Horizontal scaling is more than a load balancer.
Here are 2 more ways to scale Horizontally.
With horizontal duplication, you duplicate part of your system to handle more workloads and distribute the work between these duplicates.
The most obvious way of horizontal duplication is using a load balancer. They:
• Distribute the work.
• Detect when a node is unavailable and remove it from the load balancer pool.
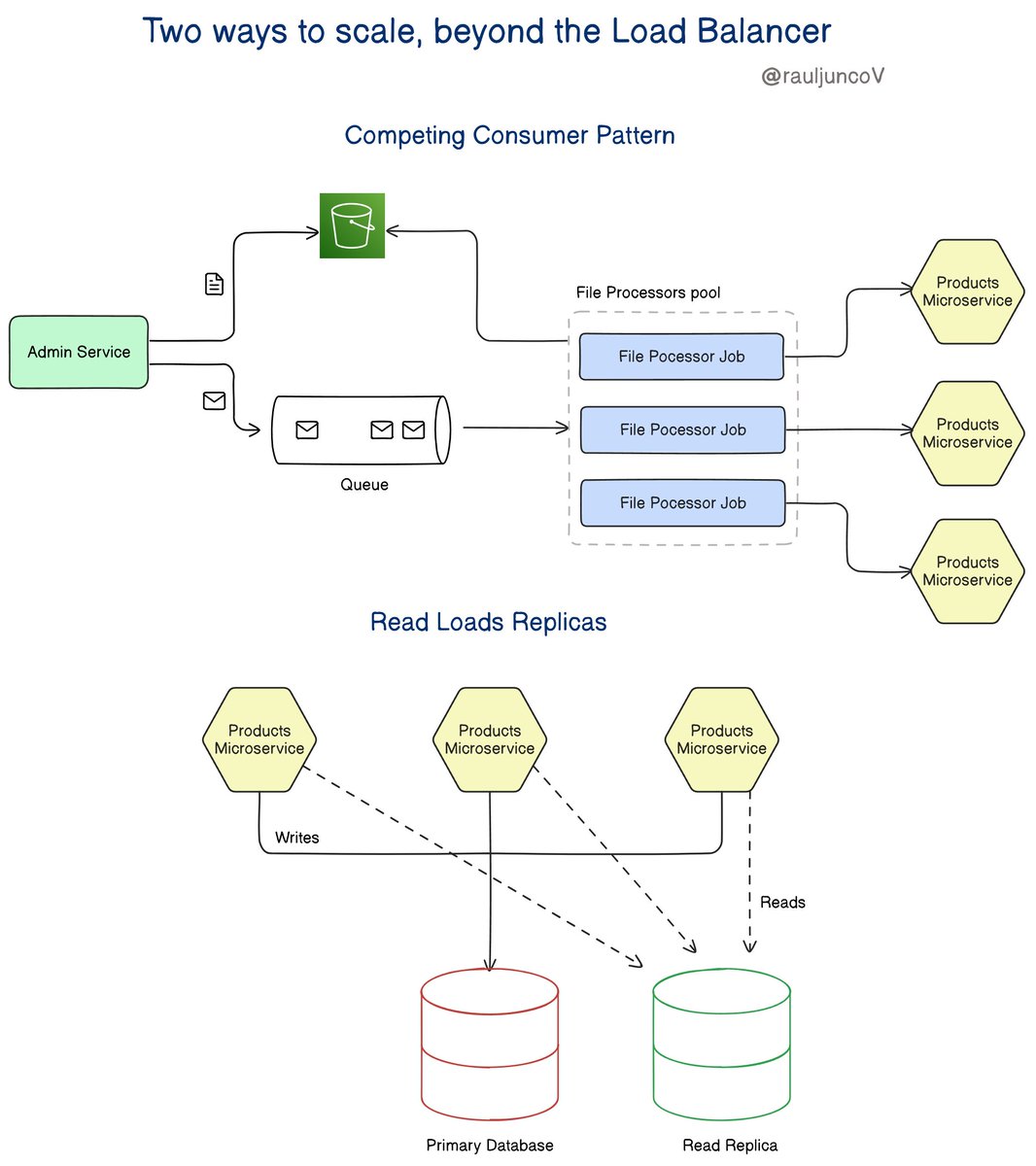
1. Competing Consumer Pattern
The idea of this pattern is to distribute the load to achieve more throughput.
This is ideal when you have job processors. For example, if your system needs to allow users to import and process large files.
You place each uploaded file in a queue; many consumers would compete to pick up and process them.
2. Read Loads Replicas
To reduce the reads on the primary database, you create a Read Replicas.
This works well if a lot of the load on the main system is read-heavy.
For example, in an e-commerce system.
The primary database handles all write operations, while read replicas handle read-heavy operations, like fetching product details or user order history.
Horizontal duplication is somewhat straightforward.
If vertical scaling isn't available, this form of scaling is typically the next thing I'd look at.
Assuming you can split the work across the duplicates, it's an elegant way of spreading the load and reducing resource contention.
With a caveat that requires more infrastructure, of course, costs more money.
Have you done any of these?
At 5000 tons, Starship is the largest flying object ever made. Thrust is more than double the Saturn V moon rocket.
It is the first spaceship design capable of making life multiplanetary.
Goal of the next mission is to make it through the meteorically extreme heat of reentry.
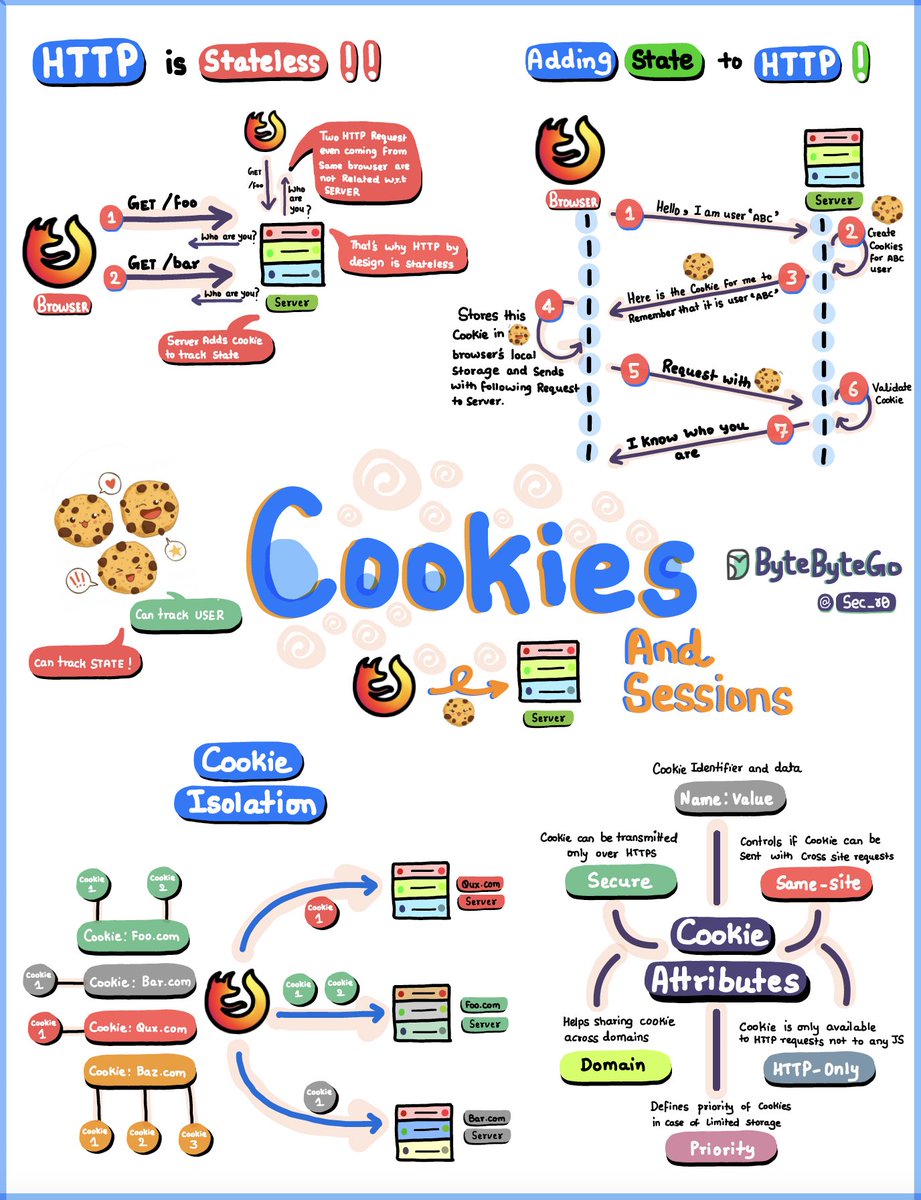
Cookie Basics 🍪
At its core, HTTP is stateless - each request/response cycle stands on its own, with the server forgetting everything after responding. But often we need to remember things between requests, like user logins or shopping carts. That's where cookies come in.
Cookies are tiny text files stored in your browser. When a server wants to remember something, it sends a "Set-Cookie" header telling your browser to create a cookie. From then on, your browser sends that cookie data back with each request to the server, allowing it to "remember" you.
But it goes further - cookies enable sessions, which are like personal data stores on the server tied to your specific interactions. The server gives you a unique "session ID" cookie, and when you send it back, the server recognizes you and accesses your session data.
There are some security and privacy controls baked in. Same-site cookies only get sent to the originating site to prevent cross-site attacks. Cookies are also isolated by domain and path to limit access. Secure cookies only transmit over encrypted HTTPS, while HttpOnly cookies are hidden from browser JavaScript code to stop cross-site scripting.
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/6j06DUIbVn
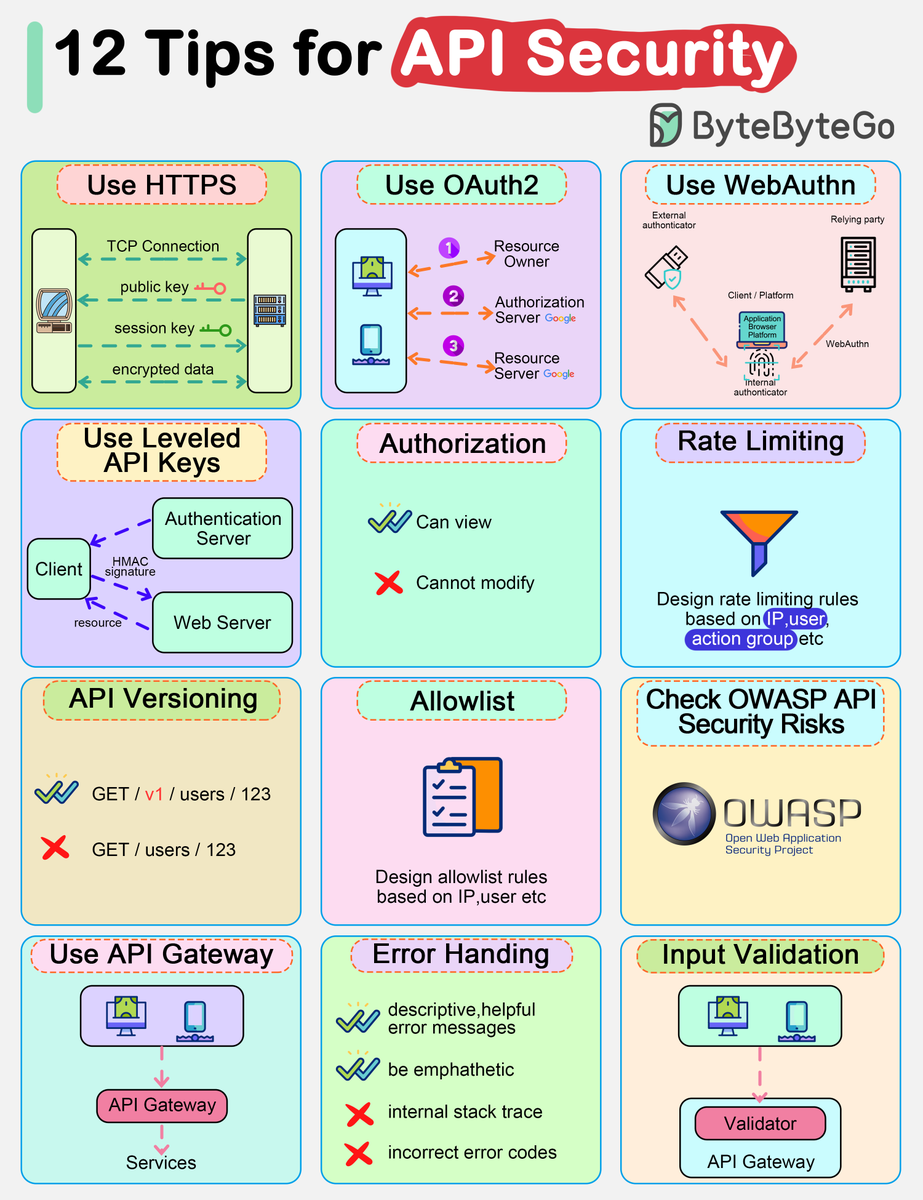
Top 12 Tips for API Security
- Use HTTPS
- Use OAuth2
- Use WebAuthn
- Use Leveled API Keys
- Authorization
- Rate Limiting
- API Versioning
- Whitelisting
- Check OWASP API Security Risks
- Use API Gateway
- Error Handling
- Input Validation
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/kNfv0DVDdf
How do we design effective and safe APIs?
The diagram below shows typical API designs with a shopping cart example.
Note that API design is not just URL path design. Most of the time, we need to choose the proper resource names, identifiers, and path patterns. It is equally important to design proper HTTP header fields or to design effective rate-limiting rules within the API gateway.
Over to you: What are the most interesting APIs you’ve designed?
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/FIzCeaWsZV
10 Good Coding Principles to improve code quality.
Software development requires good system designs and coding standards. We list 10 good coding principles in the diagram below.
🔹 01 Follow Code Specifications
When we write code, it is important to follow the industry's well-established norms, like “PEP 8”, “Google Java Style”, adhering to a set of agreed-upon code specifications ensures that the quality of the code is consistent and readable.
🔹 02 Documentation and Comments
Good code should be clearly documented and commented to explain complex logic and decisions, and comments should explain why a certain approach was taken (“Why”) rather than what exactly is being done (“What”). Documentation and comments should be clear, concise, and continuously updated.
🔹 03 Robustness
Good code should be able to handle a variety of unexpected situations and inputs without crashing or producing unpredictable results. Most common approach is to catch and handle exceptions.
🔹 04 Follow the SOLID principle
“Single Responsibility”, “Open/Closed”, “Liskov Substitution”, “Interface Segregation”, and “Dependency Inversion” - these five principles (SOLID for short) are the cornerstones of writing code that scales and is easy to maintain.
🔹 05 Make Testing Easy
Testability of software is particularly important. Good code should be easy to test, both by trying to reduce the complexity of each component, and by supporting automated testing to ensure that it behaves as expected.
🔹 06 Abstraction
Abstraction requires us to extract the core logic and hide the complexity, thus making the code more flexible and generic. Good code should have a moderate level of abstraction, neither over-designed nor neglecting long-term expandability and maintainability.
🔹 07 Utilize Design Patterns, but don't over-design
Design patterns can help us solve some common problems. However, every pattern has its applicable scenarios. Overusing or misusing design patterns may make your code more complex and difficult to understand.
🔹 08 Reduce Global Dependencies
We can get bogged down in dependencies and confusing state management if we use global variables and instances. Good code should rely on localized state and parameter passing. Functions should be side-effect free.
🔹 09 Continuous Refactoring
Good code is maintainable and extensible. Continuous refactoring reduces technical debt by identifying and fixing problems as early as possible.
🔹 10 Security is a Top Priority
Good code should avoid common security vulnerabilities.
Over to you: which one do you prefer, and with which one do you disagree?
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/uc5M7CdXXC