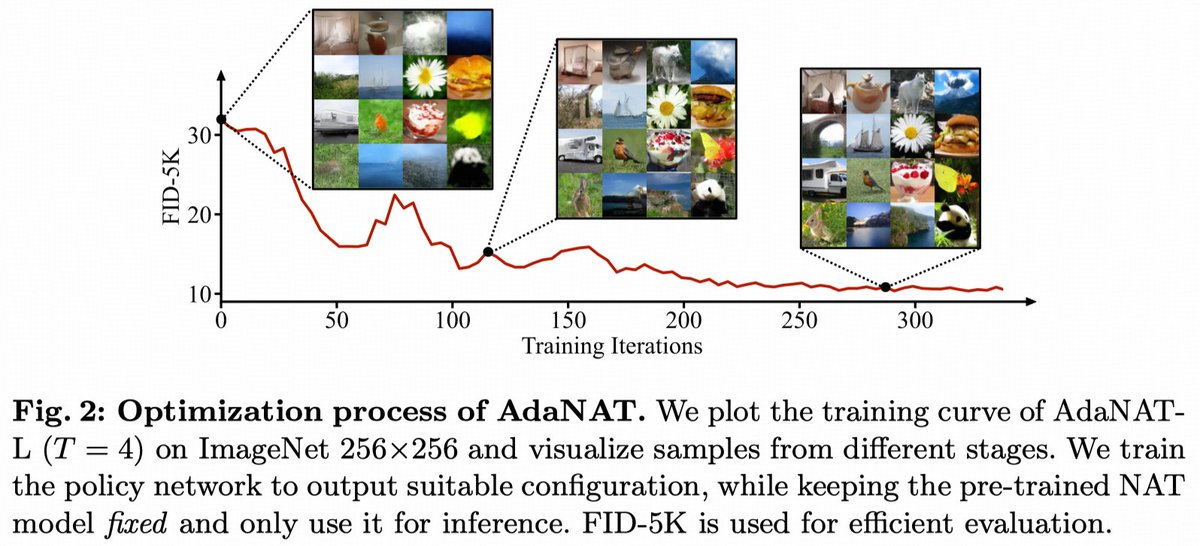
🚀 Excited to share our work on #ECCV2024: "AdaNAT: Exploring Adaptive Policy for Token-Based Image Generation".
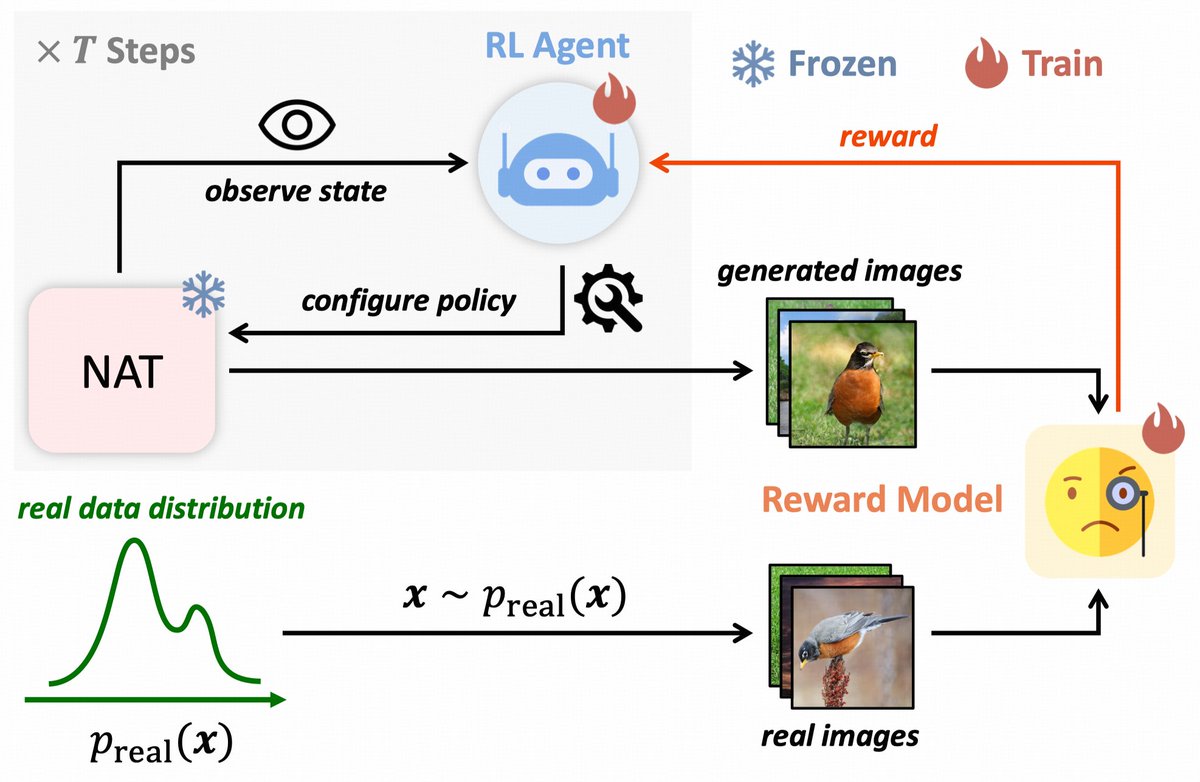
🖼️ We introduce AdaNAT, a novel approach for efficient and high-quality image generation using adaptive policies in Non-autoregressive Transformers.
🔑 Key features:
Learnable policy network for adaptive modulation of token generation
Adversarial reward model for improved quality and diversity
Significantly reduced inference time compared to diffusion models
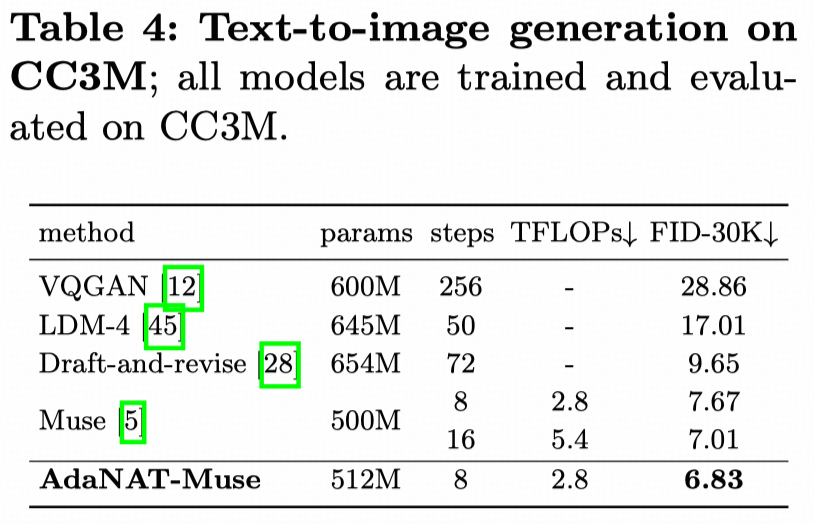
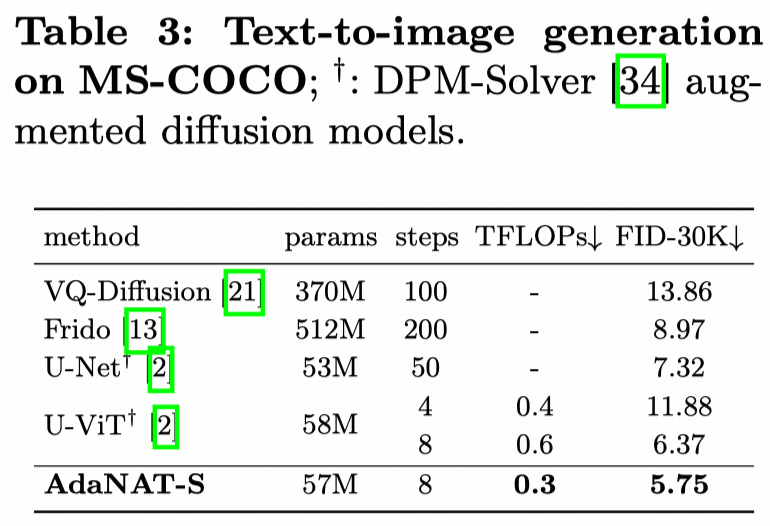
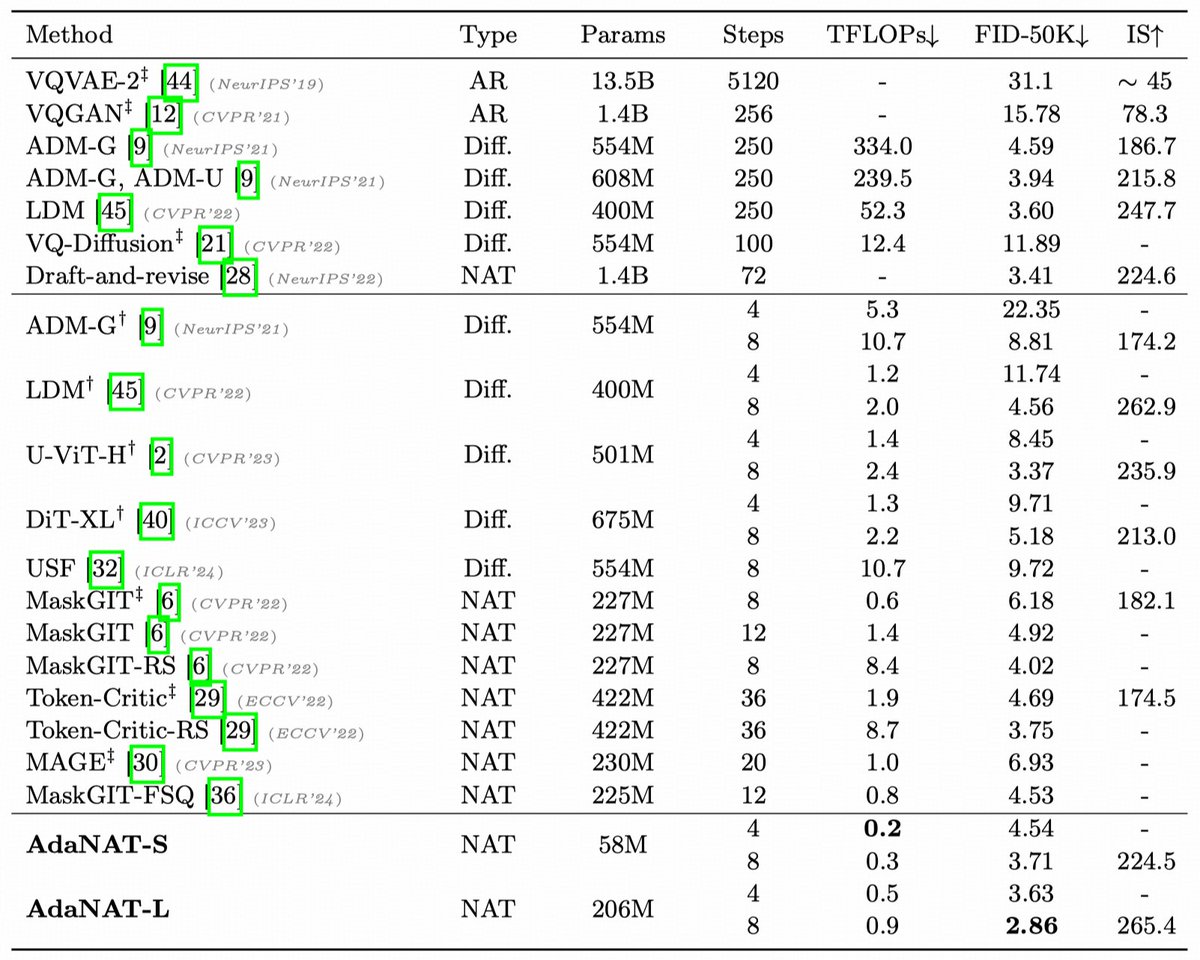
📊 Impressive results on ImageNet, MSCOCO, and CC3M datasets!
ConvLLaVA
Hierarchical Backbones as Visual Encoder for Large Multimodal Models
High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic
📢Excited to share our recent work on Large Multimodal Models: ConvLLaVA. Without the encoding multiple image patches and multiple encoders, we use a hierarchical backbone, ConvNeXt, realizing high resolution understanding.
https://t.co/eIEYDE76mV
EfficientTrain++ is accepted by TPAMI2024🤩
🔥An off-the-shelf, easy-to-implement algorithm for training foundation visual backbones efficiently!
🔥1.5−3.0× lossless training/pre-training speedup on ImageNet-1K/22K!
Paper&Code:
https://t.co/Fcs9APIQQK
https://t.co/jsddWSIqAw
EfficientTrain++ is accepted by TPAMI2024🤩
🔥An off-the-shelf, easy-to-implement algorithm for training foundation visual backbones efficiently!
🔥1.5−3.0× lossless training/pre-training speedup on ImageNet-1K/22K!
Paper&Code:
https://t.co/Fcs9APIQQK
https://t.co/jsddWSIqAw
Our recent work: Agent Attention!
[High Performance & Linear Complexity]
[Double the speed of SD and enhance generation quality, no additional fine-tuning is required]
Paper and code:
https://t.co/kejcBAtWJC
https://t.co/REDUipdUEw
https://t.co/wFAXNsY3qo
Excited to share our #NeurIPS2023 spotlight paper! 🌟 It proposes a novel offline-to-online RL algorithm, efficiently utilizing collected samples by training a family of policies offline and selecting suitable ones online. Check out our paper for details! https://t.co/bEq76wa6MA
ExpeL is now accepted at #AAAI24 ! The code and camera ready version will be updated promptly. Thanks for all the collaborators and see you in Vancouver!
Check us out at #NeurIPS2023 poster!We investigate into Q-value divergence phenomenon in offline RL and find self-excitation to be the main reason. Using layernorm in RL models can fundamentally prevent this from happening. https://t.co/Pqs7JbG77n
Our recent work: Agent Attention!
[High Performance & Linear Complexity]
[Accelerate and improve Stable Diffusion, no additional fine-tuning is required]
The paper and code have been released:
https://t.co/REDUipdUEw
https://t.co/wFAXNsY3qo







![LeapLabTHU's tweet photo. Our recent work: Agent Attention!
[High Performance & Linear Complexity]
[Double the speed of SD and enhance generation quality, no additional fine-tuning is required]
Paper and code:
https://t.co/kejcBAtWJC
https://t.co/REDUipdUEw
https://t.co/wFAXNsY3qo https://t.co/bT9bfwQoSg](https://pbs.twimg.com/media/GCmHJWBaUAArKGf.jpg)
![LeapLabTHU's tweet photo. Our recent work: Agent Attention!
[High Performance & Linear Complexity]
[Double the speed of SD and enhance generation quality, no additional fine-tuning is required]
Paper and code:
https://t.co/kejcBAtWJC
https://t.co/REDUipdUEw
https://t.co/wFAXNsY3qo https://t.co/bT9bfwQoSg](https://pbs.twimg.com/media/GCmHG9pbkAAlg8C.jpg)


![LeapLabTHU's tweet photo. Our recent work: Agent Attention!
[High Performance & Linear Complexity]
[Accelerate and improve Stable Diffusion, no additional fine-tuning is required]
The paper and code have been released:
https://t.co/REDUipdUEw
https://t.co/wFAXNsY3qo https://t.co/nxASe28ggX](https://pbs.twimg.com/media/GBiaT1kbMAAQ7fg.jpg)
![LeapLabTHU's tweet photo. Our recent work: Agent Attention!
[High Performance & Linear Complexity]
[Accelerate and improve Stable Diffusion, no additional fine-tuning is required]
The paper and code have been released:
https://t.co/REDUipdUEw
https://t.co/wFAXNsY3qo https://t.co/nxASe28ggX](https://pbs.twimg.com/media/GBiaR1sawAAC23m.jpg)




![LeapLabTHU's tweet photo. Our recent work: Agent Attention!
[High Performance & Linear Complexity]
[Double the speed of SD and enhance generation quality, no additional fine-tuning is required]
Paper and code:
https://t.co/kejcBAtWJC
https://t.co/REDUipdUEw
https://t.co/wFAXNsY3qo https://t.co/bT9bfwQoSg](https://pbs.twimg.com/media/GCmHKfRb0AAKI89.jpg)


![LeapLabTHU's tweet photo. Our recent work: Agent Attention!
[High Performance & Linear Complexity]
[Accelerate and improve Stable Diffusion, no additional fine-tuning is required]
The paper and code have been released:
https://t.co/REDUipdUEw
https://t.co/wFAXNsY3qo https://t.co/nxASe28ggX](https://pbs.twimg.com/media/GBiaVYjaoAAiTRD.jpg)






























