Most "private AI" claims are policies. They depend on trusting the vendor.
We just shipped something different. Our AI meeting app, @HedyAI_, can now run the entire AI pipeline on your own device. Summaries, notes, chat, live coaching. Nothing leaves your device.
The demo was recorded with Wi-Fi turned off the entire time. The transcript, summary, and live chat were all generated locally on an M4 Max.
Qwen 3.6, Qwen 3.5, and Gemma 4 in the curated model lineup (quants by @UnslothAI), ranging from 2B for newer iPhones up to 35B for users with serious hardware.
Plus: bring your own model from Hugging Face if you don't trust our curation.
Cloud is still the default. It's faster and produces higher quality output for many users. But that will change over time.
Local AI is opt-in. Built for the meetings that shouldn't happen on cloud tools: privileged client conversations, sensitive interviews, medical appointments, work done offline.
No silent cloud fallback. If local fails for any reason, the app errors out. It does not quietly retry against our servers. You opted into local for a reason, and a quiet retry would defeat the point.
The next few years of AI will be defined by a quiet shift. From a world where a handful of companies operate the AI on your behalf, to one where you can run your own pipeline, on your own device, with your own data, end to end.
Full write up: https://t.co/0e7BoBuClm
@stevibe@bnjmn_marie ping me if you want to test this with your workflows.
With the 450M model it now might be possible to extract image information on less powerful edge devices, such as older and mid-tier Android devices. Could be a game changer for @HedyAI_ if it allows us to allows users to upload photos of slides, etc from their meetings on their phone and we can analyze it on the edge to preserve privacy like we do with voice.
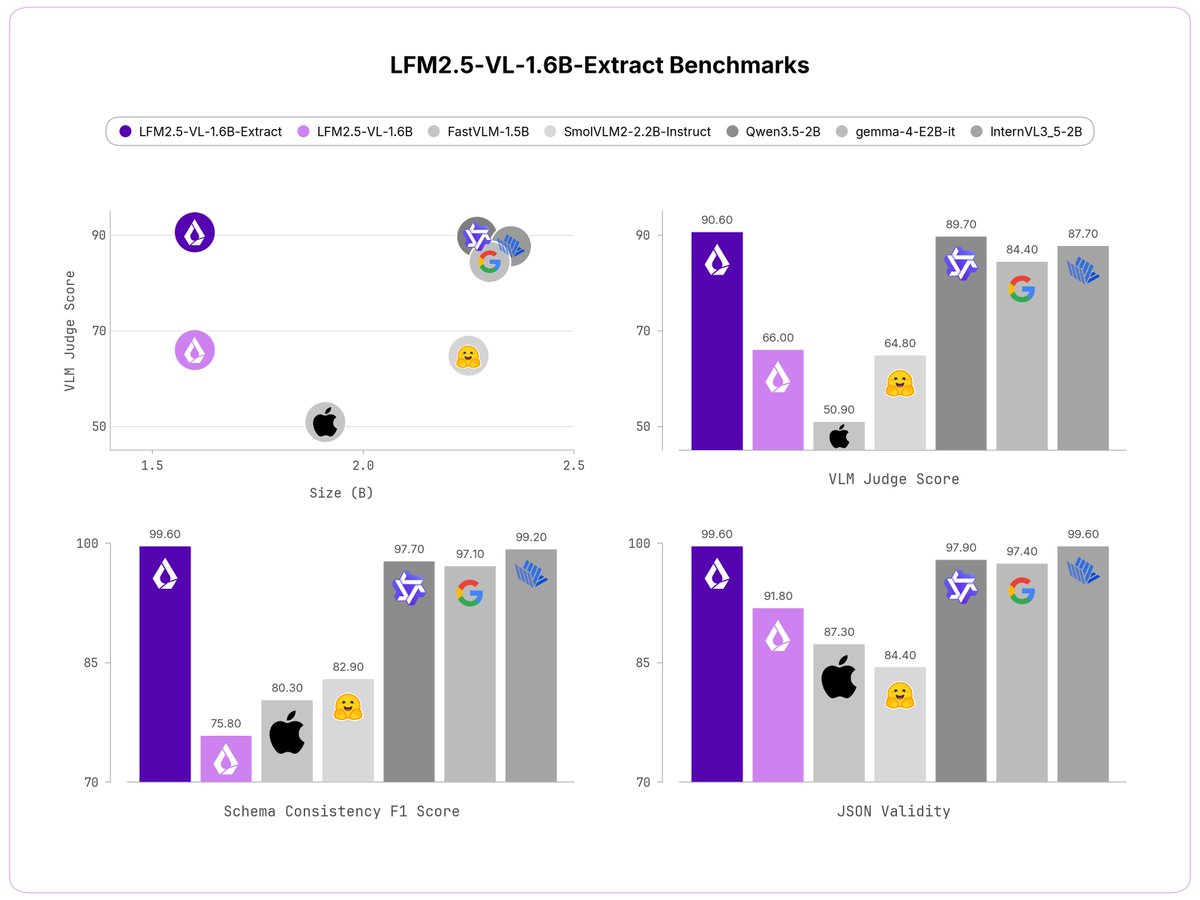
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
@guilhermeotina@liquidai Need to see if the 450M version runs reliably on Android devices using Vulkan with llama.cpp. That would be an incredible unlock.
Testing Gemma 4 12B in @HedyAI_ now for end-to-end AI conversation processing, and it looks like we might have a new best model recommendation. It took a few overnight updates of llama.cpp to get it to run, but now it's cranking. Just had it accidentally still on during a sales call, and it was giving really solid automatic advice. Running on M4 Max 36B.
Celebrating the milestone of a massive 150+ million downloads of Gemma 4 with the release of the new Gemma 4 12B model! It's incredibly powerful for such a small model and it’s tiny enough to run locally on a laptop with just 16GB VRAM. Apache 2.0 license - happy building!
We just dropped Gemma 4 Quantization-Aware Training (QAT) checkpoints on Hugging Face!
All Gemma 4 model sizes and their drafters are now optimized with QAT to cut memory requirements and maximize on-device performance!
@bnjmn_marie Running the 4bit version of 12B in @HedyAI_ now and it looks quite promising. Definitely faster than 27B and quality vibes check out so far.
@FerTech@NousResearch I know people have been using voice convos with Hermes/OC for a while now using other integrations, and I'm sure it's possible to use the new Gemma 4 12B model that have native voice capabilities.
@drbarnard AI design is still brutally hard and the one area it's hard to avoid human labor. Like everyone said at MAU... AI doesn't have taste... yet.