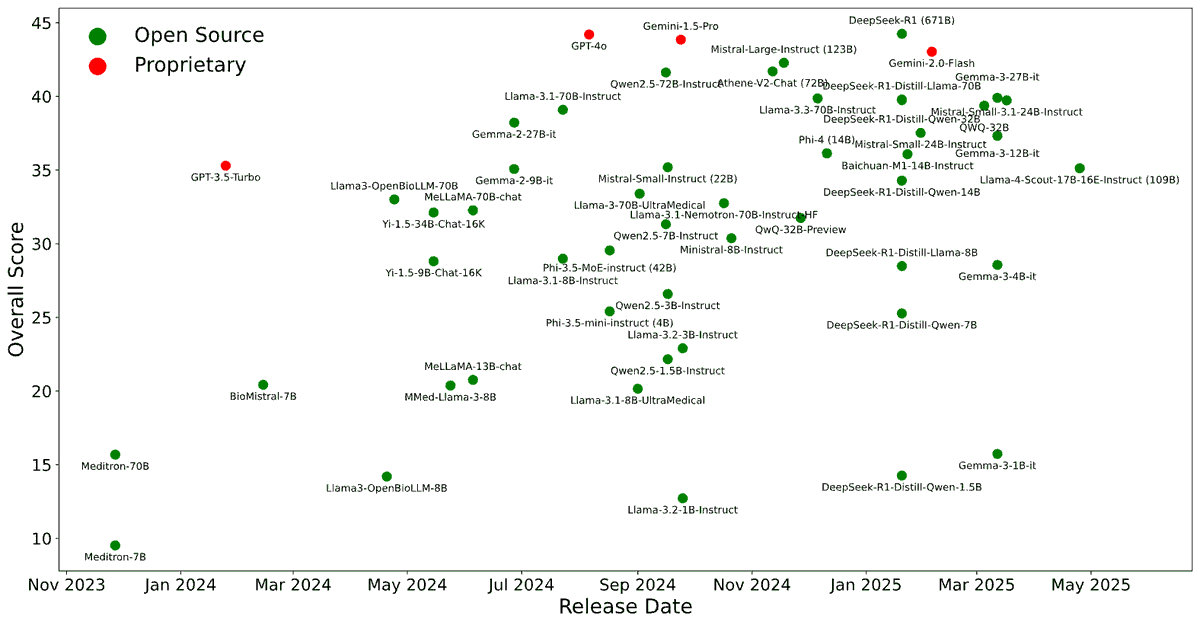
@kchonyc Multiple-choice medical exams oversimplify the complexity of medicine. Try our BRIDGE benchmark, which is based on 87 real-world clinical tasks and includes far more complex, realistic tasks. We have evaluated 95 LLMs with over 3.4 billion LLM inferences https://t.co/M5jxe0LRYT
Great resource! Love seeing more real-world health benchmarks beyond USMLE and PubMedQA! 🙌
Two weeks ago, we also just released BRIDGE, a multilingual, real-world EHR-based LLM benchmark covering 87 tasks in 9 languages.
📄 Paper: https://t.co/awZZiNuMGC
🚀 Leaderboard: https://t.co/9p23YW8KNq
Sure. As I replied to Dan, we can only access the datasets but we don't have the right to redistribute them. Each dataset needs to be requested to the original publisher. We listed all the contact information in our paper. If you think there still exists interested topics that we can discuss, I am happy to the talk.
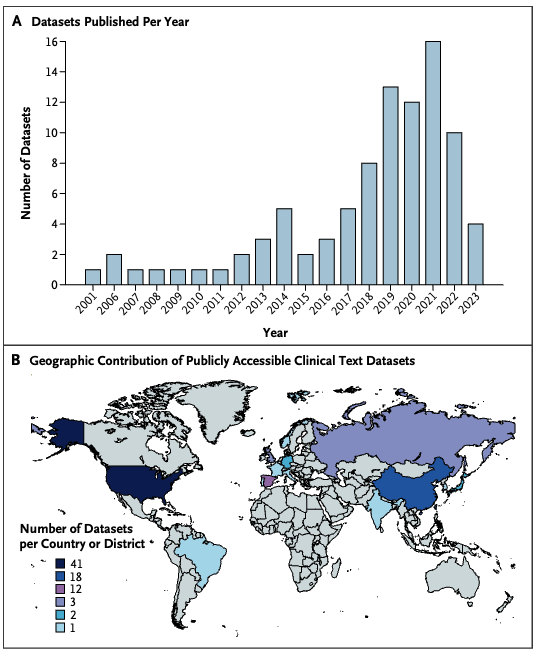
Our recent paper "Clinical Text Datasets for Medical Artificial Intelligence and Large Language Models — A Systematic Review" has been published in @NEJM_AI ! The lack of clinical text data is a long-term challenge/pain for #AIinMedicine and clinical LLM researchers. After reviewing 3962 papers and 239 tasks from clinical #NLP challenges, we found that less than half of these datasets are accessible, with significant regional, language, and disease imbalances. We have shared a list of over 90 accessible clinical text datasets, hoping it can serve as a dataset landscape for clinical NLP research. Free access link: https://t.co/UTnpj5uKAo
@dancaron@NEJM_AI Hi Dan, although we have accessed these datasets, we can't redistribute them. Users who are interested in the listed datasets need to request the dataset from the original dataset publishers (we listed the contact information in our paper).
@LiamGMcCoy@zakkohane@NEJM_AI Thanks! Yes, actually the difficulty of accessing data for published papers is the main reason for us to start this review.
@hbouamor@rose_e_wang@abeirami@emnlpmeeting@juanmiguelpino Hi @hbouamor and @juanmiguelpino , we have the same issue (submission#1538) with score 345 but got rejected without a detailed reason. We sent an email to PCs on Oct 7 but got no response until now. Our follow-up emails also got no response. Can you pls give us an update? Tks
Check out our recent study on changes in outpatient mental health/substance use disorder visits during the initial Massachusetts COVID-19 surge and partial state re-opening. https://t.co/D4KjbEChOf
~2300 tests were reported yesterday from @UWVirology@UWMedicine. Positive rate seems stable. Lab running smoothly the first half of today with lots of results going out. Realtime tracker at https://t.co/81ED3b8zk5
NCRF++ (dev branch) now supports the sentence (and doc) classification! You can build the classification model just using a simple configuration file without writing any code. LSTM/CNN/FF/Attention/Custom features are all supported! (will + BERTs)
https://t.co/Qfbo89oZ4P