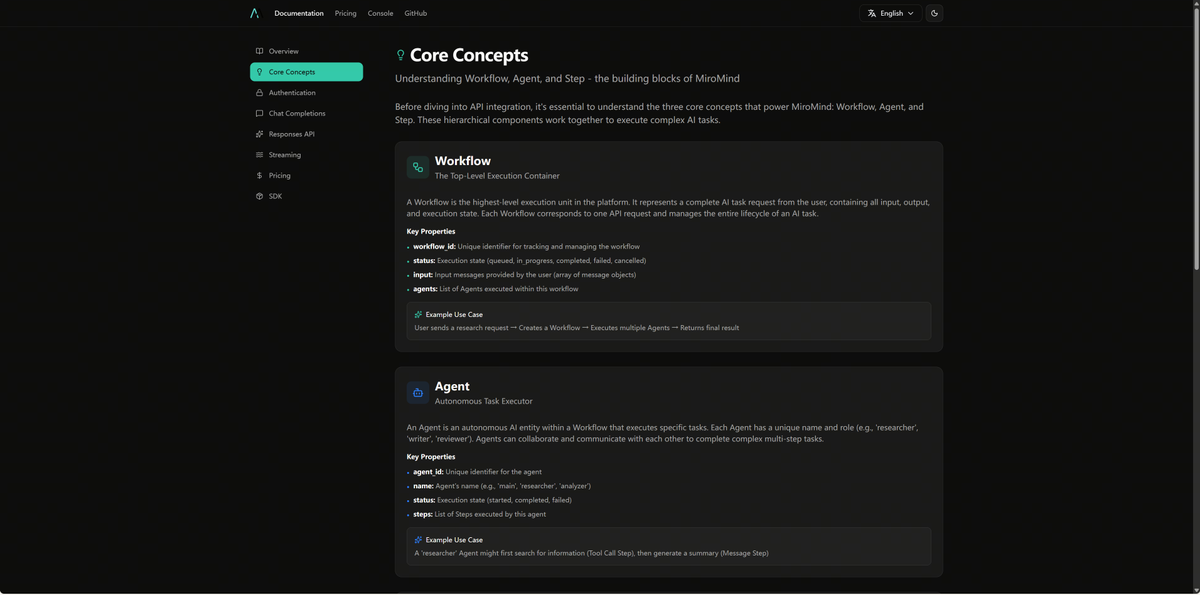
🚀The MiroThinker API went live!
Interactive scaling —up to 300 tool interactions per task × 256K context:
🧠Two engines:
▸ mirothinker-1-7-deepresearch (235B) — GAIA-Val 82.7 · BrowseComp 74.0 · HLE-Text 42.9
▸ -mini (30B) — BrowseComp-ZH 72.3 (SOTA at 30B)
Plus the agent infra goodies to ship them:
🔌 Disconnect-safe execution — submit / resume / cancel without losing work mid-run
📜Full traces on every run — each step, tool call, and decision logged. SFT / DPO-ready out of the box.
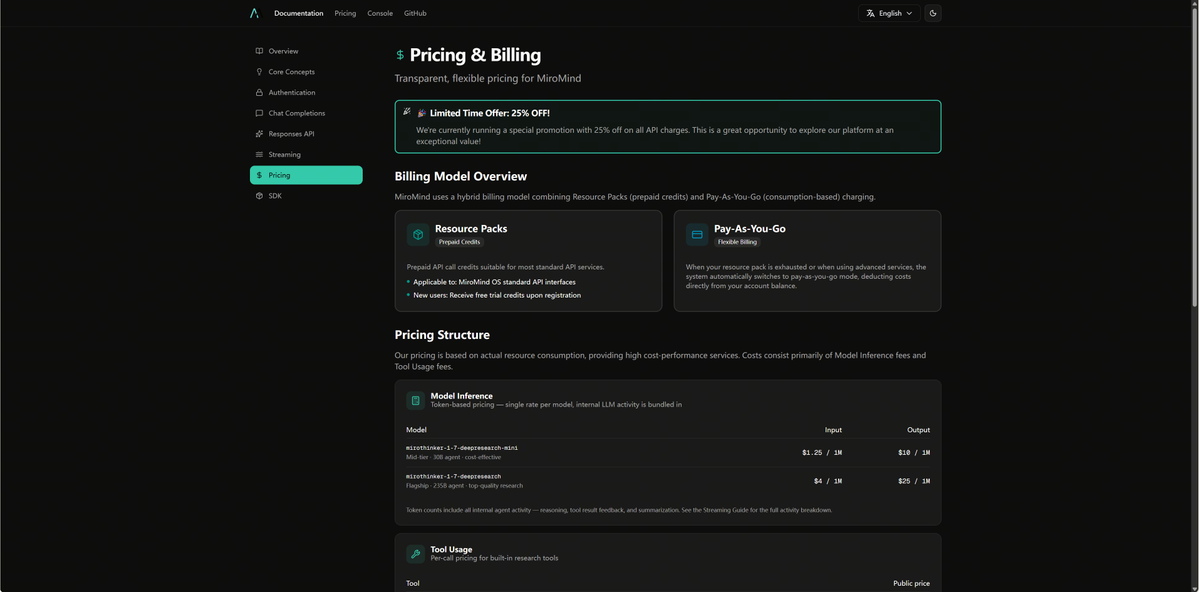
Pre-freeze billing: if our platform fails, you get a full refund.
Cancel mid-run: pay only what compute touched.
From $1.25/M input, 25% OFF at launch.
🔑in the comments👇
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.