Fable almost got 100% on pencil puzzle bench
Only failures are heyawake puzzles where it spent over $500 in turns trying to figure out the syntax to make moves (there are example moves given to it in context and other heyawake it did solve...)
@SebAaltonen I can't seem to find a quote / a buy option for $85k. so far I've only see $95k from Exxact, much higher (from dell), MSI links go to vendors like newegg at $99,999. etc.
https://t.co/2DTgQYVd6v
76B codex tokens in the last 30 days (10x on ChatGPT pro)
Net, I feel real deminishing returns on the utility. /goal is great, but long lived agents often end up cheating and hyper-fixating on the wrong things.
Bottleneck for me is the human attention to keep agents on track
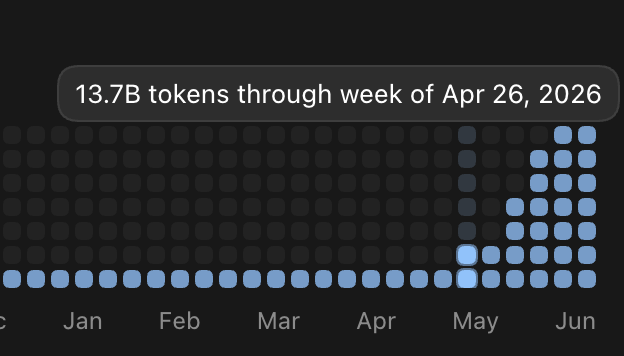
@MadisonMills22 Hmm... last month I was hitting ~25B per week...
I'm getting close to those numbers with 70B/mo.. but still a bit short of 100B or the stated 600B of @steipete
@eliebakouch Love this report
Cluster sizes: 8K GB200 and 4,864 GB300...
estimating from the numbers given for training size: ~7e24 training flop? roughly ~22 days wall clock on 8k gpus? at ~$8/gpu-hr ~= $35M pre-training run
harder to estimate the RL cost/duration (likely similar)
@sarahookr I signed up, tried to upload multiple datasets, nothing worked (lots of errors pop up).
I dont even know what to expect even if the dataset upload did work...
What is the expected "working" version of this app?
what does "get a gpu" mean? definitely not any SSH access it seems.
@samuelcolvin I'm pushing full 10x on top of codex 20x (so 200x) per week, by using many /goal on ai research problems. Essentially managing fleets of experiments, ablations, sweeps from a large backlog. Some individual /goal have been going for over 3 weeks.
@ClayMalott@jxnlco@OpenAIDevs 10x pro really adds up.
I've been mostly a claude code user, probably more tokens there in aggregate, but 5.5 has been great recently.
@lauriewired For nature photography lenses: modern telephotos are a bit magical compared to the 80s: eg. Sony 300 f2.8 GM, super light, super sharp, autofocus and stabilization: handheld birding instead of tripod/monopod base is possible now
Gemini 3.5 flash traces on Pencil Puzzle Bench are VERY interesting! They look so much closer to what humans do than anything I've seen (eg. gpt 5.5 just often 1-shots answers with lots of thinking)
Gemini 3.5 Flash seems to do the same style "step by step" that humans do...
Interestingly, I also see a pattern where I think they were clearly heavily tuned on sudoku / 9x9 grid puzzles.
On all the ones Gemini 3.5 flash gets wrong, it tries to 1-shot a 9x9 answer before iterating.
(Notice the flash of random moves on 9x9 top left grid in these)
Reward hacking is the hardest problem in RL.
We design settings where hacking is predictable, and find patterns between task difficulty and hack frequency.
These runs are highly efficient, using <$1 in compute. We’re launching Sprints to allow everyone to join this effort.
@nikitabier American candy: eg. Recees peanut butter cups that are individually wrapped (about the same size as standard omiyage, but new unique flavor)
Super cool to see TRM approaches on PencilPuzzle Bench!
Very cool to see how effective the proabalistic noise is for helping TRM out of bad basins / fixed-points
Great work by @__aminima__!
Pencil Puzzle Bench (PPBench) puzzles: 62.6% (TRM) to 91.2% (PTRM), beating an ensemble of 7 frontier LLMs at less than 0.0001x the cost
Sudoku-Extreme: 87.4% (TRM) to 98.75% (PTRM)
Smaller but positive gains on Maze-Hard and ARC-AGI-2
🧵6/N