Tweets about Health AI, AGI, longevity.
🛸 CEO Health Universe (Kleiner Perkins)
🚀 Co-Founder @arrivehealth (Raised 32M)
🤖 Hacked insulin pump. FDA approved.
Customization to the individual clinician, yes. But "training" means something specific in data science. You don't want training to be based on one individual, because that increases bias dramatically. We can provide the configured models at Health Universe. We also support NHI. ;)
@Berci Great summary of the big moves this year. It's interesting to see how markets outside of the United States are implementing health AI, often at an even faster pace.
This is probably the best paper I have read about causal reasoning for quite some time. Really a great weekend read!
"Causal Persuasion" (Burkovskaya & Starkov) models how much evidence you need to establish vs. rule out a causal link. The result is stark:
To prove X causes Y: 1-2 well-chosen variables often suffice.
To prove X does NOT cause Y: you must account for every possible common cause. Arbitrarily many confounders. Practically unfalsifiable.
This inverts the Humean intuition: in causal reasoning, positive claims are cheap to sell and negative ones are almost impossible to rebut.
Now think about what this means for Virtual Cell models.
Most perturbation datasets cover a thin slice of the combinatorial space — a few hundred gene knockouts, maybe a few contexts. A model trained on that data can confidently "learn" gene X drives phenotype Y. But if the true structure is X←C→Y , and C was never systematically varied — the model will never see its own confounding. It has no mechanism to distinguish causal signal from correlated noise.
The paper formalizes exactly why: the model is a sophisticated receiver that accepts whatever causal story is consistent with the data it's seen. And if the data omits the right confounders, even a "sophisticated" model is manipulable.
This is the deepest argument for perturbation diversity. Not just more data, but also more axes of variation. Vary the context. Vary the genetic background. Vary the timing. You're not just collecting samples; you're systematically eliminating alternative causal explanations.
This is why we need “scale” the training data with more contexts including cell types, spatial, and temporal variations.
Paper: https://t.co/Ayvt8tKtnj
@nikillinit This is why we’re building Health Universe. We have academic medical centers onboard, deploying closed source, medium source, and open source models, applications and agents. This is the way.
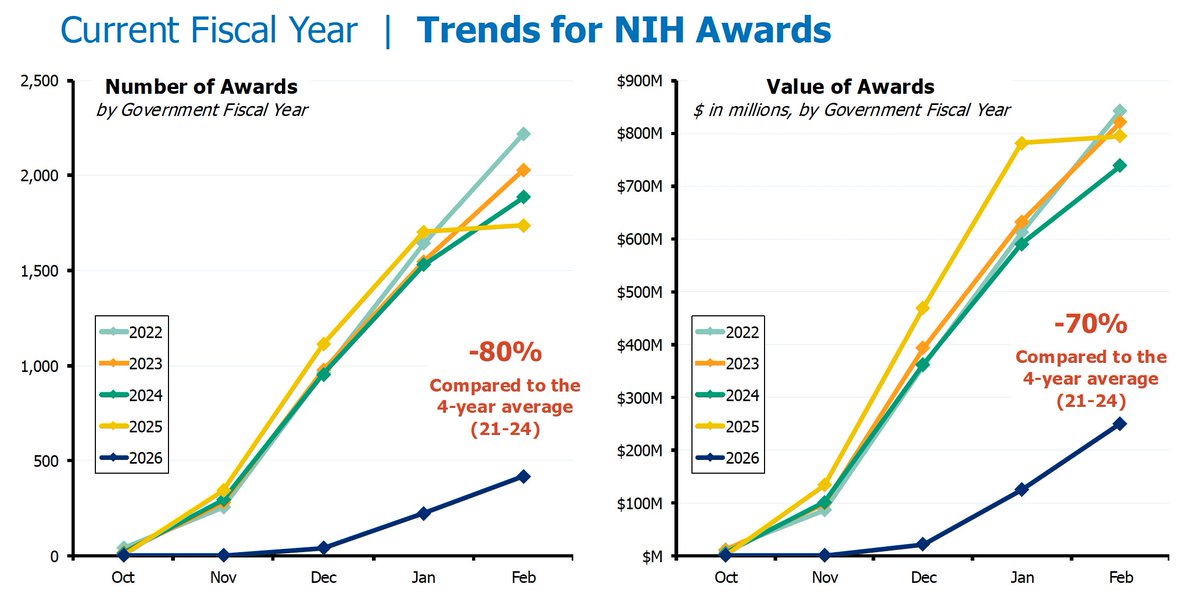
Federal funding for US biomedical research is moribund.
Since October 1 2025, NIH is -80% in new grants and -70% in values (total dollars).
Labs are closing down and researchers are leaving science.
To what end?
Of course Pearl is generally correct. However, models learn to generalize after seeing enough data, which makes them more than basic correlation machines. Deep neural networks form higher level structures that start to imply more generalized intelligence. Dario Amodei spoke to this in a recent podcast. That said, causal modeling, once the AI crowd gets a hold of it, will be a much more powerful approach.
History just happened.
An AI system has autonomously solved a long standing open conjecture in pure mathematics (Fel’s open conjecture on syzygies of numerical semigroups) building a complete formal proof in Lean with zero human input.
This is the first time in history an unsolved theory level math problem has fallen to AI.